The document outlines the course CS354: Operating Systems at Purdue University, including the required textbook and recommended readings. It details course organization, grading criteria, and key topics such as memory management, processes, and threading. Additionally, it covers program structure, building and loading executables, and the usage of pointers in C programming.




![PSOs There is no PSO the first week. The projects will be explained in the PSOs. E-mail questions to [email_address] TAs office hours will be posted in the web page.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-4-320.jpg)









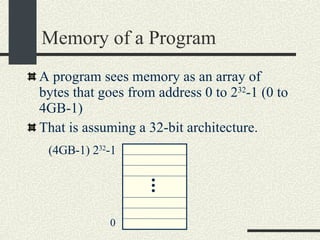



![Example Program hello.c int a = 5; // Stored in data section int b[20]; // Stored in bss int main() { // Stored in text int x; // Stored in stack int *p =(int*) malloc(sizeof(int)); //In heap }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-18-320.jpg)





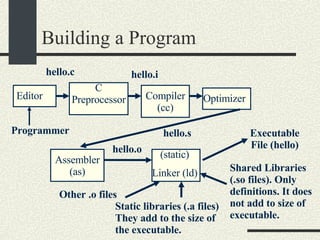



![After compiling “ gcc -c hello.c” generates hello.o hello.o has undefined symbols, like the printf function call that we don’t know where it is placed. The main function already has a value relative to the object file hello.o csh> nm -xv hello.o hello.o: [Index] Value Size Type Bind Other Shndx Name [1] |0x00000000|0x00000000|FILE |LOCL |0 |ABS |hello.c [2] |0x00000000|0x00000000|NOTY |LOCL |0 |2 |gcc2_compiled [3] |0x00000000|0x00000000|SECT |LOCL |0 |2 | [4] |0x00000000|0x00000000|SECT |LOCL |0 |3 | [5] |0x00000000|0x00000000|NOTY |GLOB |0 |UNDEF |printf [6] |0x00000000|0x0000001c|FUNC |GLOB |0 |2 |main](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-28-320.jpg)
![After linking “ gcc –o hello hello.c” generates the hello executable Printf does not have a value yet until the program is loaded csh> nm hello [Index] Value Size Type Bind Other Shndx Name [29] |0x00010000|0x00000000|OBJT |LOCL |0 |1 |_START_ [65] |0x0001042c|0x00000074|FUNC |GLOB |0 |9 |_start [43] |0x00010564|0x00000000|FUNC |LOCL |0 |9 |fini_dummy [60] |0x000105c4|0x0000001c|FUNC |GLOB |0 |9 |main [71] |0x000206d8|0x00000000|FUNC |GLOB |0 |UNDEF |atexit [72] |0x000206f0|0x00000000|FUNC |GLOB |0 |UNDEF |_exit [67] |0x00020714|0x00000000|FUNC |GLOB |0 |UNDEF |printf](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-29-320.jpg)


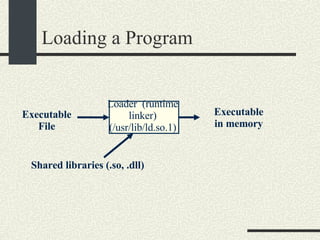



![Ways to get a pointer value 2. Get memory address from another variable: int *p; int buff[ 30]; p = &buff[1]; *p =78; buff[0]:100: buff[1]:104: buff[29]:216: 220: P: 96: 104 78](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-36-320.jpg)



![Printing Pointers It is useful to print pointers for debugging char*i; char buff[10]; printf("ptr=%d\n", &buff[5]) Or In hexadecimal printf("ptr=0x%x\n", &buff[5]) Instead of using printf, I recommend to use fprintf(stderr, …) since stderr is unbuffered and it is guaranteed to be printed on the screen.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-40-320.jpg)

![Using Pointers to Optimize Execution Assume the following function that adds the sum of integers in an array using array indexing. int sum(int * array, int n) { int s=0; for(int i=0; i<n; i++) { s+=array[i]; // Equivalent to //*(int*)((char*)array+i*sizeof(int)) } return s; }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-42-320.jpg)
![Using Pointers to Optimize Execution Now the equivalent code using pointers int sum(int* array, int n) { int s=0; int *p=&array[0]; int *pend=&array[n]; while (p < pend) { s+=*p; p++; } return s; }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-43-320.jpg)

![Array Operator Equivalence We have the following equivalences: int a[20]; a[i] - is equivalent to *(a+i) - is equivalent to *(&a[0]+i) – is equivalent to *((int*)((char*)&a[0]+i*sizeof(int))) You may substitute array indexing a[i] by *((int*)((char*)&a[0]+i*sizeof(int))) and it will work! C was designed to be machine independent assembler](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-45-320.jpg)
![2D Array. 1 st Implementation 1 st approach Normal 2D array. int a[4][3]; a[0][0]:100: a[0][1]:104: a[0][2]:108: a[1][0]:112: a[1][1]:116: a[1][2]:120: a[2][0]:124: a[2][1]:128: a[2][2]:132: a[3][0]:136: a[3][1]:140: a[3][2]:144: a: a[i][j] == *(int*)((char*)a + i*3*sizeof(int) + j*sizeof(int))](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-46-320.jpg)
![2D Array 2 nd Implementation 2 nd approach Array of pointers to rows int*(a[4]); for(int i=0; i<4; i++){ a[i]=(int*)malloc(sizeof(int)*3); assert(a[i]!=NULL); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-47-320.jpg)
![2D Array 2 nd Implementation 2 nd approach Array of pointers to rows (cont) a[0]:100: a[1]:104: a[2]:108: a[3]:112: a[1][0] a[0][0] a[3][1] a[2][0] a[3][0] a[2][1] a[0][1] a[1][1] a[3][2] a[2][2] a[0][2] a[1][2] int*(a[4]); a[3][2]=5 a:](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-48-320.jpg)
![2D Array 3 rd Implementation 3 rd approach. a is a pointer to an array of pointers to rows. int **a; a=(int**)malloc(4*sizeof(int*)); assert( a!= NULL) for(int i=0; i<4; i++) { a[i]=(int*)malloc(3*sizeof(int)); assert(a[i] != NULL) }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-49-320.jpg)
![2D Array 3 rd Implementation a is a pointer to an array of pointers to rows. (cont.) a[0]:100: a[1]:104: a[2]:108: a[3]:112: a[1][0] a[0][0] a[3][1] a[2][0] a[3][0] a[2][1] a[0][1] a[1][1] a[3][2] a[2][2] a[0][2] a[1][2] int **a; a[3][2]=5 a:](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-50-320.jpg)

