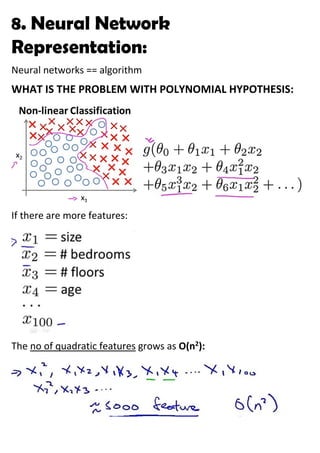
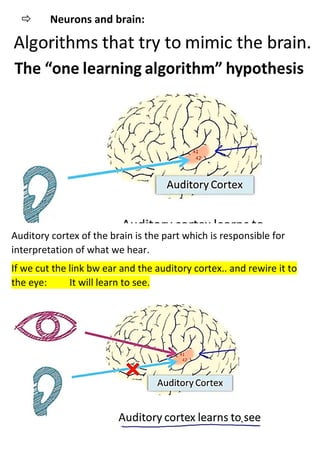
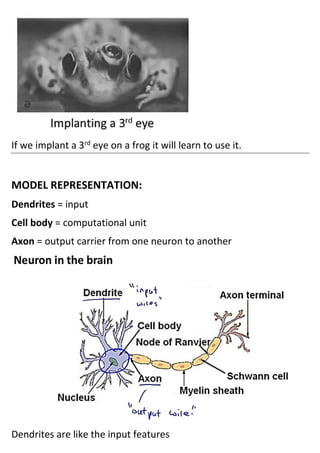
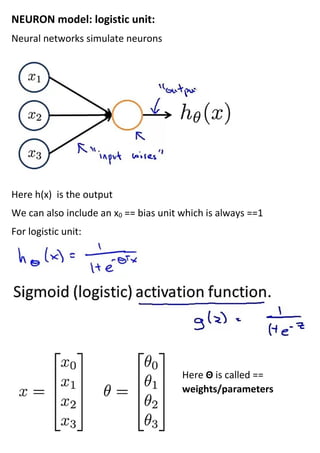
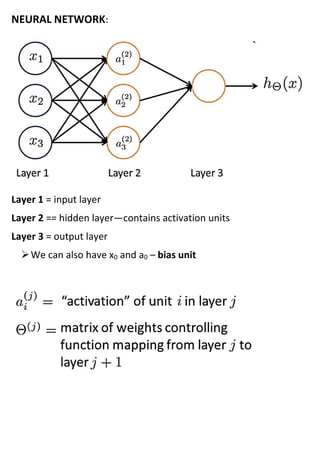
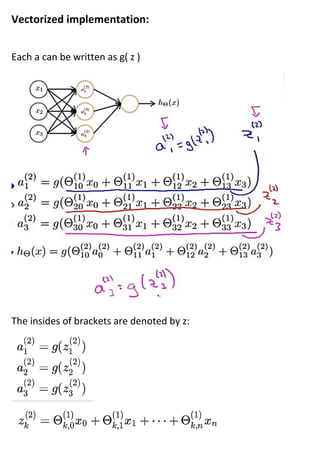
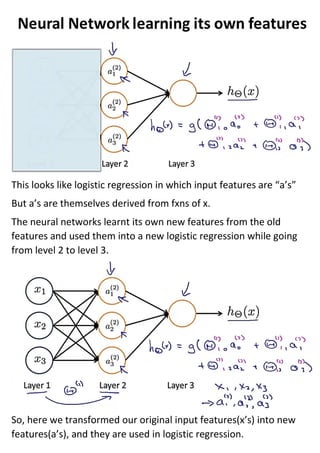
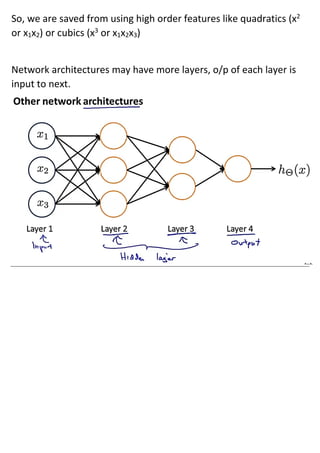
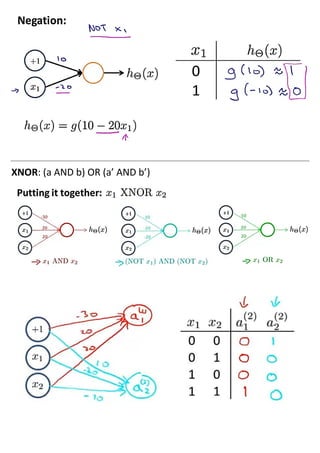
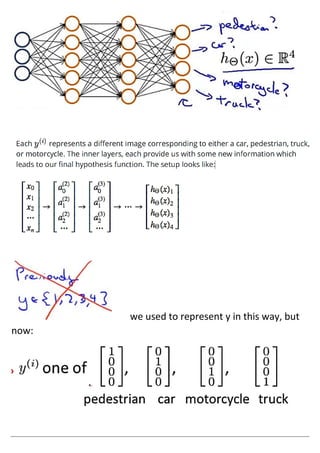
The document discusses neural networks and how they address limitations of polynomial hypotheses for classification tasks. It explains that neural networks use layers of simulated neurons to learn hierarchical representations of data. Lower layers of neurons in a neural network learn simple features that are combined in higher layers to learn more complex patterns and classify input data. This architecture allows neural networks to learn appropriate representations for tasks like computer vision without needing to explicitly define high-order polynomial features.