実験設定
データセット
CIFAR-10 (60,000 32x 32 color images, 10 classes)
- 50,000 images for training
- 10,000 images for test
ネットワークアー
キテクチャおよび
パラメータ
- WideResNet [4]
(N = 1, k = 4)
- SGD with Nesterov
momentum
- cross-entropy loss
- the initial learning rate = 0.1
- weight decay = 5.0 x10-4
- momentum = 0.9
- minibatch size = 64
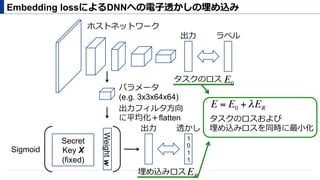
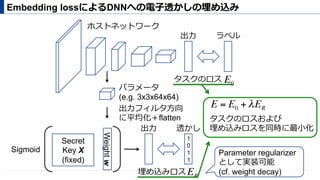
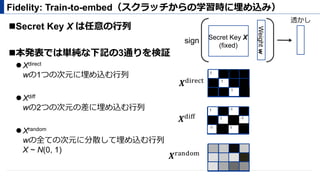
- λ = 0.01
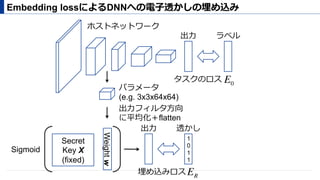
電⼦透かし 256 bit (T = 256)
埋め込み対象 conv2 group
[4] S. Zagoruyko and N. Komodakis. Wide residual networks. In Proc. of ECCV, 2016.
conv1
conv2
group
conv3
group
conv4
group
arg-pool
fc
M= 36864(3 x 3 x 64 x 64 )
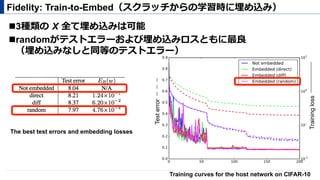
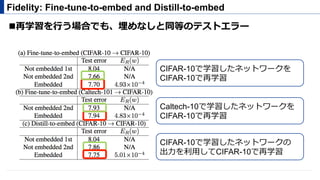
Robustness: fine-tuning
! 透かしを埋め込んだモデルをfine-tuningして透かしが消えるか?
" 同⼀ドメインでのfine-tuning (CIFAR-10→ CIFAR-10)
" 異なるドメインでのfine-tuning (Caltech-101 → CIFAR-10)
! どちらのケースでもfine-tuningで透かしは消えない
テストエラーも埋め込みなし (8.04%) と同等
Note: Caltech-101 dataset were resized to 32 x 32 for compatibility with the CIFAR-10
dataset though their original sizes is roughly 300 x 200.
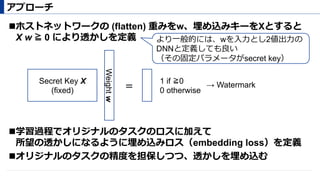
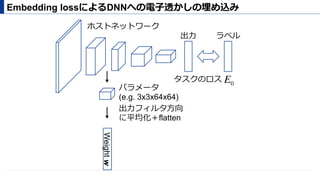
埋め込みロス
before after
28.
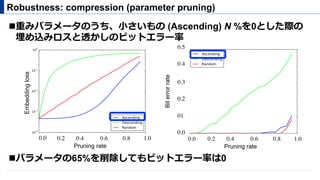
! モデル圧縮で透かしが消えるか?
" lossless : Huffmancording [5]
" lossy : weight quantization[5, 6], parameter pruning [5, 6]
Robustness: model compression
[5] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural networks with pruning, trained
quantization and huffman coding. In Proc. of ICLR, 2016.
[6] S. Han, J. Pool, J. Tran, and W. J. Dally. Learning both weights and connections for efficient neural networks.
In Proc. of NIPS, 2015.
! It is well-knownthat deep neural networks have many local
minima, and all local minima are almost optimal [8, 9].
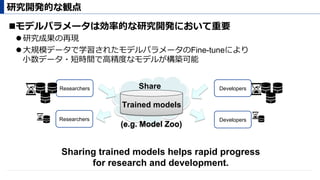
Why Did Our Approach Work So Well?
[7] A. Choromanska et al. The loss surfaces of multilayer networks. In Proc. of AISTATS, 2015.
[8] Y. Dauphin et al. Identifying and attacking the saddle point problem in high-dimensional non-convex
optimization. In Proc. of NIPS, 2014.
Loss
Parameter space
Standard SGD
32.
! It is well-knownthat deep neural networks have many local
minima, and all local minima are almost optimal [8, 9].
! Our embedding regularizer guides model parameters toward
a local minima, which has the desired watermark.
! Let us assume that we want to
embed the watermark “11”…
Why Did Our Approach Work So Well?
[7] A. Choromanska et al. The loss surfaces of multilayer networks. In Proc. of AISTATS, 2015.
[8] Y. Dauphin et al. Identifying and attacking the saddle point problem in high-dimensional non-convex
optimization. In Proc. of NIPS, 2014.
Loss
Parameter space
00 01 10 11
Detected
watermark
Standard SGD
SGD with
Embedding Loss
Our code isavailable at https://github.com/yu4u/dnn-watermark .
Thank you!
For more details, please refer to…
Y. Uchida, Y. Nagai, S. Sakazawa, and S. Satoh,
“Embedding Watermarks into Deep Neural Networks,”
in Proc. of International Conference on Multimedia Retrieval 2017.