![Advantages of Pointer Based Arrays Example: Triangular matrix a[0]:100: a[1]:104: a[2]:108: a[3]:112: a[1][0] a[0][0] a[2][0] a[3][0] a[2][1] a[0][1] a[1][1] a[0][2] a[1][2] a[0][3] int **a; a:](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-52-320.jpg)

![An Array Mapper typedef void (*FuncPtr)(int a); void intArrayMapper( int *array, int n, FuncPtr func ) { for( int = 0; i < n; i++ ) { (*func)( array[ i ] ); } } int s = 0; void sumInt( int val ){ s += val; } void printInt( int val ) { printf("val = %d \n", val); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-54-320.jpg)
![Using the Array Mapper int a[ ] = {3,4,7,8}; main( ){ // Print the values in the array intArrayMapper(a, sizeof(a)/sizeof(int), printInt); // Print the sum of the elements in the array s = 0; intArrayMapper(a, sizeof(a)/sizeof(int), sumInt); printf(“total=%d\”, s); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-55-320.jpg)


![Using the Generic Mapper int a[ ] = {3,4,7,8}; main( ) { // Print integer values s = 0; genericArrayMapper( a, sizeof(a)/sizeof(int), sizeof(int), printIntGen); // Compute sum the integer values genericArrayMapper( a, sizeof(a)/sizeof(int), sizeof(int), sumIntGen); printf(“s=%d\n”, s); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-58-320.jpg)








![Types of Computer Systems Personal Computers One computer one user This was possible at the end of the 70s thanks to the arrival of the microprocessor that allowed inexpensive computers. The first widely available PC was the Apple ][ with a 6502 CPU (16 bits) that typically had 48KB of RAM. The killer app was called Visicalc, a spreadsheet. The OS was practically null. Now PCs typically have at least 256MB and the CPU is 32 bit. They OS has the same complexity of a mainframe.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-67-320.jpg)
































![System Calls and Interrupts Example The user program calls the write(fd, buff, n) system call to write to disk. The write wrapper in libc generates a software interrupt for the system call. The OS in the interrupt handler checks the arguments. It verifies that fd is a file descriptor for a file opened in write mode. And also that [buff, buff+n-1] is a valid memory range. If any of the checks fail write return -1 and sets errno to the error value.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-102-320.jpg)
![System Calls and Interrupts Example 4. The OS tells the hard drive to write the buffer in [buff, buff+n] to disk to the file specified by fd. 5. The OS puts the current process in wait state until the disk operation is complete. Meanwhile, the OS switches to another process. 6. The Disk completes the write operation and generates an interrupt. 7. The interrupt handler puts the process calling write into ready state so this process will be scheduled by the OS in the next chance.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-103-320.jpg)




































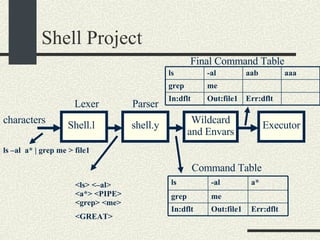
![Shell Grammar You need to implement the following grammar in shell.l and shell.y cmd [arg]* [ | cmd [arg]* ]* [ [> filename] [< filename] [ >& filename] [>> filename] [>>& filename] ]* [&] Currently, the grammar implemented is very simple Examples of commands accepted by the new grammar. ls –al ls –al > out ls –al | sort >& out awk –f x.awk | sort –u < infile > outfile &](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-145-320.jpg)


![Shell Parser Rules Step 3. You need to add more rules to shell.y cmd [arg]* [ | cmd [arg]* ]* [ [> filename] [< filename] [ >& filename] [>> filename] [>>& filename] ]* [&] pipe_list cmd_and_args arg_list io_modifier io_modifier_list background_optional command_line](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-148-320.jpg)











![The open() system call int open(filename, mode, [permissions]), It opens the file in filename using the permissions in mode . Mode: O_RDONLY, O_WRONLY, O_RDWR, O_CREAT, O_APPEND, O_TRUNC O_CREAT If the file does not exist, the file is created.Use the permissions argument for initial permissions. Bits: rwx(user) rwx(group) rwx (others) Example: 0555 – Read and execute by user, group and others. (101B==5Octal) O_APPEND. Append at the end of the file. O_TRUNC. Truncate file to length 0. See “man open”](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-161-320.jpg)



