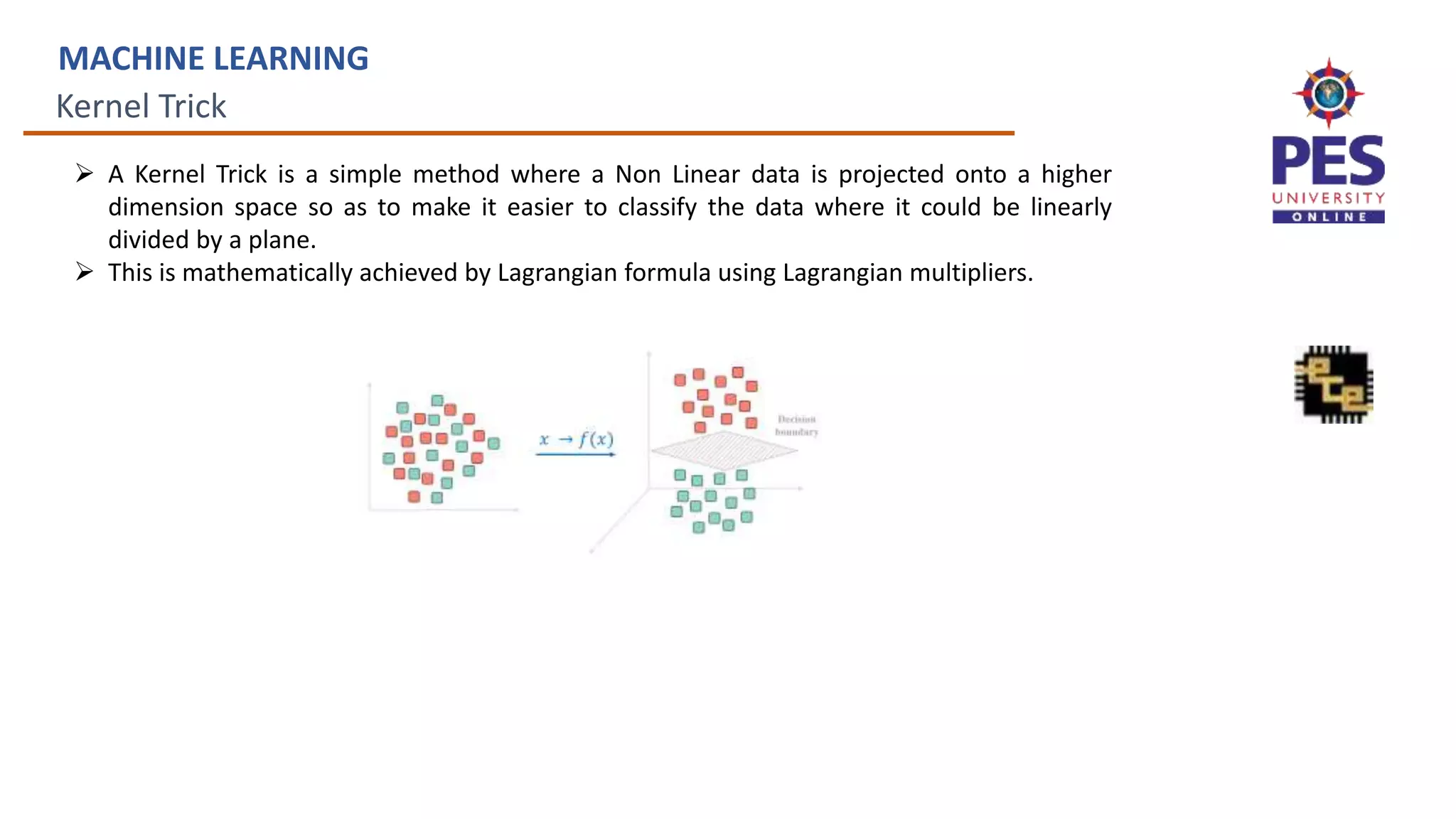
This document provides an overview of kernel machines and the kernel trick in machine learning. It discusses how the kernel trick allows projecting data into a higher dimensional space to make it linearly separable. It describes using kernels like polynomial kernels in the dual formulation to calculate dot products without explicitly performing the projection. The kernel trick avoids having to compute in the higher dimensional space, improving computational efficiency.














