Downloaded 48 times





















![[Mapping]
[Buckets]
[Rules]
[Map]](https://image.slidesharecdn.com/20131015-20deview-20-20mcgarry-131017082321-phpapp01/75/DEVIEW-2013-29-2048.jpg)
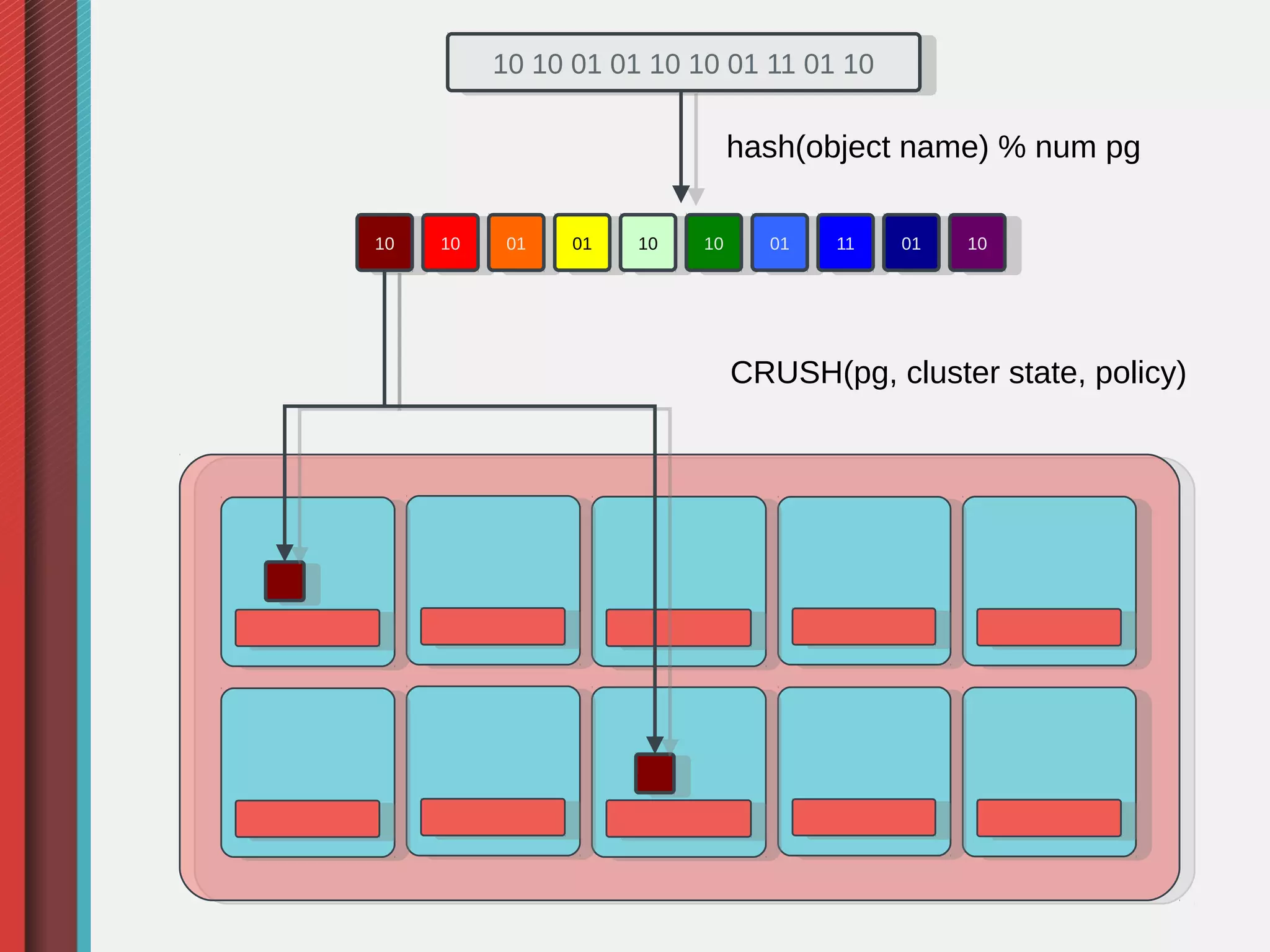
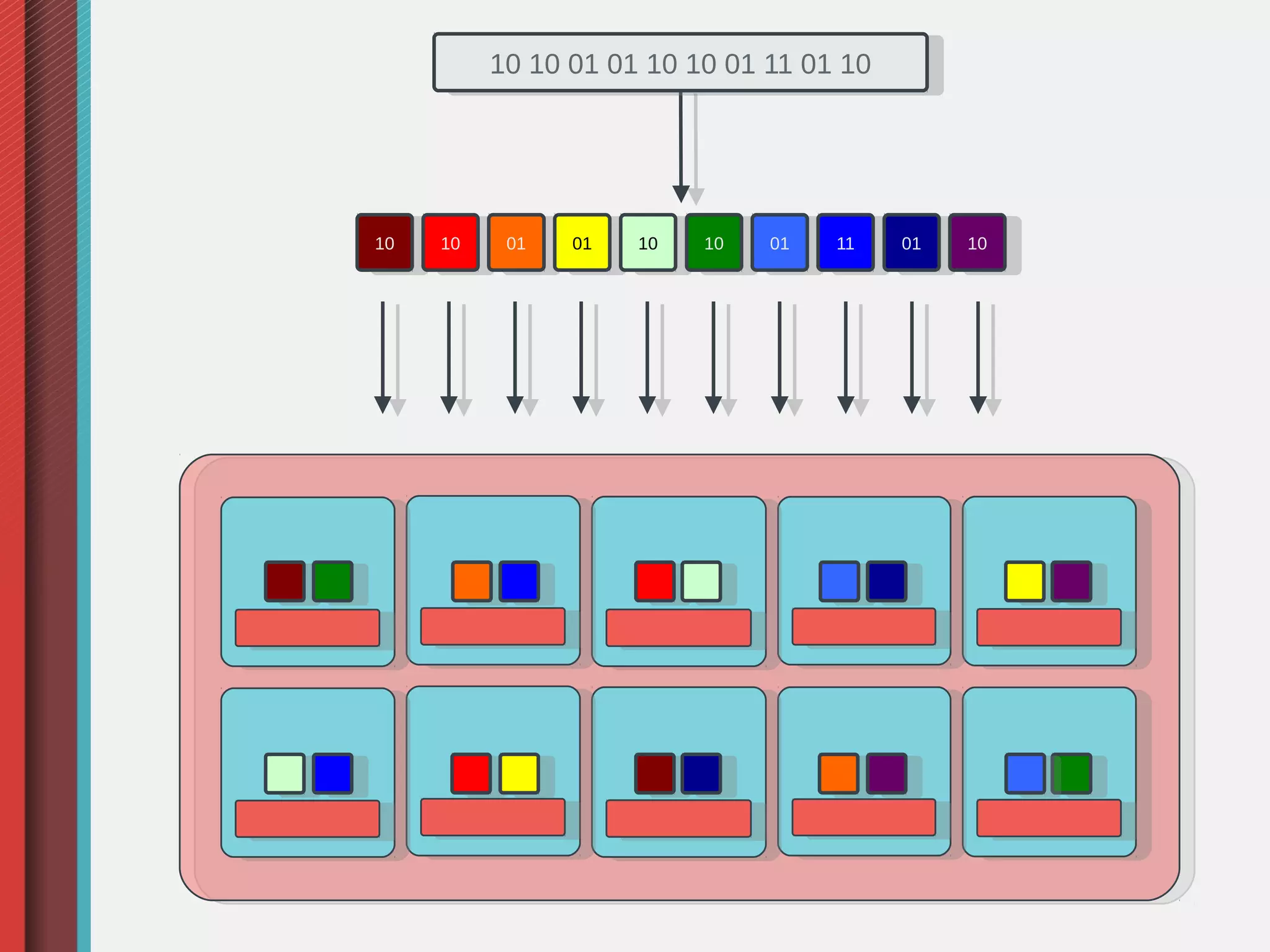
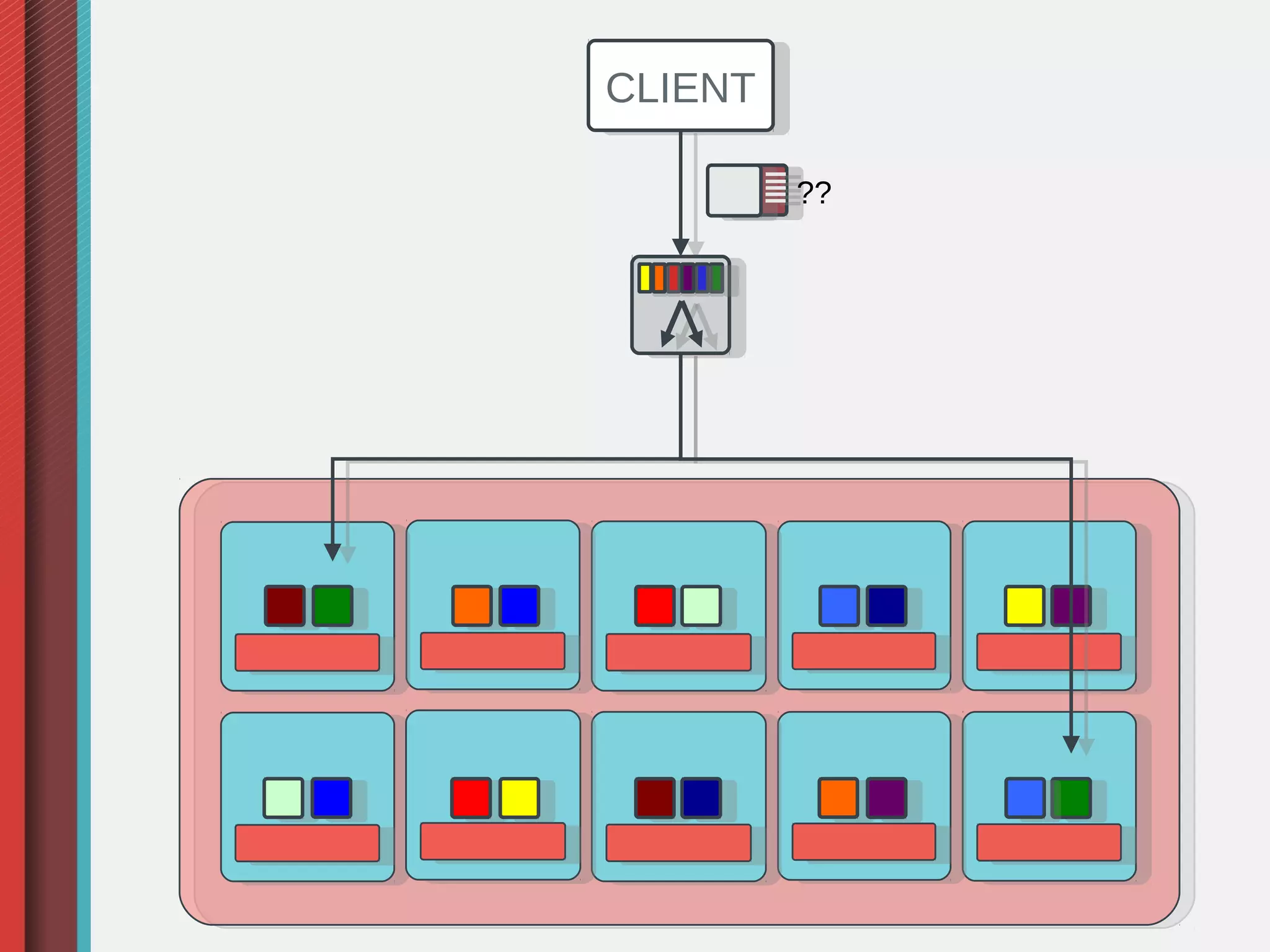