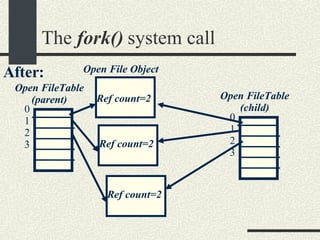

![The execvp() system call int execvp(progname, argv[]) Loads a program in the current process. The old program is overwritten. progname is the name of the executable to load. argv is the array with the arguments. Argv[0] is the progname itself. The entry after the last argument should be a NULL so execvp() can determine where the argument list ends. If successful, execvp() will not return.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-168-320.jpg)
![The execvp() system call void main() { // Create a new process int ret = fork(); if (ret == 0) { // Child process. // Execute “ls –al” const char *argv[3]; argv[0]=“ls”; argv[1]=“-al”; argv[2] = NULL; execvp(argv[0], argv); // There was an error perror(“execvp”); exit(1); } else if (ret < 0) { // There was an error in fork perror(“fork”); exit(2); } else { // This is the parent process // ret is the pid of the child // Wait until the child exits waitpid(ret, NULL); } // end if }// end main Example: Run “ls –al” from a program.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-169-320.jpg)
![The execvp() system call Command::execute() { int ret; for ( int i = 0; i < _numberOfSimpleCommands; i++ ) { ret = fork(); if (ret == 0) { //child execvp(sCom[i]->_args[0], sCom[i]->_args); perror(“execvp”); exit(1); } else if (ret < 0) { perror(“fork”); return; } // Parent shell continue } // for if (!background) { // wait for last process waitpid(ret, NULL); } }// execute For lab3 part2 start by creating a new process for each command in the pipeline and making the parent wait for the last command.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-170-320.jpg)

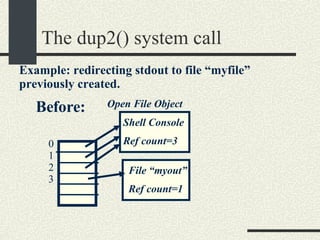
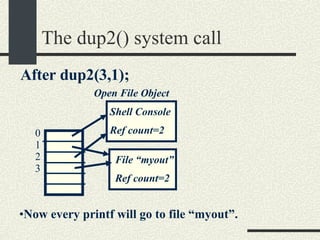


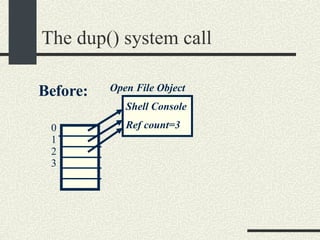
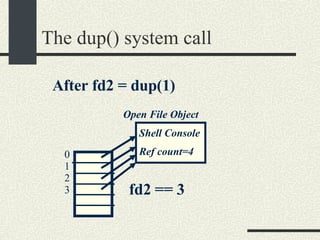
![The pipe system call int pipe(fdpipe[2]) fdpipe[2] is an array of int with two elements. After calling pipe, fdpipe will contain two file descriptors that point to two open file objects that are interconnected. What is written into one of the file descriptors can be read from the other one and vice versa.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-178-320.jpg)
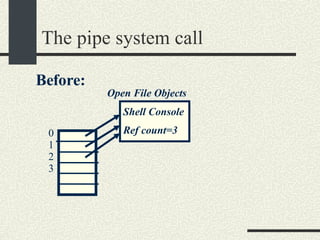
![The pipe system call Open File Objects Shell Console Ref count=3 After running: int fdpipe[2]; pipe(fdpipe); 0 1 2 3 4 pipe0 Ref count=1 Pipe1 Ref count=1 fdpipe[0]==3 fdpipe[1]==4 What is written in fdpipe[0] can be read from fdpipe[1] and vice versa.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-180-320.jpg)
![Example of pipes and redirection A program “lsgrep” that runs “ls –al | grep arg1 > arg2”. Example: “lsgrep aa myout” lists all files that contain “aa” and puts output in file myout. int main(int argc,char**argv) { if (argc < 3) { fprintf(stderr, "usage:” “ lsgrep arg1 arg2\n"); exit(1); } // Strategy: parent does the // redirection before fork() //save stdin/stdout int tempin = dup(0); int tempout = dup(1); //create pipe int fdpipe[2]; pipe(fdpipe); //redirect stdout for "ls“ dup2(fdpipe[0],1); close(fdpipe[0]);](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-181-320.jpg)
![Example of pipes and redirection // fork for "ls” int ret= fork(); if(ret==0) { // close file descriptors // as soon as are not // needed close(fdpipe[1]); char * args[3]; args[0]="ls"; args[1]=“-al"; args[2]=NULL; execvp(args[0], args); // error in execvp perror("execvp"); exit(1); } //redirection for "grep“ //redirect stdin dup2(fdpipe[1], 0); close(fdpipe[1]); //create outfile int fd=open(argv[2], O_WRONLY|O_CREAT|O_TRUNC, 0600); if (fd < 0){ perror("open"); exit(1); } //redirect stdout dup2(fd,1); close(fd);](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-182-320.jpg)
![Example of pipes and redirection // fork for “grep” ret= fork(); if(ret==0) { char * args[2]; args[0]=“grep"; args[1]=argv[1]; args[2]=NULL; execvp(args[0], args); // error in execvp perror("execvp"); exit(1); } // Restore stdin/stdout dup2(tempin,0); dup2(tempout,1); // Parent waits for grep // process waitpid(ret,NULL); printf(“All done!!\n”); } // main](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-183-320.jpg)


![Execution Strategy for Your Shell else { // Not last //simple command //create pipe int fdpipe[2]; pipe(fdpipe); fdout=fdpipe[0]; fdin=fdpipe[1]; }// if/else // Redirect output dup2(fdout,1); close(fdout); // Create child process ret=fork(); if(ret==0) { execvp(scmd[i].args[0], scmd[i].args); perror(“execvp”); exit(1); } } // for](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-186-320.jpg)

![Notes about Shell Strategy The key point is that fdin is set to be the input for the next command. fdin is a descriptor either of an input file if it is the first command or a fdpipe[1] if it is not the first command. This example only handles pipes and in/out redirection You have to redirect stderr for all processes if necessary You will need to handle the “append” case](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-188-320.jpg)







