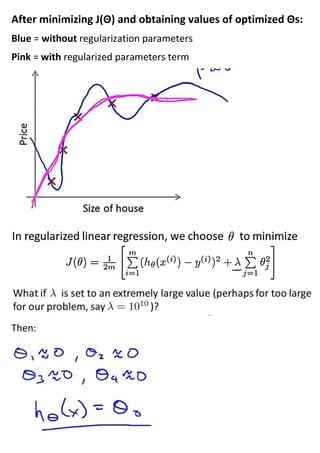
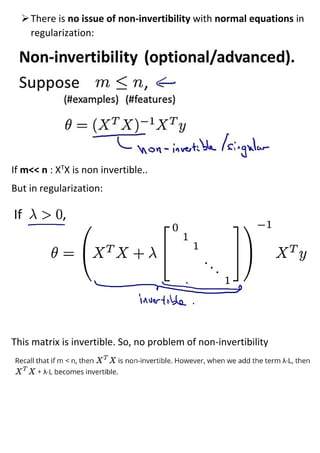
This document discusses regularization techniques to address the problem of overfitting. It introduces regularization by modifying the cost function to increase the cost of complexity terms, like higher order polynomial terms. This helps reduce overfitting by reducing the influence of unnecessary curves and angles. The regularization parameter determines how much the costs of theta parameters are increased. Examples are provided for applying regularization to linear and logistic regression using gradient descent and normal equations. Regularization helps address issues of non-invertibility that can occur with high dimensionality data.