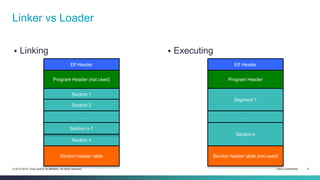
The document provides an overview of the ELF (Executable and Linkable Format) file format used by most Unix operating systems. It discusses how ELF files contain sections and segments that provide information to linkers and loaders. Specifically, it explains that sections contain code and data and are used by linkers to connect pieces at compile time, while segments define memory permissions and locations and are used by loaders to map the binary into memory at runtime. It also gives examples of common sections like .text, .data, .rodata, and describes how dynamic linking with the PLT and GOT tables allows functions to be resolved at load time.














![Segment example
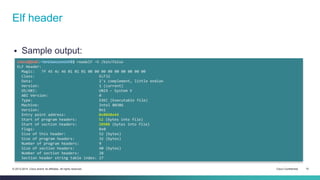
cisco@kali:~/src/seccon/ch6$ readelf -l /bin/false
Elf file type is EXEC (Executable file)
Entry point 0x8048e44
There are 9 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000034 0x08048034 0x08048034 0x00120 0x00120 R E 0x4
INTERP 0x000154 0x08048154 0x08048154 0x00013 0x00013 R 0x1
[Requesting program interpreter: /lib/ld-linux.so.2]
LOAD 0x000000 0x08048000 0x08048000 0x04658 0x04658 R E 0x1000
LOAD 0x004ef0 0x0804def0 0x0804def0 0x001cc 0x00350 RW 0x1000
DYNAMIC 0x004efc 0x0804defc 0x0804defc 0x000f0 0x000f0 RW 0x4
NOTE 0x000168 0x08048168 0x08048168 0x00044 0x00044 R 0x4
GNU_EH_FRAME 0x003d40 0x0804bd40 0x0804bd40 0x001c4 0x001c4 R 0x4
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x4
GNU_RELRO 0x004ef0 0x0804def0 0x0804def0 0x00110 0x00110 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .hash .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rel.dyn .rel.plt .init .plt .text .fini
.rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got
© 2013-2014 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 16](https://image.slidesharecdn.com/06-elfspecification-141011071503-conversion-gate01/85/06-ELF-format-knowing-your-friend-16-320.jpg)

![What goes where?
cisco@kali:~/src/seccon/ch6$ pygmentize -g ../ch4/aslr.c
#define _GNU_SOURCE /* for RTLD_NEXT */
#include <dlfcn.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *rodata = "ABCD"; // .rodata
char data[4+1] = "ABCD"; // .data
int main(int argc, char **argv) {
printf("Stack base address: %pn", argv);
char *heap = malloc(sizeof(int));
printf("Heap base address: %pn", heap);
void (*memcpy_addr)(int) = dlsym(RTLD_NEXT, "memcpy");
printf("Memcpy libc address: %pn", memcpy_addr);
unsigned int text;
__asm__("call dummy;"
"dummy: pop %%eax;"
"mov %%eax, %0;":"=r"(text));
printf("Code section address: %pn", text);
printf("Data section address: %pn", data);
printf("RO data section address: %pn", rodata);
free(heap);
}
© 2013-2014 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 18](https://image.slidesharecdn.com/06-elfspecification-141011071503-conversion-gate01/85/06-ELF-format-knowing-your-friend-18-320.jpg)
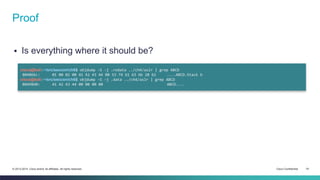




![PLT stub
Our code jumps at a fixed offset into the PLT
There’s some magic code there, let’s trace it:
gdb$ x/3i 0x80482f0
0x80482f0 <puts@plt>: jmp DWORD PTR ds:0x8049654
0x80482f6 <puts@plt+6>: push 0x0
0x80482fb <puts@plt+11>: jmp 0x80482e0
gdb$ x/w 0x8049654
0x8049654 <puts@got.plt>: 0x080482f6
gdb$ x/10i 0x80482e0
0x80482e0: push DWORD PTR ds:0x804964c
0x80482e6: jmp DWORD PTR ds:0x8049650
0x80482ec: add BYTE PTR [eax],al
0x80482ee: add BYTE PTR [eax],al
0x80482f0 <puts@plt>: jmp DWORD PTR ds:0x8049654
0x80482f6 <puts@plt+6>: push 0x0
0x80482fb <puts@plt+11>: jmp 0x80482e0
gdb$ x/x 0x804964c
0x804964c <_GLOBAL_OFFSET_TABLE_+4>: 0xb7fff908
gdb$ x/x 0x8049650
0x8049650 <_GLOBAL_OFFSET_TABLE_+8>: 0xb7ff59b0
gdb$ info files
0xb7fe2820 - 0xb7ff905f is .text in /lib/ld-linux.so.2
© 2013-2014 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 24](https://image.slidesharecdn.com/06-elfspecification-141011071503-conversion-gate01/85/06-ELF-format-knowing-your-friend-24-320.jpg)
![What’s happening
PLT entry jumps to the GOT, then jumps back to itself (next instruction)
It pushes a value on the stack
It jumps back to PLT[0]
PLT[0] jumps into the dynamic linker
Dynamic linker resolves the libc address
Linker updates the GOT entry with the resolved address, using the
offset pushed in the PLT
Linker jumps to libc address
© 2013-2014 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 25](https://image.slidesharecdn.com/06-elfspecification-141011071503-conversion-gate01/85/06-ELF-format-knowing-your-friend-25-320.jpg)





![Vulnerable program (ASLR + DEP)
The usual, but with a piece of dead code
cisco@kali:~/src/seccon/ch6$ pygmentize -g ch6.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int does_nothing() {
system("/bin/sh");
}
int vuln(const char *stuff) {
char buf[0x64] = {0};
strcpy(buf, stuff);
return 1;
}
int main(int argc, char **argv) {
vuln(argv[1]);
return 0;
}
© 2013-2014 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 32](https://image.slidesharecdn.com/06-elfspecification-141011071503-conversion-gate01/85/06-ELF-format-knowing-your-friend-32-320.jpg)


















































![Sergi Álvarez & Roi Martín - Radare2 Preview [RootedCON 2010]](https://cdn.slidesharecdn.com/ss_thumbnails/sergialvarezroimartin-radare2preview-100328043046-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)


