![Sorting Directory Entries struct dirent * ent; int maxEntries = 20; int nEntries = 0; char ** array = (char**) malloc(maxEntries*sizeof(char*)); while ( (ent = readdir(dir))!= NULL) { // Check if name matches if (advance(ent->d_name, expbuf) ) { if (nEntries == maxEntries) { maxEntries *=2; array = realloc(array, maxEntries*sizeof(char*)); assert(array!=NULL); } array[nEntries]= strdup(ent->d_name); nEntries++; } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-196-320.jpg)
![Sorting Directory Entries closedir(dir); sortArrayStrings(array, nEntries); // Add arguments for (int i = 0; i < nEntries; i++) { Command::_currentSimpleCommand-> insertArgument(array[i])); } free(array);](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-197-320.jpg)

![Wildcards and Hidden Files if (advance (…) ) { if (ent->d_name[0] == ‘.’) { if (arg[0] == ‘.’) add filename to arguments; } } else { add ent->d_name to arguments } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-199-320.jpg)



![Subdirectory Wildcards #define MAXFILENAME 1024 void expandWildcard(char * prefix, char *suffix) { if (suffix[0]== 0) { // suffix is empty. Put prefix in argument. … ->insertArgument(strdup(prefix)); return; } // Obtain the next component in the suffix // Also advance suffix. char * s = strchr(suffix, ‘/’); char component[MAXFILENAME]; if (s!=NULL){ // Copy up to the first “/” strncpy(component,suffix, s-suffix); suffix = s + 1; } else { // Last part of path. Copy whole thing. strcpy(component, suffix); suffix = suffix + strlen(suffix); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-203-320.jpg)
![Subdirectory Wildcards // Now we need to expand the component char newPrefix[MAXFILENAME]; if ( component does not have ‘*’ or ‘?’) { // component does not have wildcards sprintf(newPrefix,”%s/%s”, prefix, component); expandWildcard(newPrefix, suffix); return; } // Component has wildcards // Convert component to regular expression char * expbuf = compile(…) char * dir; // If prefix is empty then list current directory if (prefix is empty) dir =“.”; else dir=prefix; DIR * d=opendir(dir); if (d==NULL) return;](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-204-320.jpg)


![Executing printenv Execute printenv in the child process and exit. In this way the output of printenv could be redirected. ret = fork(); if (ret == 0) { if (!strcmp(argument[0],printenv)) { char **p=environ; while (*p!=NULL) { printf(“%s”,*p); p++; } exit(0); } … execvp(…); …](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-207-320.jpg)





































































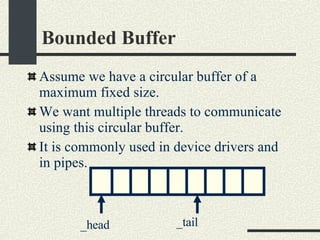

![Bounded Buffer #include <pthread.h> enum {MaxSize = 10}; class BoundedBuffer{ int _queue[MaxSize]; int _head; int _tail; mutex_t _mutex; sema_t _emptySem; sema_t _fullSem; public: BoundedBuffer(); void enqueue(int val); int dequeue(); }; BoundedBuffer:: BoundedBuffer() { _head = 0; _tail = 0; pthtread_mutex_init(&_mutex, NULL, NULL); sema_init(&_emptySem, 0 USYNC_THREAD, NULL); sema_init(&_fullSem, MaxSize USYNC_THREAD, NULL); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-281-320.jpg)
![Bounded Buffer void BoundedBuffer:: enqueue(int val) { sema_wait(&_fullSem); mutex_lock(_mutex); _queue[_tail]=val; _tail = (_tail+1)%MaxSize; mutex_unlock(_mutex); sema_post(_emptySem); } int BoundedBuffer:: dequeue() { sema_wait(&_emptySem); mutex_lock(_mutex); int val = _queue[_head]; _head = (_head+1)%MaxSize; mutex_unlock(_mutex); sema_post(_fullSem); return val; }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-282-320.jpg)




















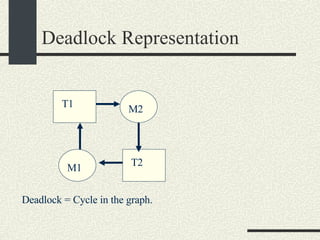
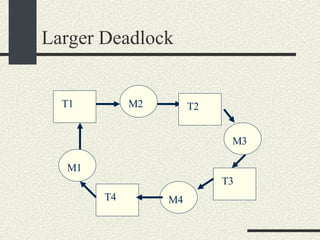




![Preventing a Deadlock int balance[MAXACOUNTS]; mutex_t mutex[MAXACOUNTS]; Transfer_i_to_j(int i, int j, int amount) { if ( i< j) { mutex_lock(&mutex[i]); mutex_lock(&mutex[j]); } else { mutex_lock(&mutex[j]); mutex_lock(&mutex[i]); } We can rewrite the Transfer function s more generically as: balance1 -= amount; balance2 += amount; mutex_unlock(&mutex[i]); mutex_unlock(&mutex[j]); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-310-320.jpg)


