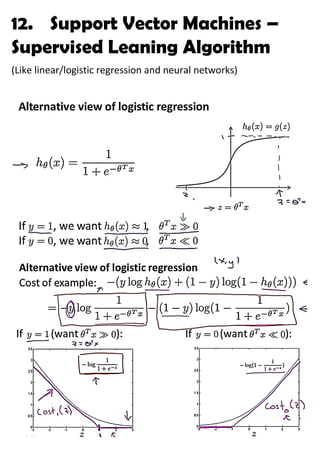
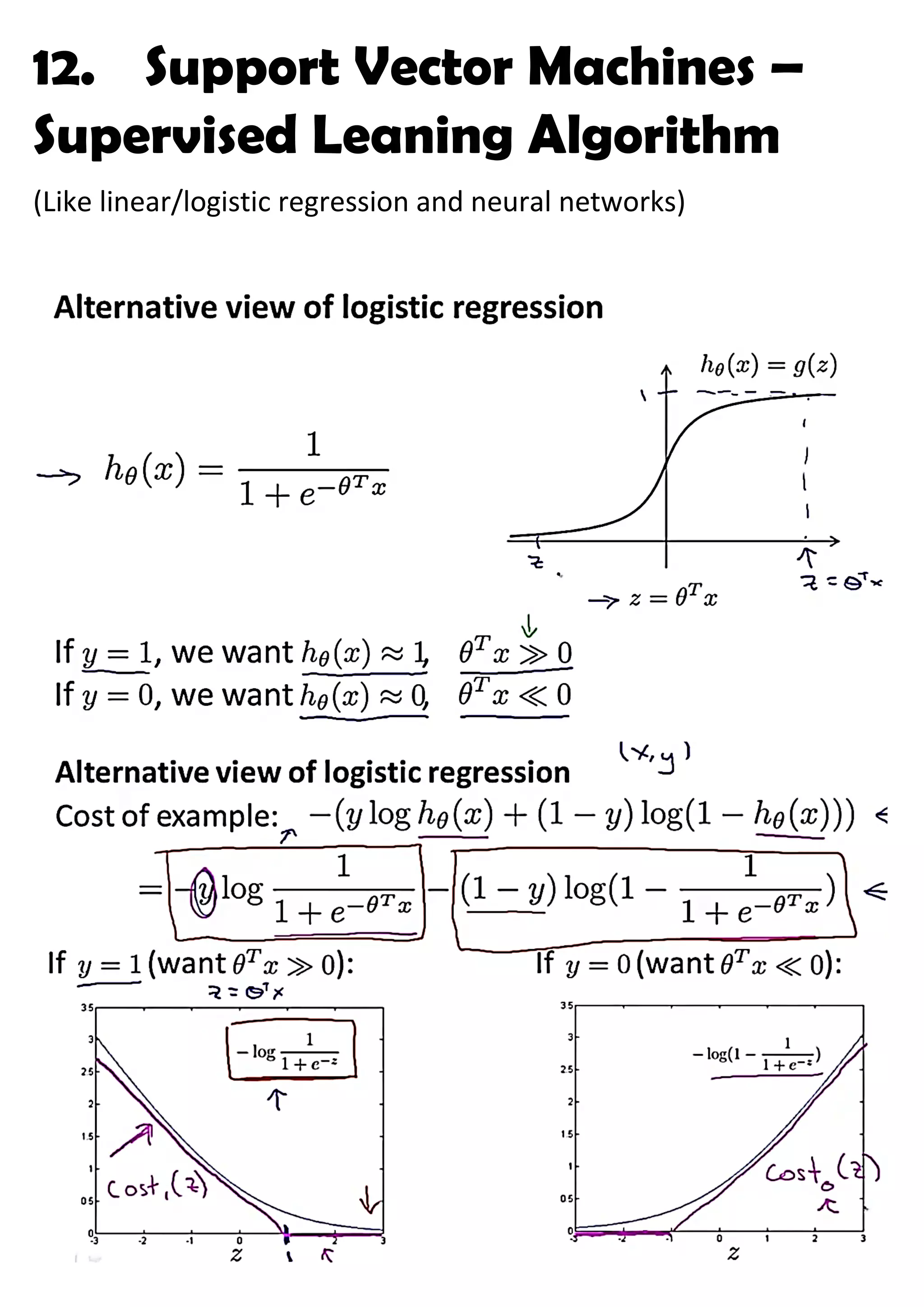
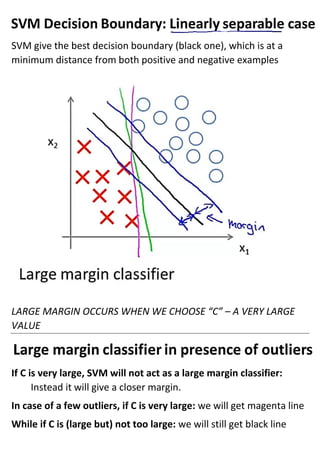
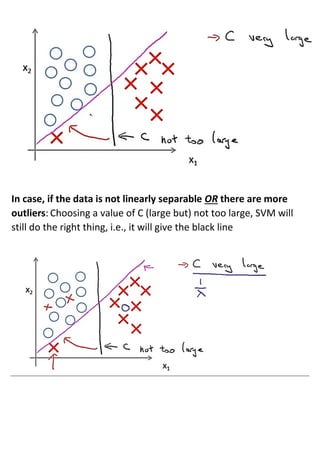
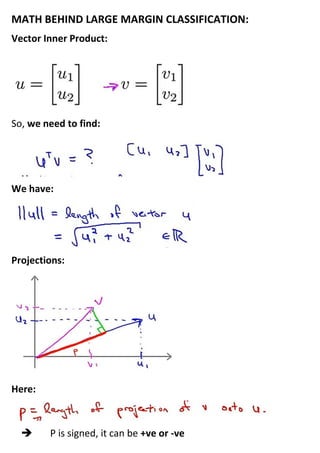
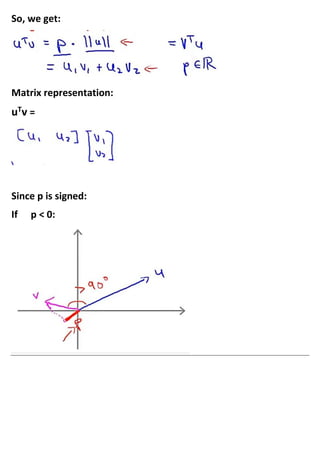
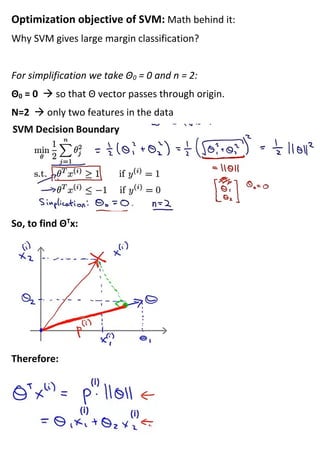
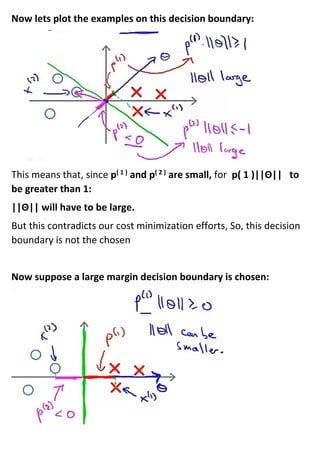
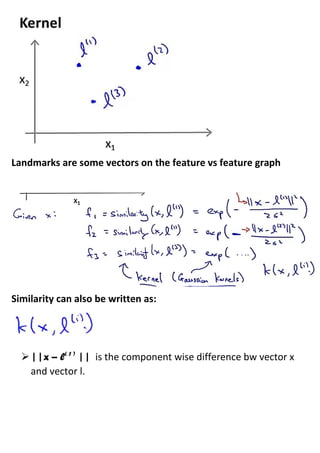
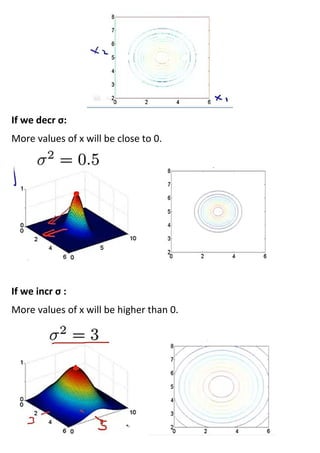
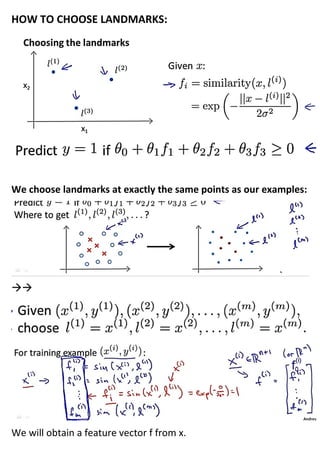
This document provides an overview of support vector machines (SVMs), a supervised machine learning algorithm. SVMs find a decision boundary that maximizes the margin between positive and negative examples. They do this by minimizing a cost function subject to constraints. Choosing a large value for the parameter C results in a large margin classifier, while a value that is large but not too large can still perform well even with outliers in the data. Kernels allow SVMs to find nonlinear decision boundaries by mapping data into higher dimensional feature spaces. The parameters C and sigma need to be chosen appropriately for good performance.