![実験設定
データセット
CIFAR-10 (60,000 32 x 32 color images, 10 classes)
- 50,000 images for training
- 10,000 images for test
ネットワークアー
キテクチャおよび
パラメータ
- WideResNet [4]
(N = 1, k = 4)
- SGD with Nesterov
momentum
- cross-entropy loss
- the initial learning rate = 0.1
- weight decay = 5.0 x10-4
- momentum = 0.9
- minibatch size = 64
- λ = 0.01
電⼦透かし 256 bit (T = 256)
埋め込み対象 conv2 group
[4] S. Zagoruyko and N. Komodakis. Wide residual networks. In Proc. of ECCV, 2016.
conv1
conv2
group
conv3
group
conv4
group
arg-pool
fc
M= 36864(3 x 3 x 64 x 64 )](https://image.slidesharecdn.com/embeddingwatermarksintodeepneuralnetworks-170809071228/85/Embedding-Watermarks-into-Deep-Neural-Networks-23-320.jpg)

![! モデル圧縮で透かしが消えるか?
" lossless : Huffman cording [5]
" lossy : weight quantization[5, 6], parameter pruning [5, 6]
Robustness: model compression
[5] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural networks with pruning, trained
quantization and huffman coding. In Proc. of ICLR, 2016.
[6] S. Han, J. Pool, J. Tran, and W. J. Dally. Learning both weights and connections for efficient neural networks.
In Proc. of NIPS, 2015.](https://image.slidesharecdn.com/embeddingwatermarksintodeepneuralnetworks-170809071228/85/Embedding-Watermarks-into-Deep-Neural-Networks-28-320.jpg)

![! It is well-known that deep neural networks have many local
minima, and all local minima are almost optimal [8, 9].
Why Did Our Approach Work So Well?
[7] A. Choromanska et al. The loss surfaces of multilayer networks. In Proc. of AISTATS, 2015.
[8] Y. Dauphin et al. Identifying and attacking the saddle point problem in high-dimensional non-convex
optimization. In Proc. of NIPS, 2014.
Loss
Parameter space
Standard SGD](https://image.slidesharecdn.com/embeddingwatermarksintodeepneuralnetworks-170809071228/85/Embedding-Watermarks-into-Deep-Neural-Networks-31-320.jpg)
![! It is well-known that deep neural networks have many local
minima, and all local minima are almost optimal [8, 9].
! Our embedding regularizer guides model parameters toward
a local minima, which has the desired watermark.
! Let us assume that we want to
embed the watermark “11”…
Why Did Our Approach Work So Well?
[7] A. Choromanska et al. The loss surfaces of multilayer networks. In Proc. of AISTATS, 2015.
[8] Y. Dauphin et al. Identifying and attacking the saddle point problem in high-dimensional non-convex
optimization. In Proc. of NIPS, 2014.
Loss
Parameter space
00 01 10 11
Detected
watermark
Standard SGD
SGD with
Embedding Loss](https://image.slidesharecdn.com/embeddingwatermarksintodeepneuralnetworks-170809071228/85/Embedding-Watermarks-into-Deep-Neural-Networks-32-320.jpg)









![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)












![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)






