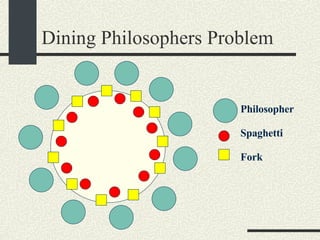

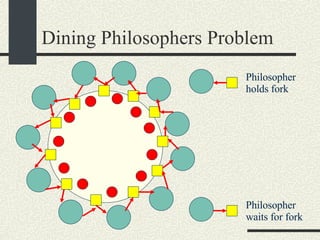
![Dining Philosophers Problem (Unfixed Version) const int NPHILOSOPHERS=10; mutex_t fork_mutex[NPHILOSOPHERS]; pthread_t threadid[NPHILOSOPHERS]; void eat_spaghetti_thread(int i) { while (i_am_hungry[i]) { mutex_lock(&fork_mutex[i]); mutex_lock(&fork_mutex[(i+1)%NPHILOSOPHERS); // Eat spaghetti chomp_chomp(i); mutex_unlock(&fork_mutex[i]); mutex_unlock(&fork_mutex[(i+1)%NPHILOSOPHERS); } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-316-320.jpg)
![Dining Philosophers Problem (Unfixed Version) main() { for (int i = 0; i < NPHILOSOPHERS; i++) { mutex_init(&_fork_mutex[i]); } for (int i = 0; i < NPHILOSOPHERS; i++) { pthread_create(&threadid[i],eat_spaghetti_thread, i, NULL); } // Wait until they are done eating for (int i = 0; i < NPHILOSOPHERS; i++) { pthread_join(&threadid[i]); } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-317-320.jpg)

![Dining Philosophers Problem (Fixed Version) void eat_spaghetti_thread(int philosopherNum) { while (i_am_hungry[philosopherNum]) { int i = philosopherNum; int j = (philosopherNum+1)% NPHILOSOPHERS; if (i > j) { /*Swap i and j */ int tmp=i; i=j; j=tmp; } // Lock lower order mutex first mutex_lock(&fork_mutex[i]); mutex_lock(&fork_mutex[j]); // Eat spaghetti chomp_chomp(philosopherNum); mutex_unlock(&fork_mutex[i]); mutex_unlock(&fork_mutex[j]); } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-319-320.jpg)














![Bounded Buffer with Condition Variables #include <pthread.h> enum {MaxSize = 10}; class BoundedBuffer{ int _queue[MaxSize]; int _head; int _tail; int _n; mutex_t _mutex; cond_t _emptyCond; cond_t _fullCond; public: BoundedBuffer(); void enqueue(int val); int dequeue(); }; BoundedBuffer:: BoundedBuffer() { _head = 0; _tail = 0; _n = 0; pthtread_mutex_init(&_mutex, NULL, NULL); cond_init(&_emptyCond, USYNC_THREAD, NULL); cond_init(&_fullCond, USYNC_THREAD, NULL); }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-334-320.jpg)
![Bounded Buffer with Condition Variables void BoundedBuffer:: enqueue(int val) { mutex_lock(_mutex); // Wait if queue is full while (_n == MaxSize) { // queue is full cond_wait(&_fullCond, &_mutex); } // There is space in queue _queue[_tail]=val; _tail = (_tail+1)%MaxSize; _n++; // Wake up a thread waiting in // dequeue if any cond_signal(_emptyCond); mutex_unlock(_mutex); } int * BoundedBuffer:: dequeue() { mutex_lock(_mutex); // Wait if queue is empty while (_n==0) { cond_wait(&_emptyCond, &_mutex); } // queue is not empty int val = _queue[_head]; _head = (_head+1)%MaxSize; _n--; // wake up a tread waiting in // enqueue if any _cond_signal(_fullCond) mutex_unlock(_mutex); return val; }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-335-320.jpg)









![A Synchronized Hash Table struct HashTableNode { char * _key; void * _data; HashTableNode * _next; }; class SyncHashTable { enum {TableSize=1043); HashTableNode *_table[TableSize]; mutex_t _mutex; cond_t _cond_new_key; int hash(char *key); public: SyncHashTable(); void insert(char * key, void * data); void * lookup(char *key); void remove(char *key); }; SyncHashTable::SyncHashTable() { for (int i=0; i<TableSize;i++){ _table[i]=NULL; } mutex_init(&_mutex,NULL,NULL); cond_init(&_cond_new_key,NULL); }; int SyncHashTable::hash(char *key) { char * p = key; int i = 0; int sum = 0; while (*p != ‘\0’) { sum += *p * i; i++;p++; } return sum % TableSize; }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-345-320.jpg)
![A Synchronized Hash Table void SyncHashTable::insert(char * key, void * data) { mutex_lock(&_mutex); // Find key int h = hash(key); HashTableNode * node = _table[h]; while (node != NULL && strcmp(node->_key,key)!= 0) { node = node->_next; } if (node!=NULL) { // Key exists. Replace data // and return node->data = data; mutex_unlock(&_data); return; } // Key not found. Add new node node = new HashTableNode(); node->_key = strdup(key); node->_data = data; // Add node to the hash list node->_next = _table[h]; _table[h] = _node; // Wake up any thread // waiting for this key cond_broadcast( & _cond_new_key); mutex_unlock(&_mutex); }// insert](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-346-320.jpg)
![A Synchronized Hash Table void * SyncHashTable::lookup(char *key) { bool found = false; mutex_lock(&_mutex); while (!found) { // Find key int h = hash(key); HashTableNode * node = _table[h]; while (node != NULL && strcmp(node->_key,key)!= 0) { node = node->_next; } if (node!=NULL) { // Found key. found = true; } else { // Key not found. Wait for // new insertions cond_wait(& _cond_new_key, &_mutex); } } //while // Key found. Get data void * data = node->data; mutex_unlock(&_mutex); return data; } // lookup](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-347-320.jpg)
![A Synchronized Hash Table void SyncHashTable::remove(char *key) { mutex_lock(&_mutex); // Find key int h = hash(key); HashTableNode *prev = NULL; HashTableNode * node = _table[h]; while (node != NULL && strcmp(node->_key,key)!= 0) { prev = node; node = node->_next; } if (node==NULL) { // key not found. return mutex_unlock(&_mutex); return; } } // Key found. Remove node if (prev == NULL) { // beginning of list _table[h] = node->_next; } else { prev->_next = node->_next; } // Recycle node and key free(node->_key); delete node; mutex_unlock(&_mutex); }// remove](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-348-320.jpg)
![A Synchronized Hash Table void SyncHashTable::insert(char * key, void * data) { mutex_lock(&_mutex); // Find key int h = hash(key); HashTableNode * node = _table[h]; while (node != NULL && strcmp(node->_key,key)!= 0) { node = node->_next; } if (node!=NULL) { // Store data node->data = data; mutex_unlock(&_data); return; } } // Key not found. Add new node node = new HashTableNode(); node->_key = strdup(key); node->_data = data; // Add node to the hash list node->_next = _table[h]; _table[h] = _node; // Wake up any thread // waiting for this key cond_signal( & _cond_new_key); mutex_unlock(&_mutex); }// insert void * SyncHashTable ::lookup(char *key); void SyncHashTable ::remove(char *key);](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-349-320.jpg)









