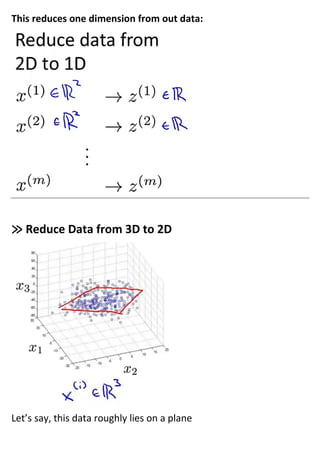
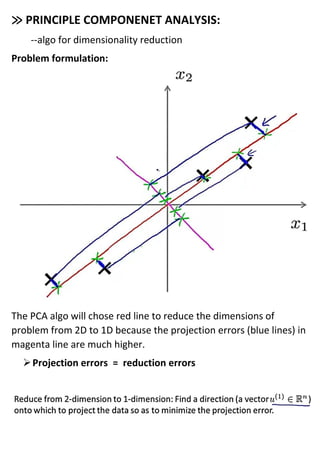
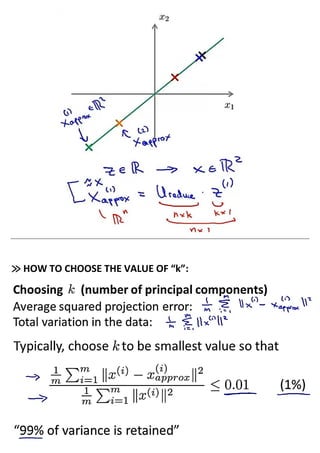
Dimensionality reduction techniques allow compressing data from a higher-dimensional space to a lower-dimensional space to speed up algorithms and visualize high-dimensional data. Principal component analysis (PCA) is an algorithm for dimensionality reduction that projects data onto dimensions of greatest variance. It works by performing singular value decomposition on the data covariance matrix to obtain principal components that best explain the data's variance and can be used to reconstruct the original data. The number of principal components used represents a tradeoff between accuracy of reconstruction and reduction of dimensions.