![Soft margin: Non separable case
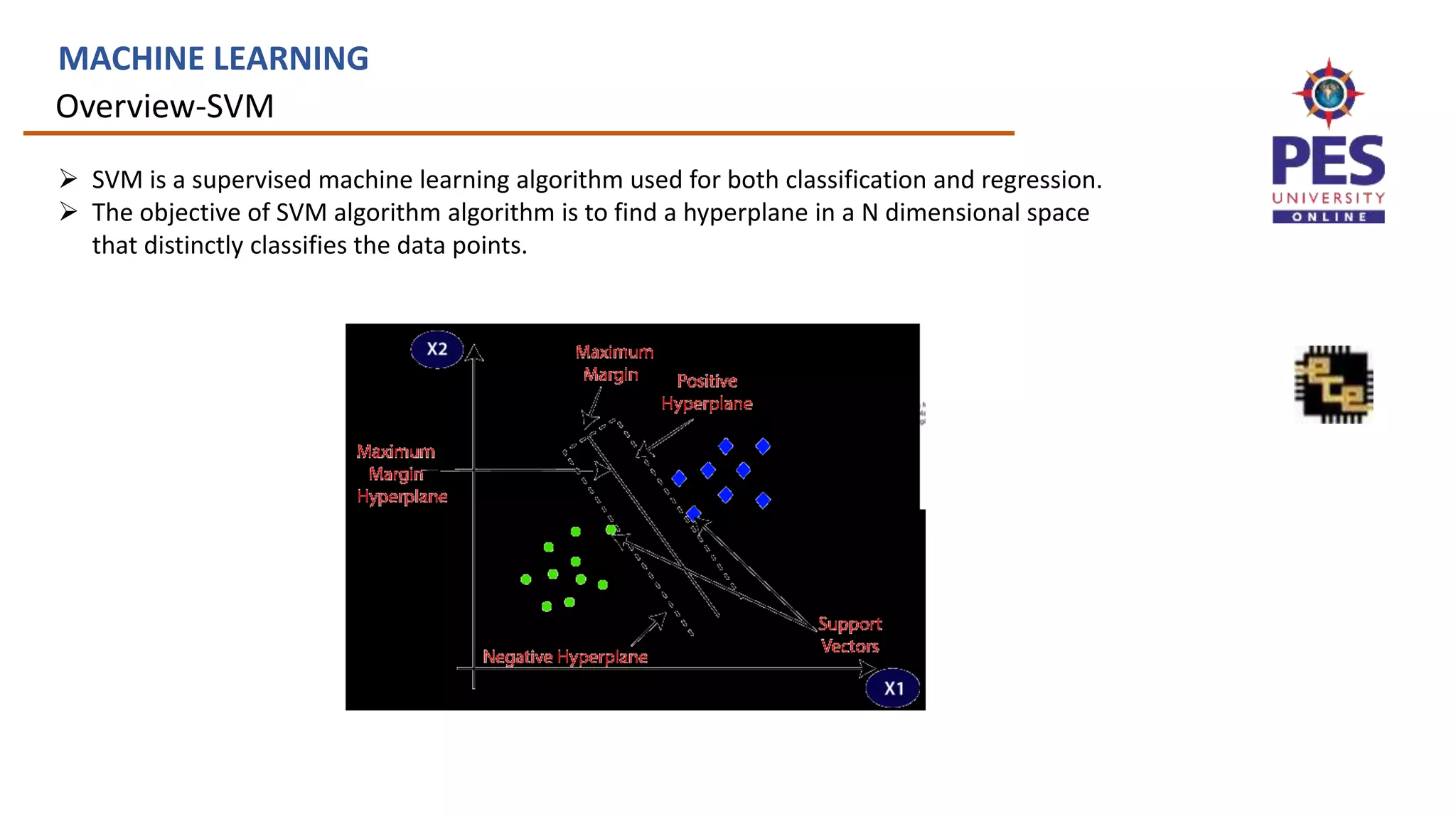
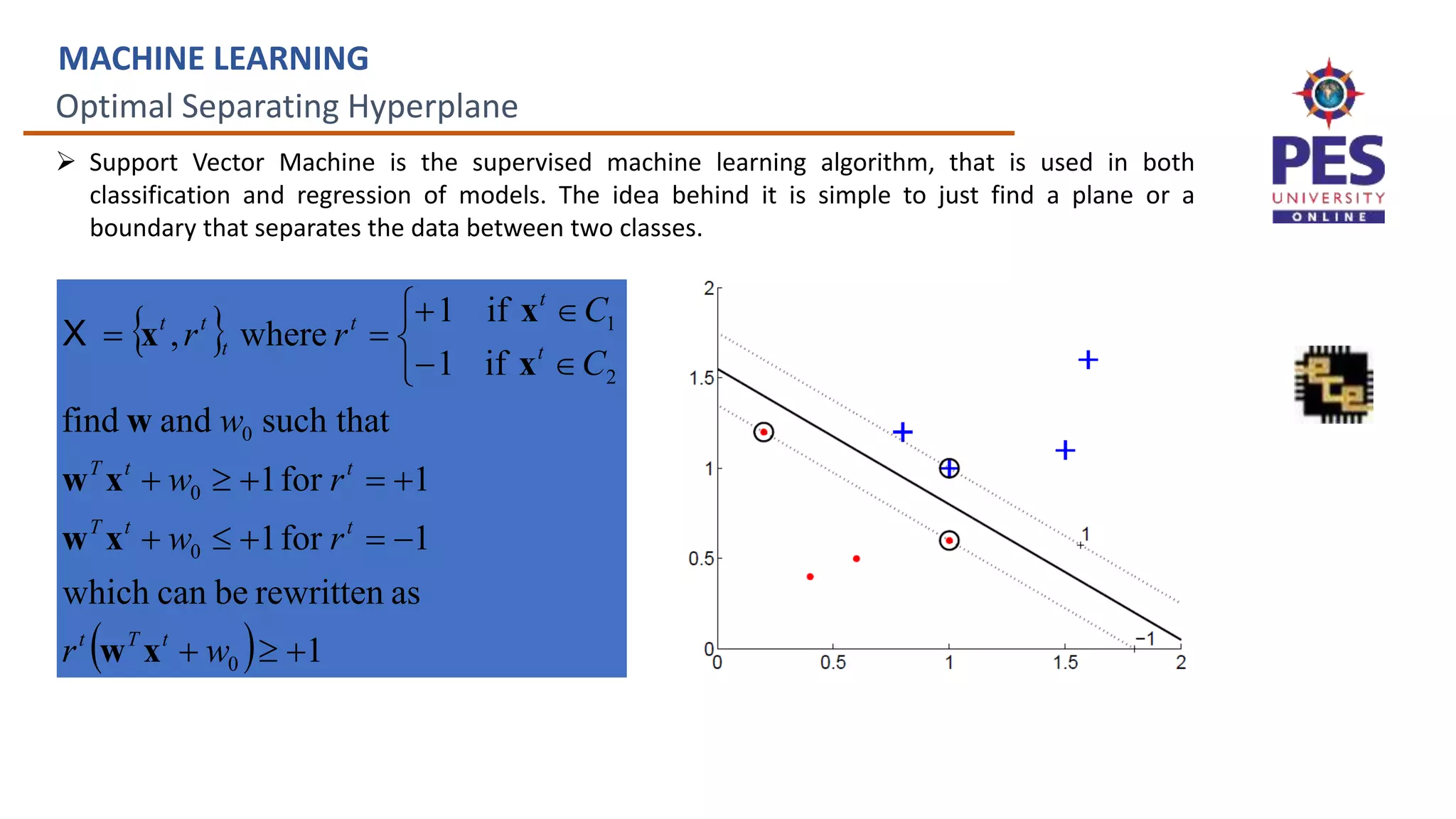
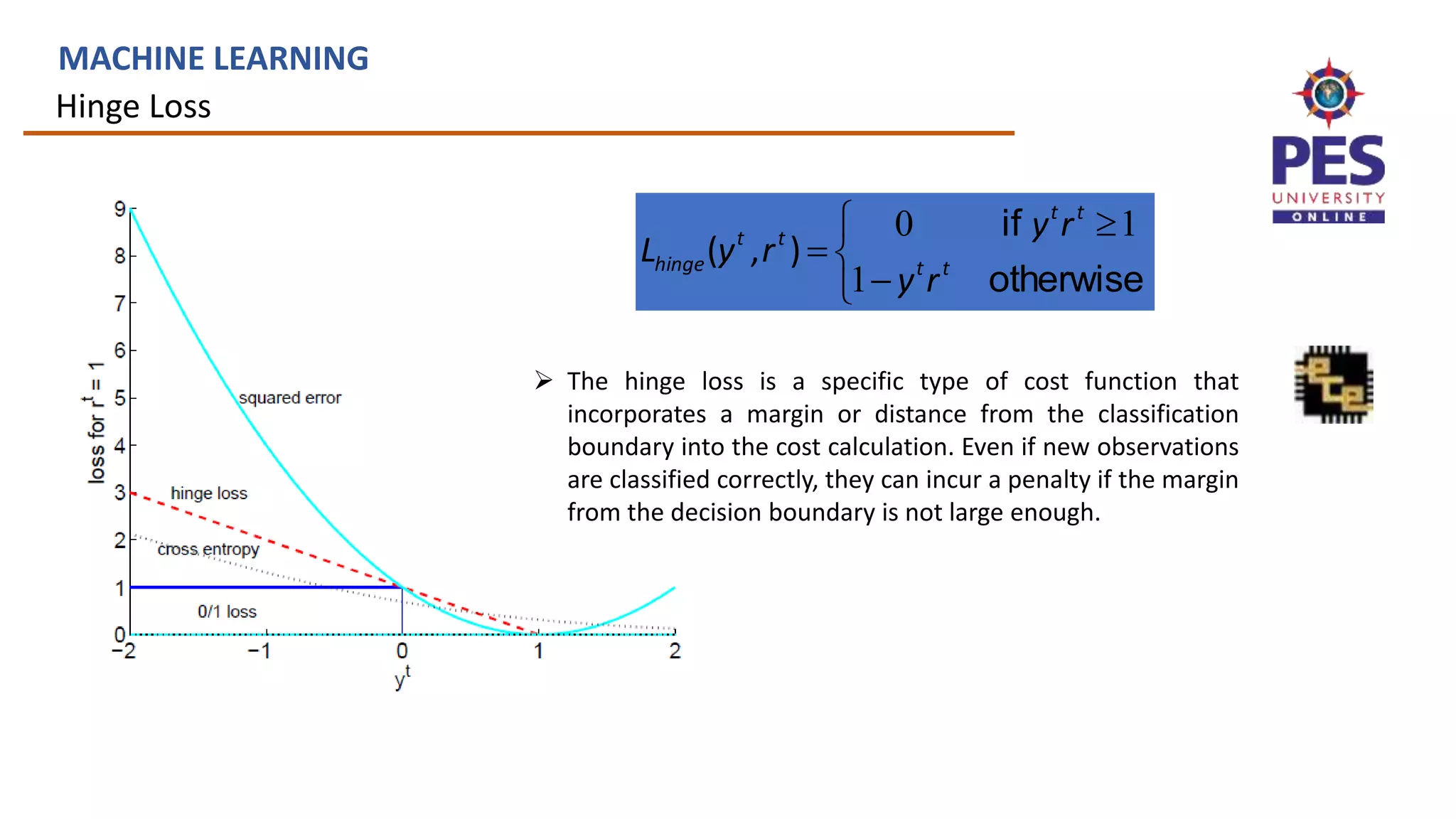
MACHINE LEARNING
α t = 0 implies samples are sufficiently present at larger distance and they vanish.
α t > 0 and they define w,
• α t < C are the ones that are on the margin, they have ξ t = 0 and satisfy r t (wTx t + w0) = 1.