![Pool of Threads void poolOfThreads( int masterSocket ) { for (int i=0; i<4; i++) { pthread_create(&thread[i], NULL, loopthread, masterSocket); } loopthread (masterSocket); } void *loopthread (int masterSocket) { while (1) { int slaveSocket = accept(masterSocket, &sockInfo, 0); if (slaveSocket >= 0) { dispatchHTTP(slaveSocket); } } }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-359-320.jpg)




























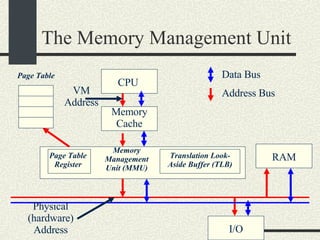




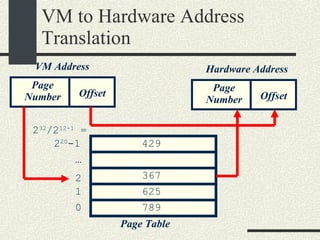
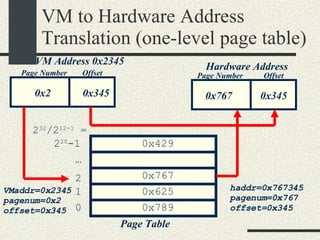




![Example VMaddress: 0x00402 657 Physical Memory Address: 0x2 657 1.From the VM address find i, j, offset 2. SecondLevelPageTable= FirstLevelPageTable[i] 3. PhysMemPageNumber = SecondLevelPageTable[j] 4. PhysMemAddr= PhysMemPageNum*Pagesize + offset Process always have a first-level page table Second level page tables are allocated as needed. Both the first level and second level page tables use 4KB.](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-399-320.jpg)
























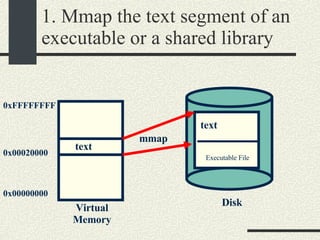
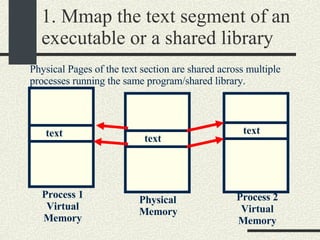

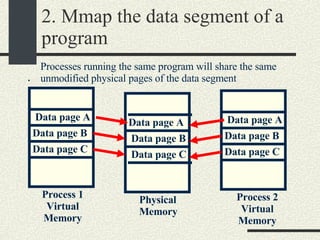
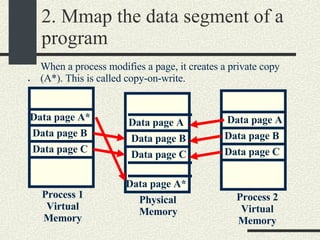


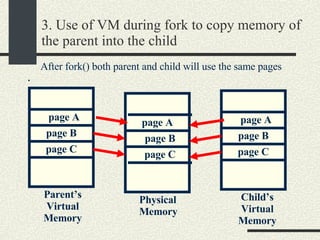
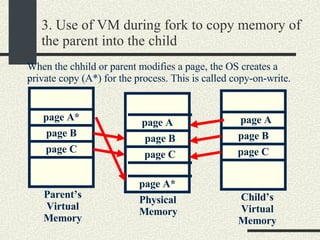


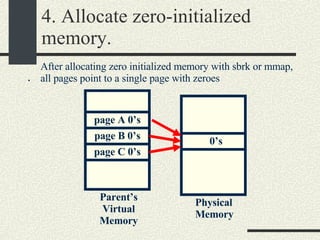
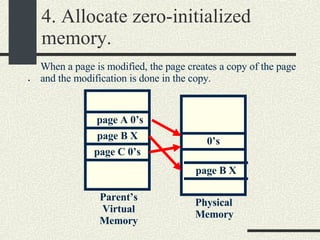

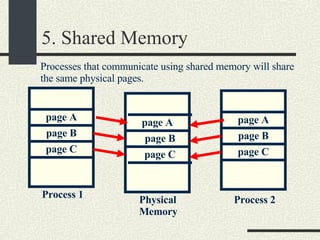
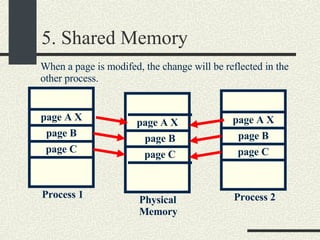


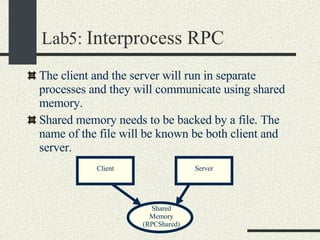


![RPCShared The structure RPCShared is stored in shared memory It contains an array _callBuffer of type RPCCallBuffer that has the state of an RPC invocation. Each entry has: // Next RPCCallBuffer in the list of available service buffers int _next; // Return Status int _retStatus; // The client waits on this semaphore until // the result is ready sema_t _done; // Name of the procedure that is being executed cha _rpcName[ RPCMaxName ]; // The arguments of the procedure are stored here RPCArgument _argument; // The results are stored here RPCResult _result;](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-448-320.jpg)




