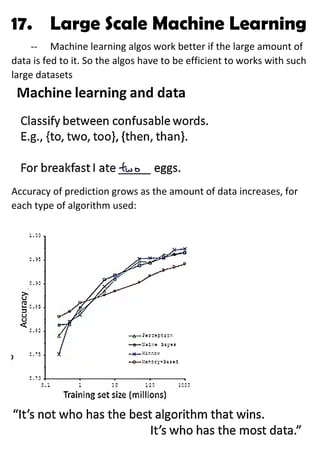
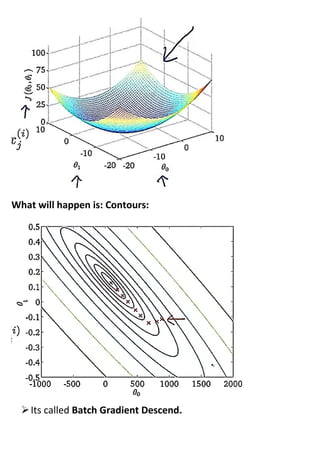
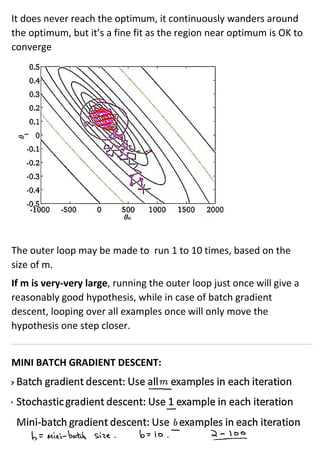
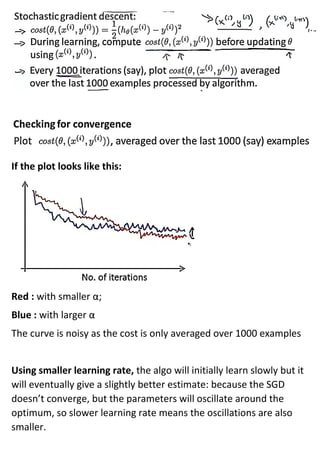
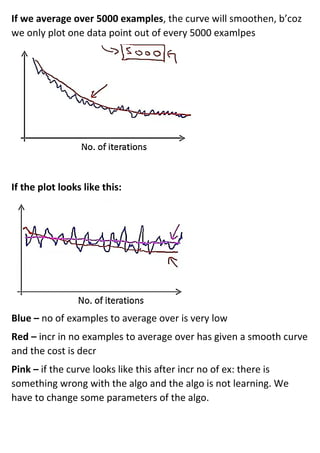
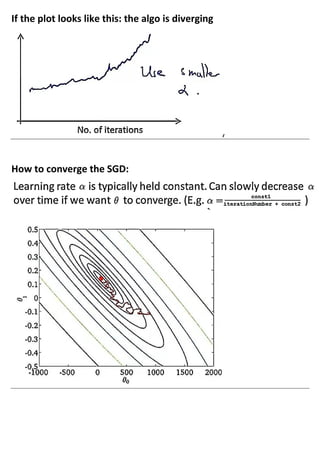
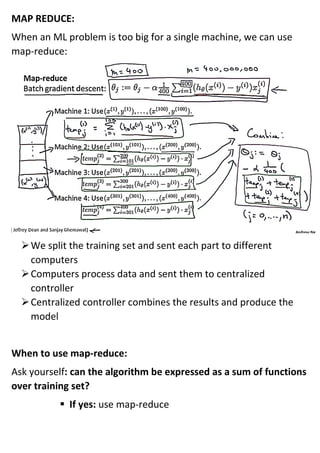
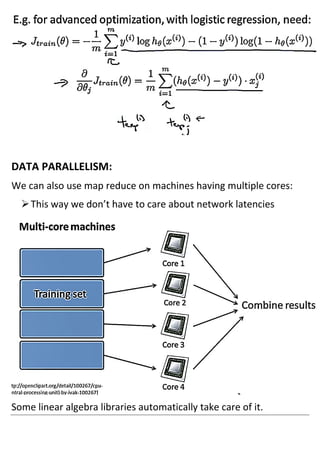
Large machine learning algorithms require processing large datasets, so they must be efficient. Accuracy improves as more data is provided for each algorithm. Stochastic gradient descent makes training less expensive than batch gradient descent by processing small batches of examples in each iteration. When problems are too large for a single machine, map-reduce can be used to split the training data across multiple computers to process in parallel and then combine results.