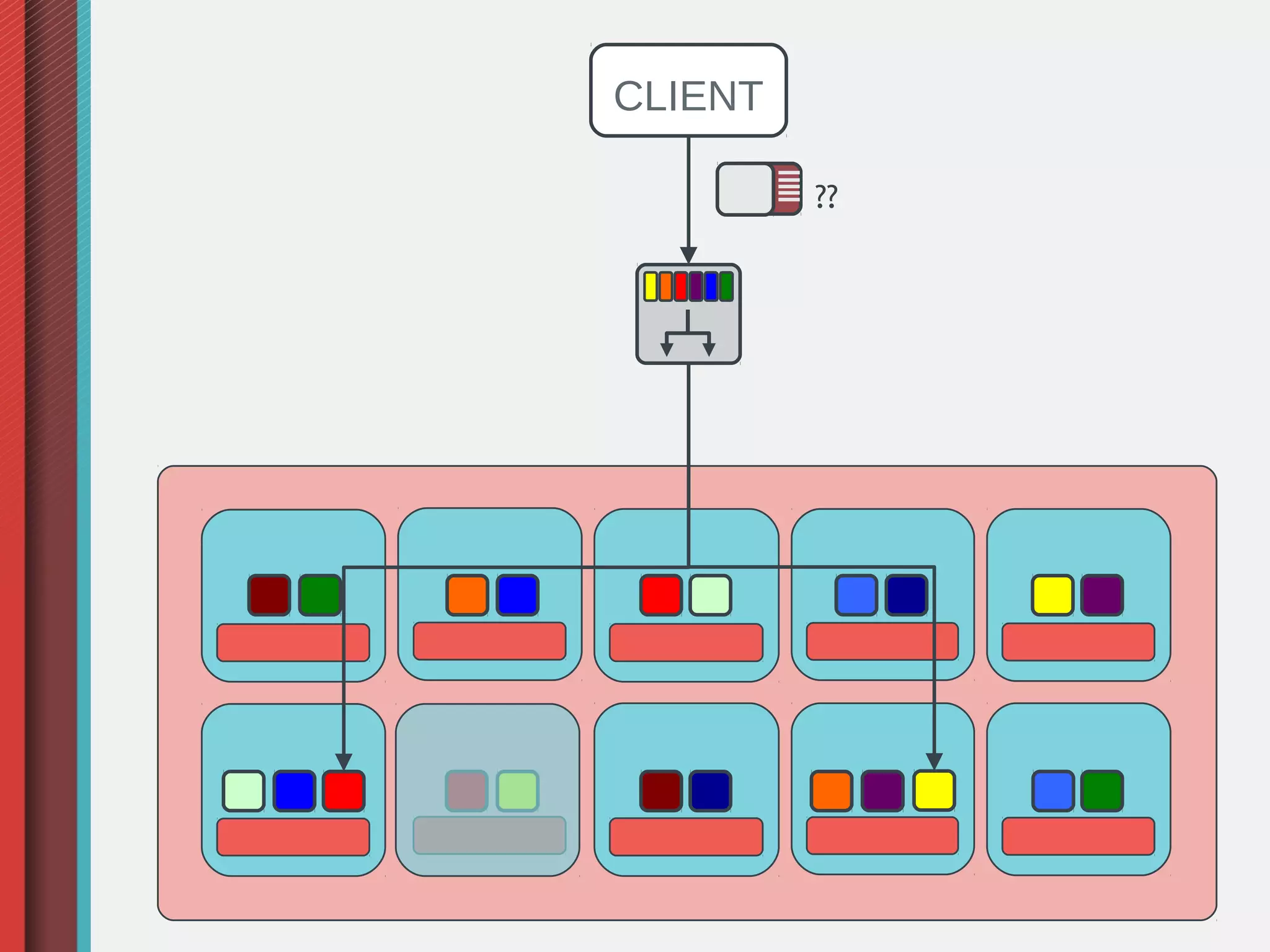





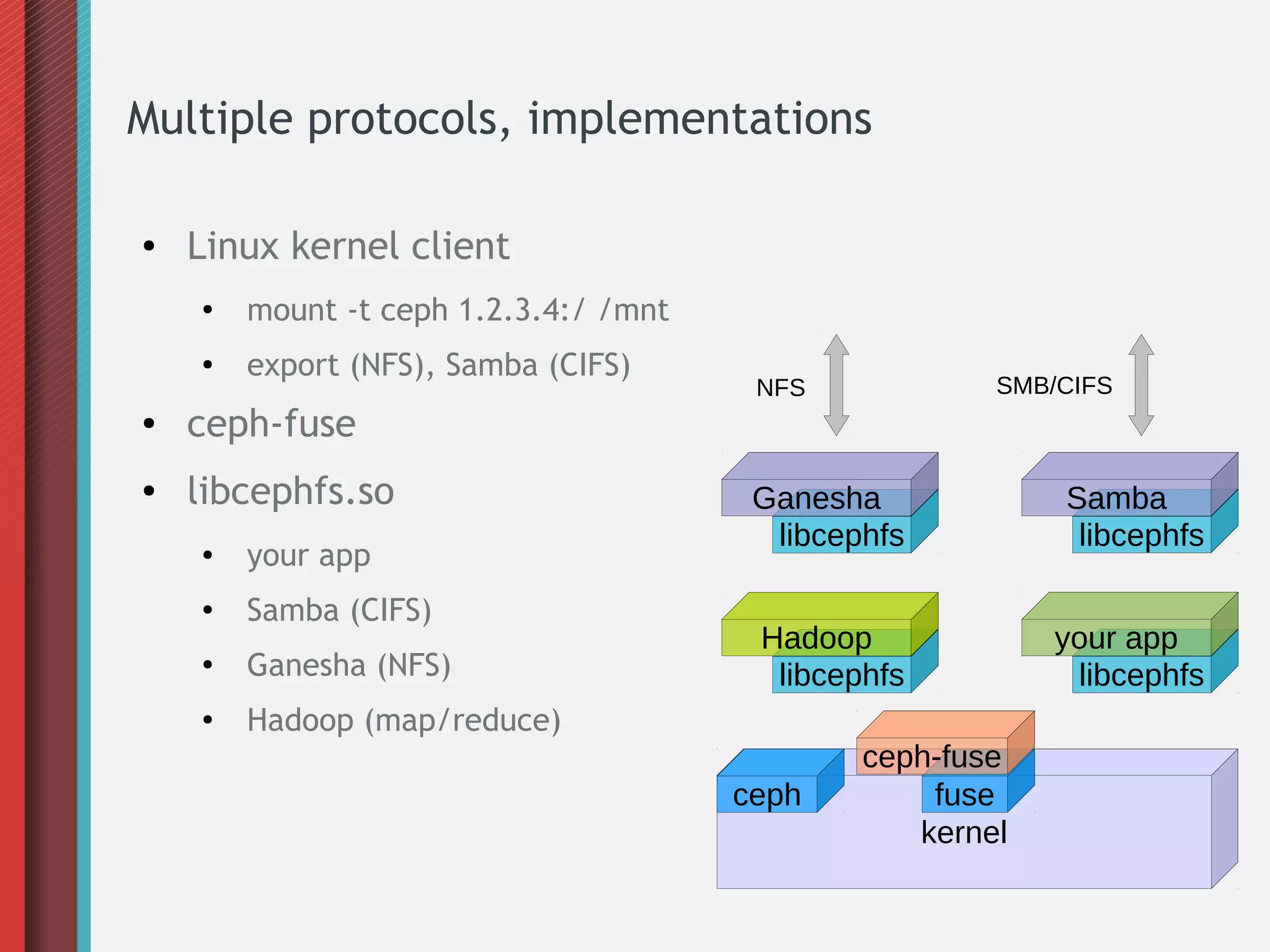











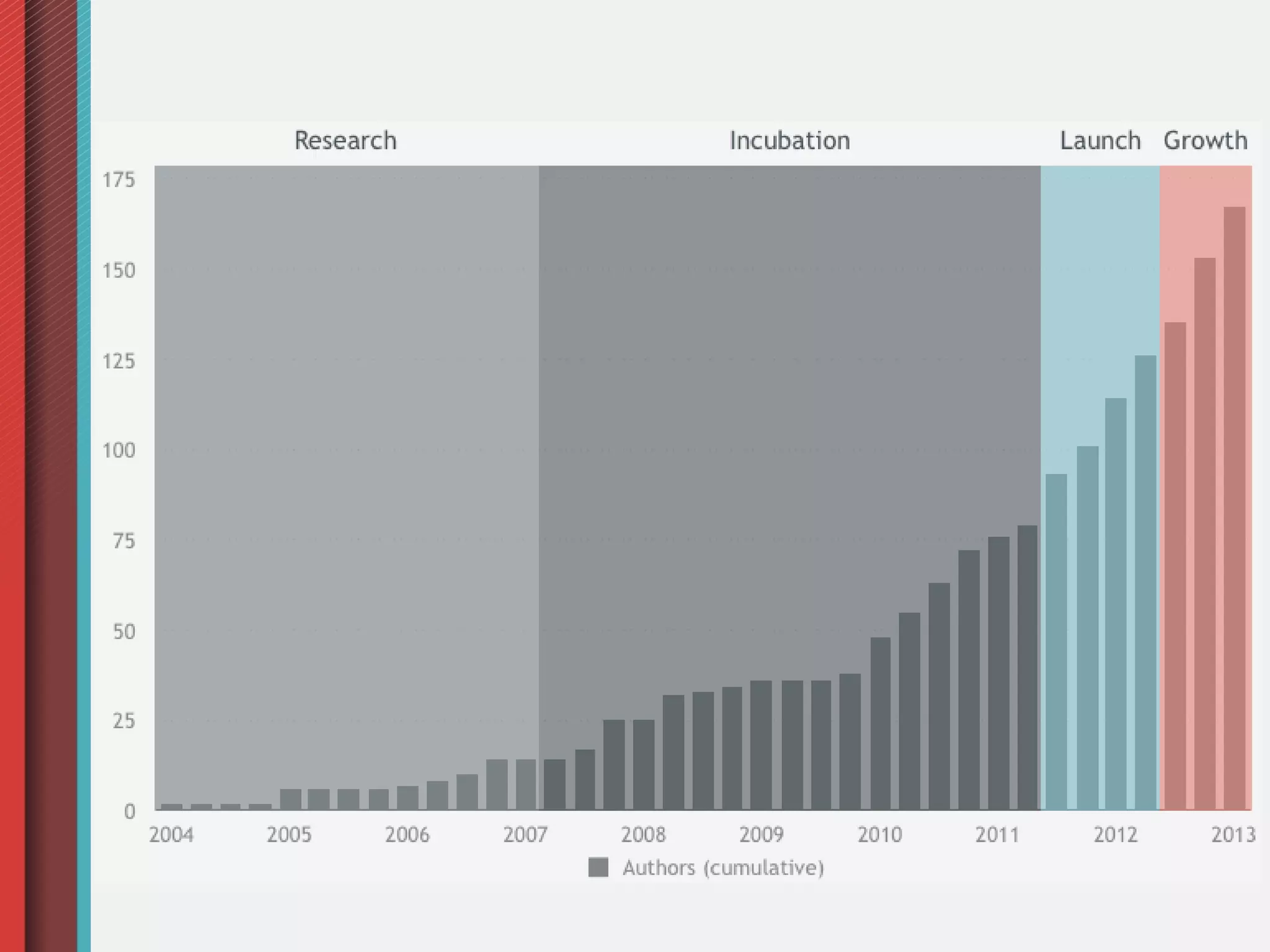