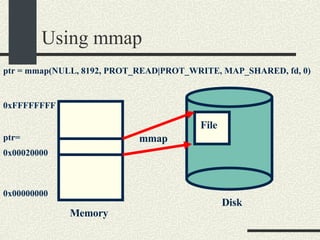
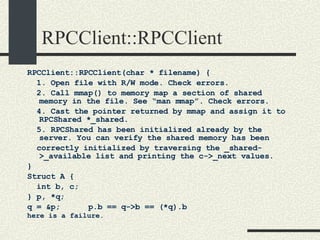
![RPCServer::RPCServer RPCServer::RPCServer(char * filename) { 1. Create file or truncate it if it does not exist using open.Open it with R/W mode. Check errors 2. Write as many 0’s in the file as sizeof(RPCShared) 3. Call mmap() to memory map a section of shared memory in the file. See “man mmap”. Check errors. 4. Cast the pointer returned by mmap and assign it to RPCShared *_shared. 5. Initialize the _available list. _available = 0; _shared-> _callBuffer [0]._next = 1; _shared-> _callBuffer [1]._next = 2; and so on until _shared-> _callBuffer [MaxCallBuffers-1].next = -1; 6. Initialize _service to -1. 7. Initialize semaphores _empty, _full, and _mutex. Use the USYNC_PROCESS flag since these semaphore will synchronize across process boundaries. }](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-453-320.jpg)







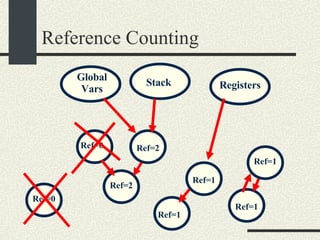

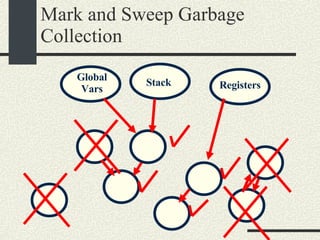



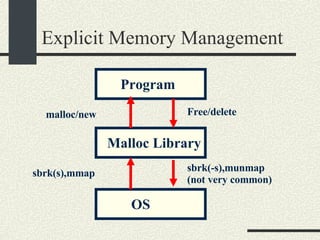

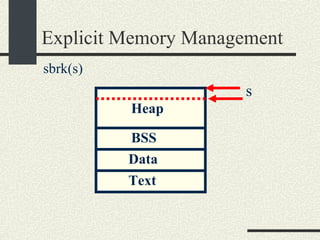




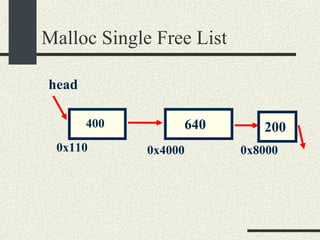



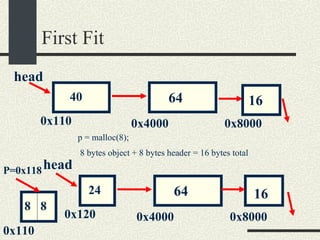
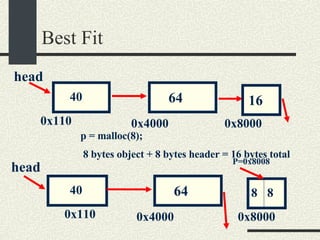









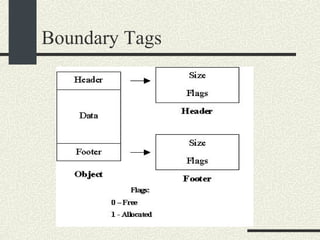


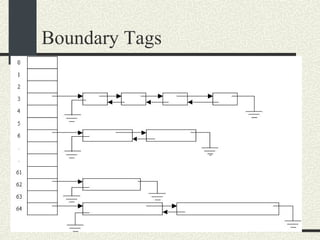








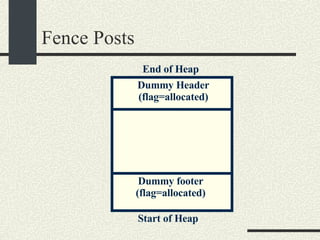
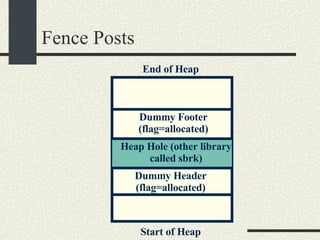





