• α t = C instances that are in the margin or misclassified.
The number of support vectors is an upper-bound estimate for the expected number of errors
where EN[·] denotes expectation over training sets of size N.](https://image.slidesharecdn.com/ue19ec353mlunit4slides-230705043151-ff9a8c9c/75/UE19EC353-ML-Unit4_slides-pptx-17-2048.jpg)
![n-SVM
MACHINE LEARNING
Equivalent formulation of the soft margin hyperplane that uses a parameter ν ∈ [0, 1] instead
of C . The objective function is
n
n
t
t
t
t
t
N
t s
s
T
t
s
t
s
t
d
t
t
t
T
t
t
t
N
r
x
x
r
r
L
ivenby
thedualisg
w
r
N
,
1
0
,
0
subject to
2
1
,
0
,
0
,
subject to
1
-
2
1
min
t
1
0
2
x
w
w • ρ is a new parameter that is a variable of the optimization
problem and scales the margin: The margin is now
2ρ/∥w∥.
• The nu parameter is both a lower bound for the number
of samples that are support vectors and an upper bound
for the number of samples that are on the wrong side of
the hyperplane.](https://image.slidesharecdn.com/ue19ec353mlunit4slides-230705043151-ff9a8c9c/75/UE19EC353-ML-Unit4_slides-pptx-19-2048.jpg)






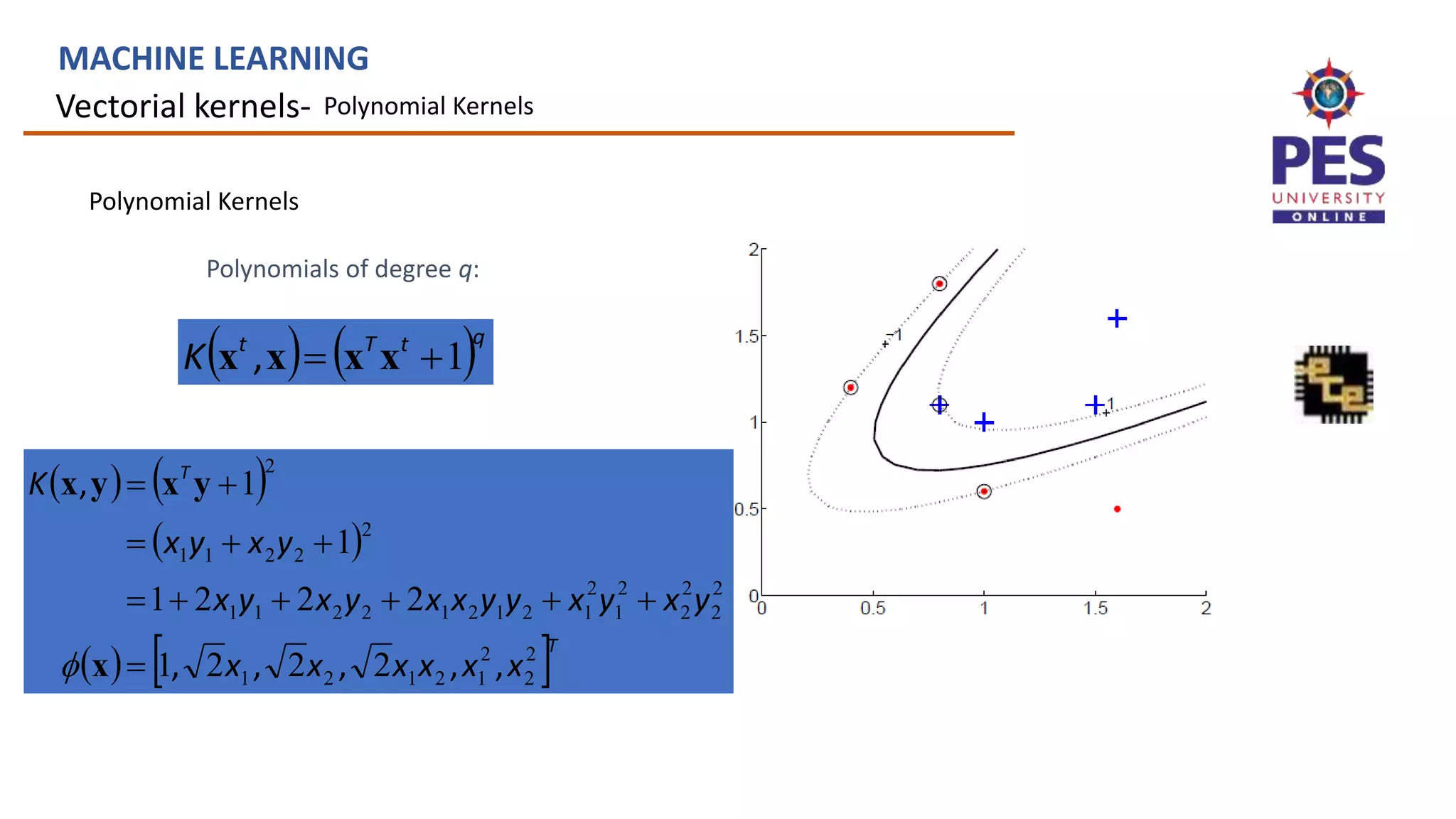