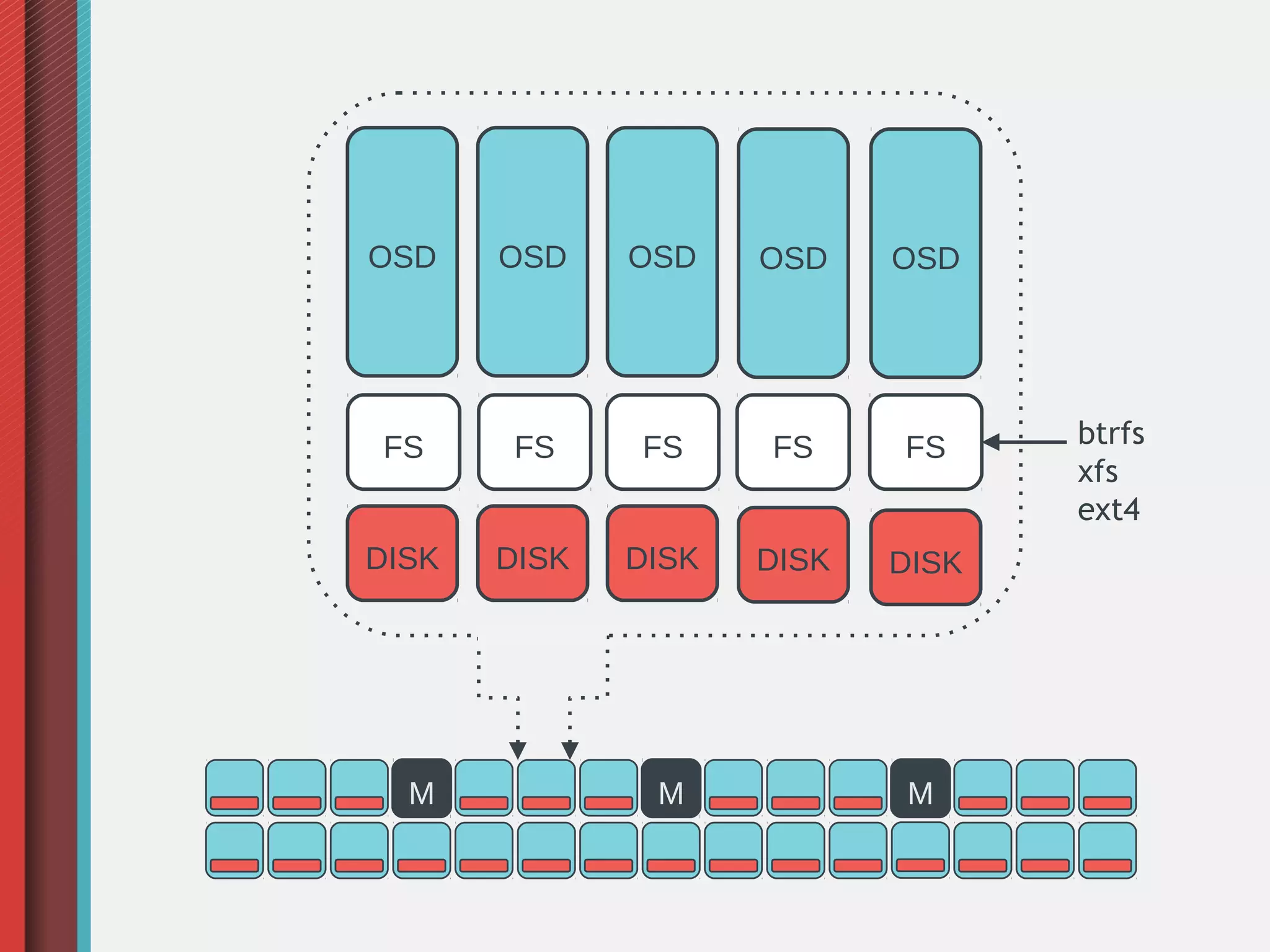
Ceph is an open-source distributed storage system that provides object, block, and file storage on commodity hardware. It uses a pseudo-random placement algorithm called CRUSH to distribute data across a cluster in a fault-tolerant manner without single points of failure. Ceph has various applications including a RADOS Gateway for S3/Swift compatibility, RADOS Block Device for virtual machine images, and a CephFS for a POSIX-compliant distributed file system.


















































