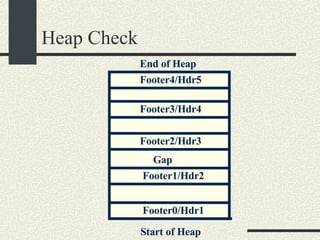





















![/usr/proc/bin/pmaps bash-2.05a$ /usr/proc/bin/pmap 10086 10086: -bash 00010000 488K read/exec /usr/local/bin/bash 00098000 24K read/write/exec /usr/local/bin/bash 0009E000 144K read/write/exec [ heap ] FF180000 664K read/exec /usr/lib/libc.so.1 FF234000 32K read/write/exec /usr/lib/libc.so.1 FF23C000 8K read/write/exec [ anon ] FF250000 16K read/exec /usr/platform/sun4u/lib/libc_psr.so.1 FF270000 8K read/write/exec [ anon ] FF280000 512K read/exec /usr/lib/libnsl.so.1 FF30E000 40K read/write/exec /usr/lib/libnsl.so.1 FF318000 32K read/write/exec [ anon ] FF330000 32K read/exec /usr/lib/libsocket.so.1 FF346000 16K read/write/exec /usr/lib/libsocket.so.1 FF350000 168K read/exec /usr/lib/libcurses.so.1 FF388000 40K read/write/exec /usr/lib/libcurses.so.1 FF392000 8K read/write/exec [ anon ] FF3B0000 136K read/exec /usr/lib/ld.so.1 FF3E0000 16K read/write/exec /usr/lib/ld.so.1 FFBEC000 16K read/write/exec [ stack ] total 2432K](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-551-320.jpg)
![/usr/proc/bin/pfiles bash-2.05a$ /usr/proc/bin/pfiles 10086 10086: -bash Current rlimit: 64 file descriptors 0: S_IFCHR mode:0620 dev:136,0 ino:178361 uid:1152 gid:7 rdev:24,2 O_RDWR 1: S_IFCHR mode:0620 dev:136,0 ino:178361 uid:1152 gid:7 rdev:24,2 O_RDWR 2: S_IFCHR mode:0620 dev:136,0 ino:178361 uid:1152 gid:7 rdev:24,2 O_RDWR 3: S_IFDOOR mode:0444 dev:174,0 ino:21141 uid:0 gid:0 size:0 O_RDONLY|O_LARGEFILE FD_CLOEXEC door to nscd[186] 63: S_IFCHR mode:0620 dev:136,0 ino:178361 uid:1152 gid:7 rdev:24,2 O_RDWR FD_CLOEXEC bash-2.05a$](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-552-320.jpg)








![Kernel Modules in Linux -bash-2.05b$ uname -a Linux mrbill 2.4.20-8 #1 Thu Mar 13 17:54:28 EST 2003 i686 i686 i386 GNU/Linux -bash-2.05b$ /sbin/lsmod Module Size Used by Not tainted parport_pc 19076 1 (autoclean) lp 8996 0 (autoclean) parport 37056 1 (autoclean) [parport_pc lp] autofs 13268 0 (autoclean) (unused) nfs 81336 2 (autoclean) lockd 58704 1 (autoclean) [nfs] sunrpc 81564 1 (autoclean) [nfs lockd] e100 60644 1 keybdev 2944 0 (unused) mousedev 5492 0 (unused) hid 22148 0 (unused) input 5856 0 [keybdev mousedev hid] usb-uhci 26348 0 (unused) usbcore 78784 1 [hid usb-uhci] ext3 70784 2 jbd 51892 2 [ext3]](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-561-320.jpg)

![Kernel Symbols in Solaris The file /dev/ksyms in Solaris exports the kernel symbols so they can be listed bash-2.03$ nm /dev/ksyms | more [3372] | 270331380| 184|FUNC |LOCL |0 |ABS |ipif_renominate_bcast [14457] | 270353096| 420|FUNC |GLOB |0 |ABS |ipif_select_source [14827] | 270266636| 296|FUNC |GLOB |0 |ABS |ipif_select_source_v6 [3074] | 273143500| 4|OBJT |LOCL |0 |ABS |ipif_seqid [3264] | 273143496| 4|OBJT |LOCL |0 |ABS |ipif_seqid_wrap [3386] | 270345640| 472|FUNC |LOCL |0 |ABS |ipif_set_default [3321] | 270262172| 180|FUNC |LOCL |0 |ABS |ipif_set_tun_auto_addr [14725] | 270262352| 384|FUNC |GLOB |0 |ABS |ipif_set_tun_llink [3079] | 270357044| 1660|FUNC |LOCL |0 |ABS |ipif_set_values [14342] | 270262736| 236|FUNC |GLOB |0 |ABS |ipif_setlinklocal [14574] | 273188480| 4|OBJT |GLOB |0 |ABS |ipif_src_random [14788] | 273191384| 4|OBJT |GLOB |0 |ABS |ipif_src_random_v6 [14831] | 270379640| 164|FUNC |GLOB |0 |ABS |ipif_to_ire [14818] | 270282548| 168|FUNC |GLOB |0 |ABS |ipif_to_ire_v6 [14409] | 270346672| 372|FUNC |GLOB |0 |ABS |ipif_up](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-563-320.jpg)
![Kernel Symbols in Linux Also in Linux you can list the Kernel symbols -bash-2.05b$ /sbin/ksyms Address Symbol Defined by d08fe330 parport_pc_probe_port_R2ee6fe7f [parport_pc] d08fe940 parport_pc_unregister_port_R34f4c24e [parport_pc] d08fd000 __insmod_parport_pc_O/lib/modules/2.4.20-8/kernel/drivers/parport/parport_pc.o_M3E710DD1_V132116 [parport_pc] d08fd060 __insmod_parport_pc_S.text_L9694 [parport_pc] d08ffd60 __insmod_parport_pc_S.rodata_L180 [parport_pc] d0900b80 __insmod_parport_pc_S.data_L3840 [parport_pc] d08f9000 __insmod_lp_O/lib/modules/2.4.20-8/kernel/drivers/char/lp.o_M3E710DCB_V132116 [lp] d08f9060 __insmod_lp_S.text_L5395 [lp] d08fa714 __insmod_lp_S.rodata_L60 [lp] d08fafa0 __insmod_lp_S.data_L276 [lp] d08eead0 parport_claim_R91004644 [parport] d08eec80 parport_claim_or_block_Rde072c31 [parport] d08eecf0 parport_release_Re630d383 [parport]](https://image.slidesharecdn.com/cs354slides-1224272584980080-8/85/Purdue-CS354-Operating-Systems-2008-564-320.jpg)
























































