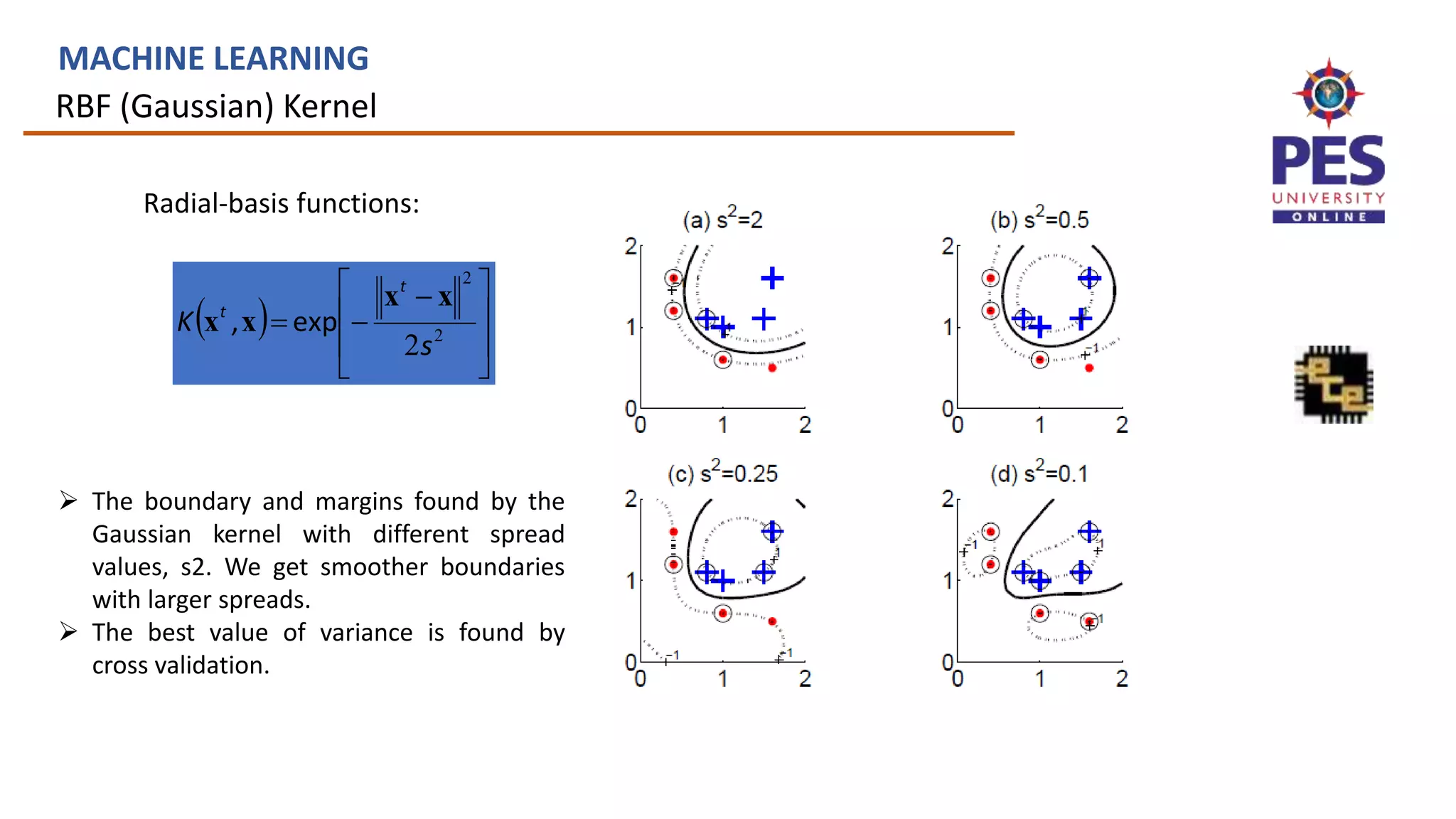

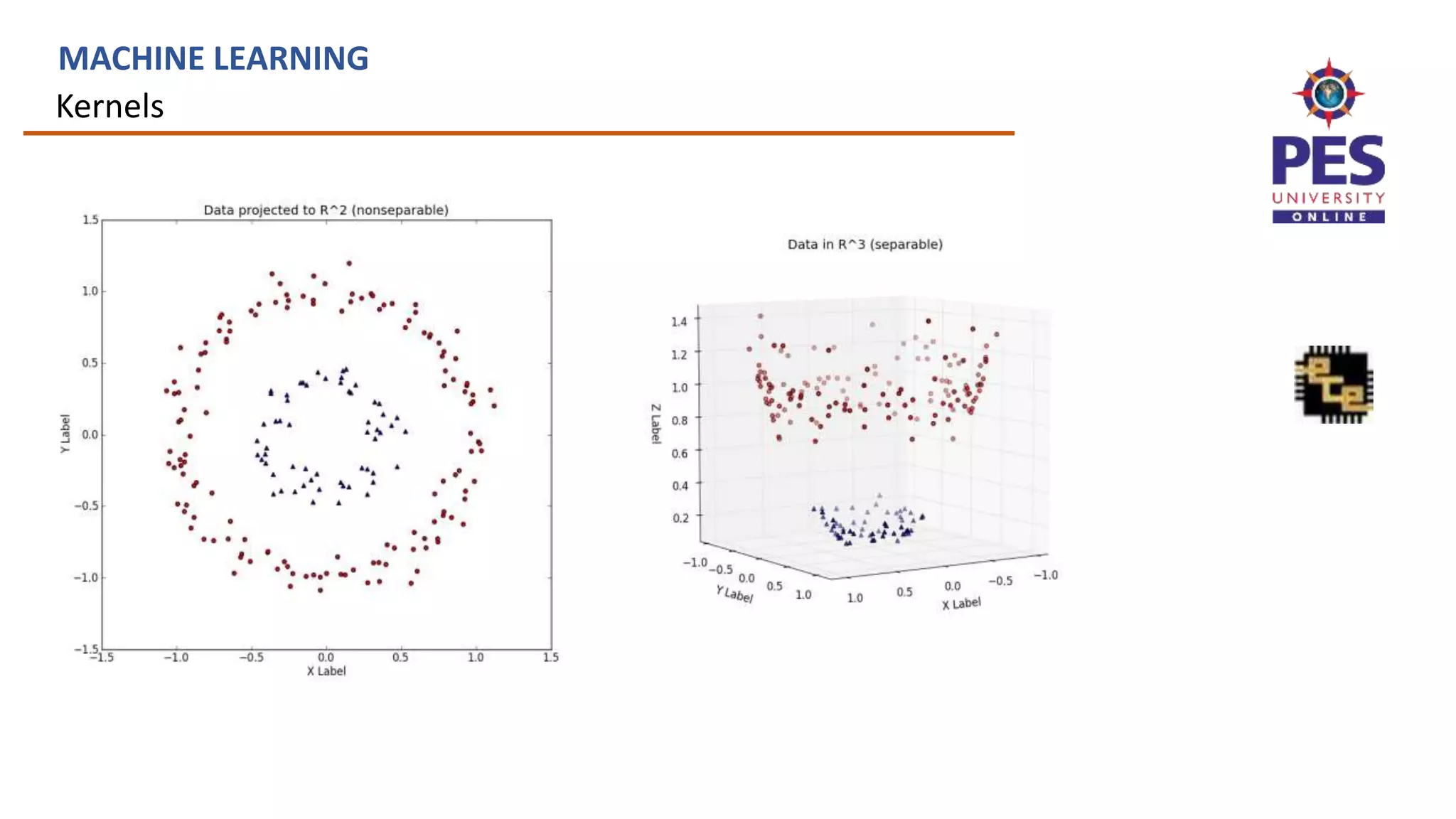
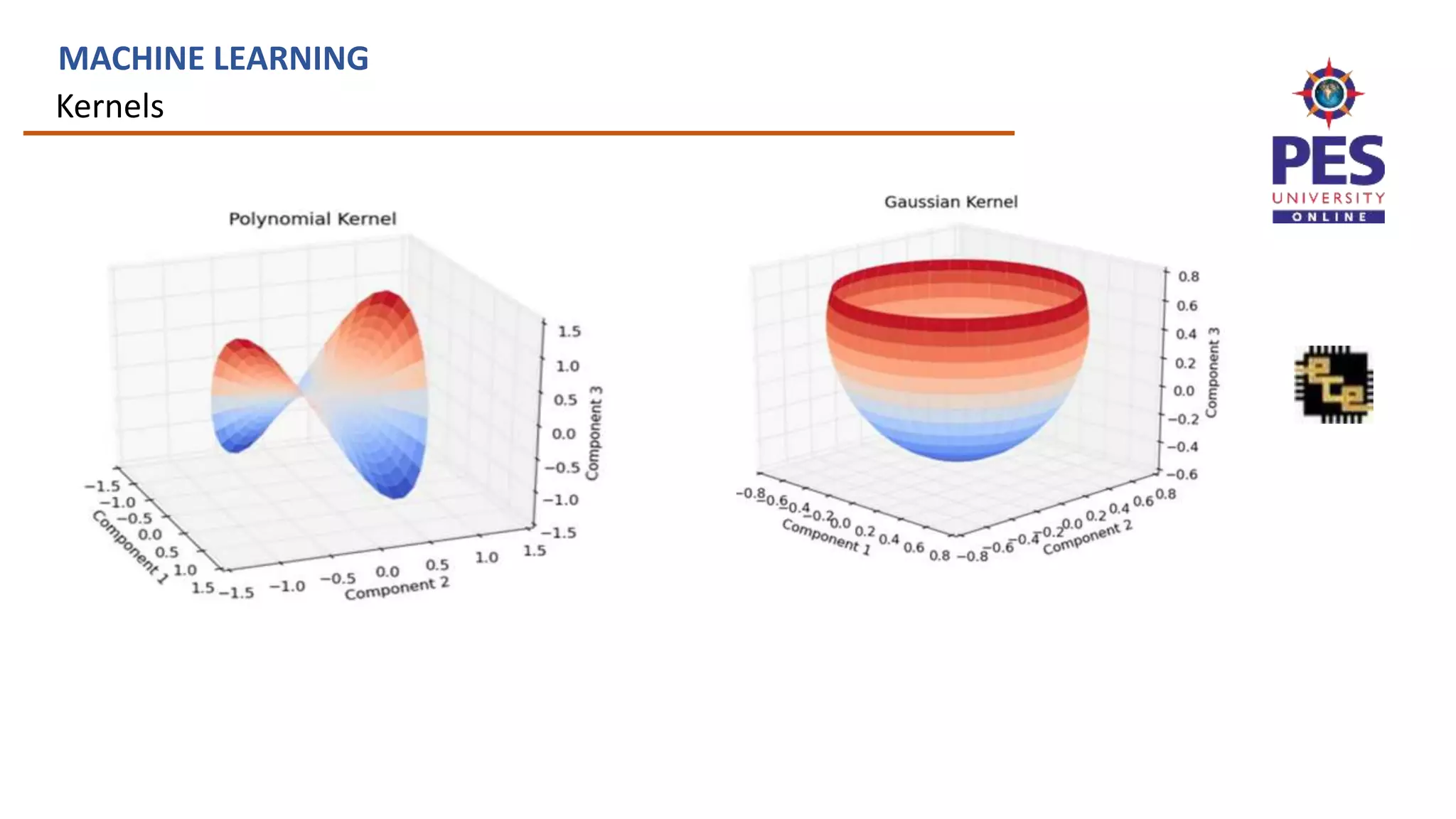
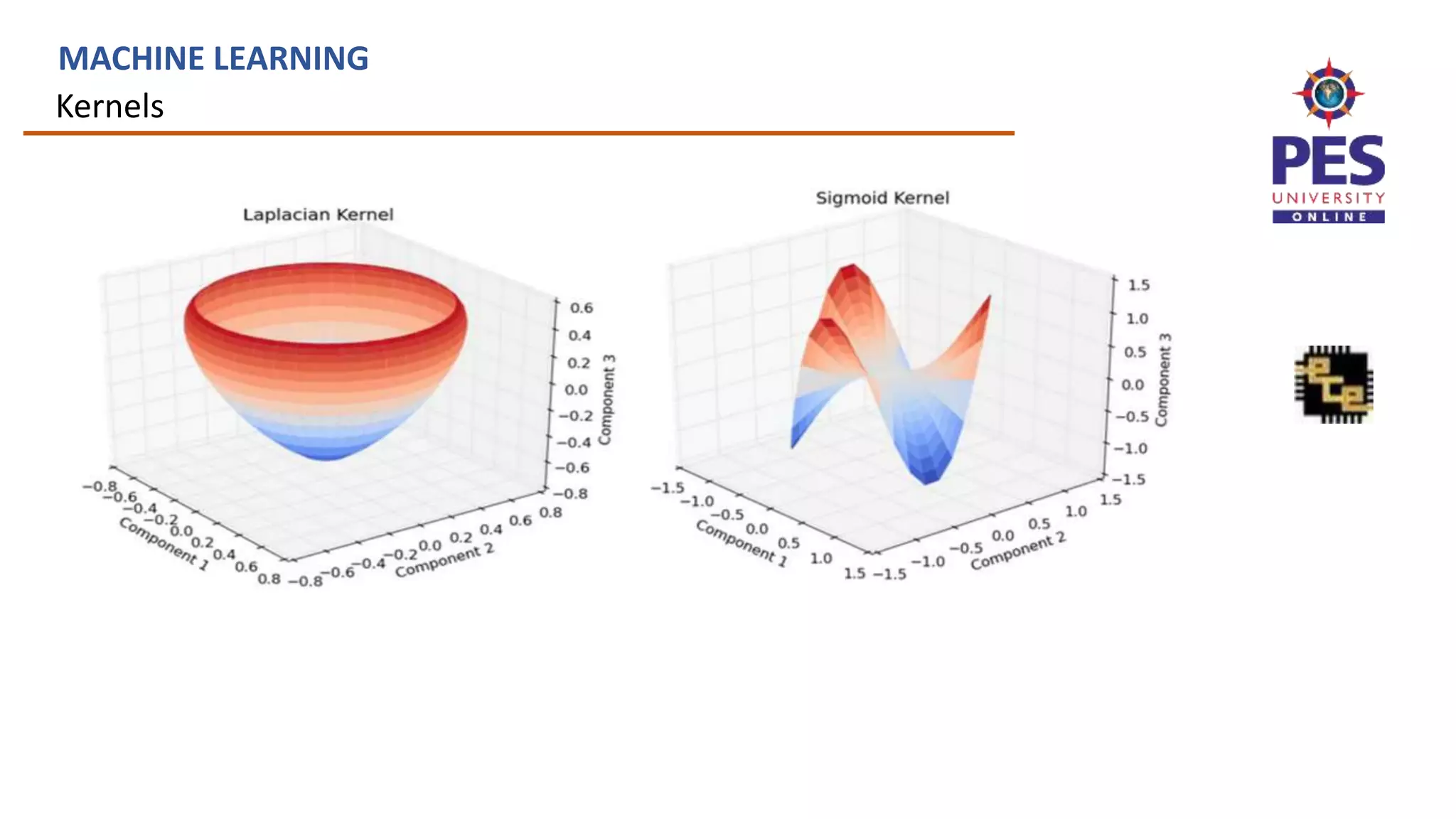


![Defining kernels
MACHINE LEARNING
Empirical kernel map: Define a set of templates mi and score function
s(x,mi)
f(xt)=[s(xt,m1), s(xt,m2),..., s(xt,mM)]
and
K(x,xt)=f (x)T f (xt)
Fisher Kernel-is a function that measures the similarity of two objects on
the basis of sets of measurements for each object and a statistical model.](https://image.slidesharecdn.com/ue19ec353mlunit4slides-230705043151-ff9a8c9c/75/UE19EC353-ML-Unit4_slides-pptx-35-2048.jpg)
![Multiple Kernel Learning
MACHINE LEARNING
It is possible to construct new kernels by combining simpler kernels. If K1(x, y)
and K2(x, y) are valid kernels and c a constant.
Fixed kernel combination:
Adaptive kernel combination:
Where
y
x
y
x
y
x
y
x
y
x
y
x
,
,
,
,
,
,
2
1
2
1
K
K
K
K
cK
K
x = [xA, xB]](https://image.slidesharecdn.com/ue19ec353mlunit4slides-230705043151-ff9a8c9c/75/UE19EC353-ML-Unit4_slides-pptx-36-2048.jpg)
































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)























