Deep Learningとその⾃自然⾔言語処理理への応⽤用
l DeepLearningとは
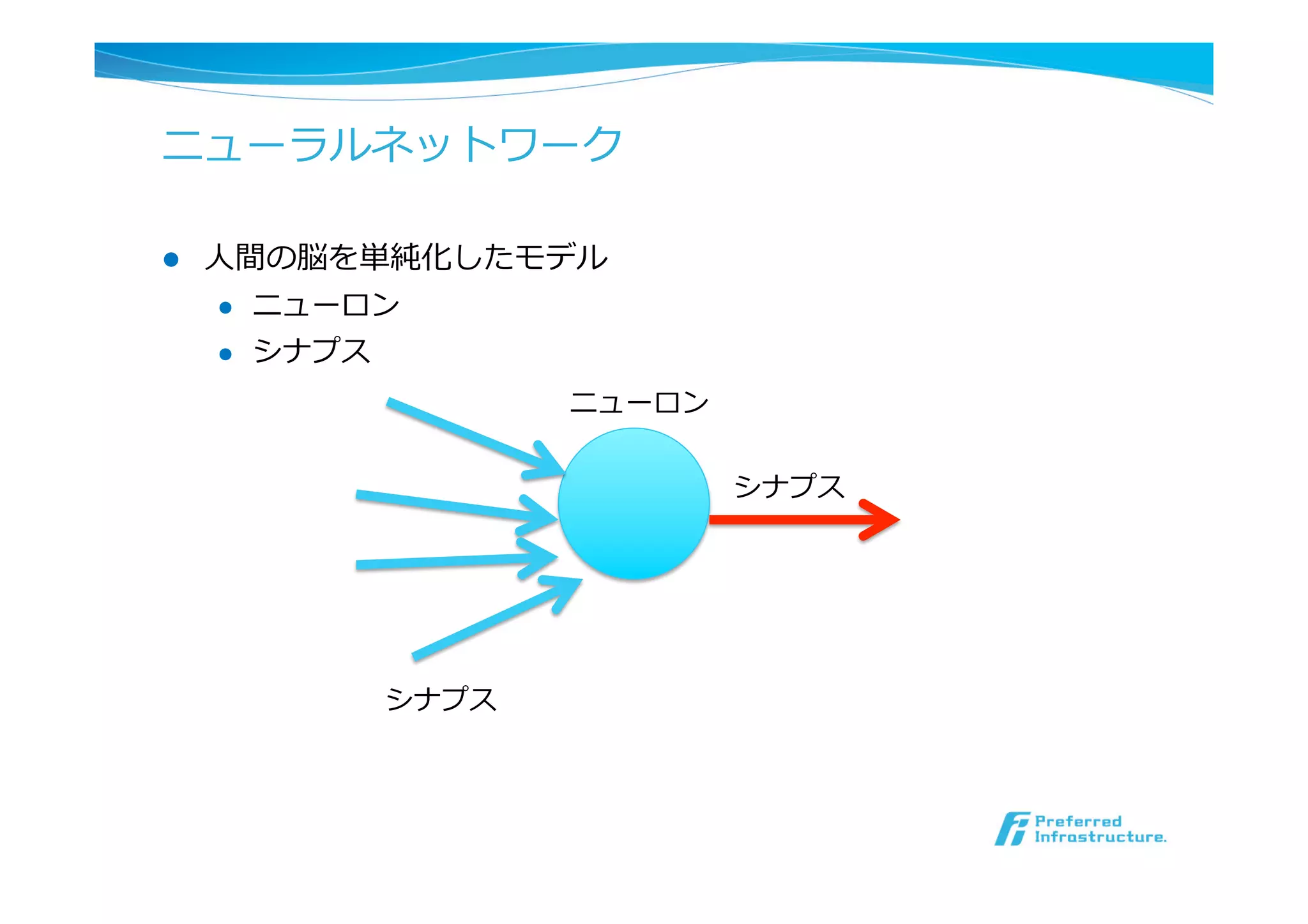
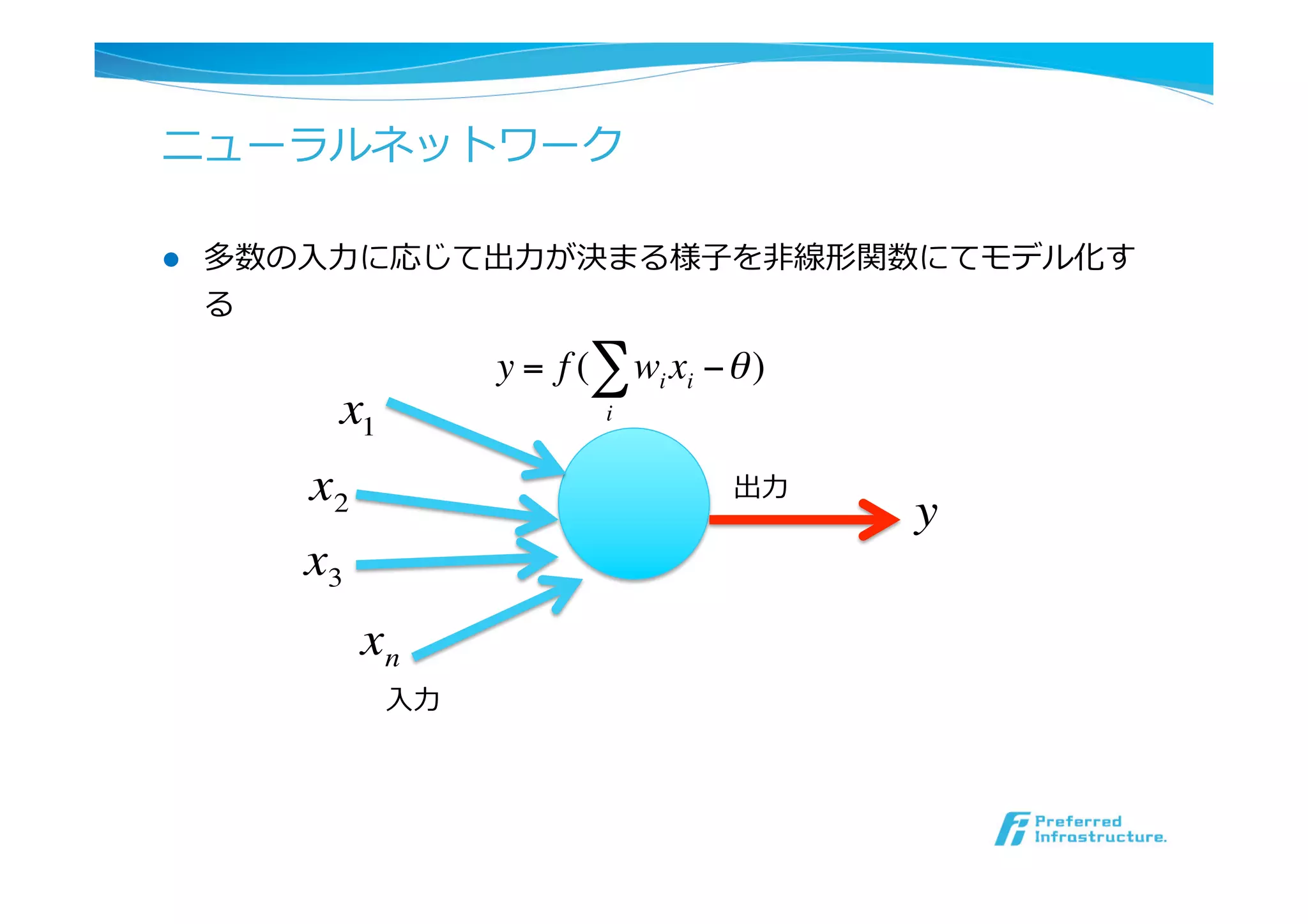
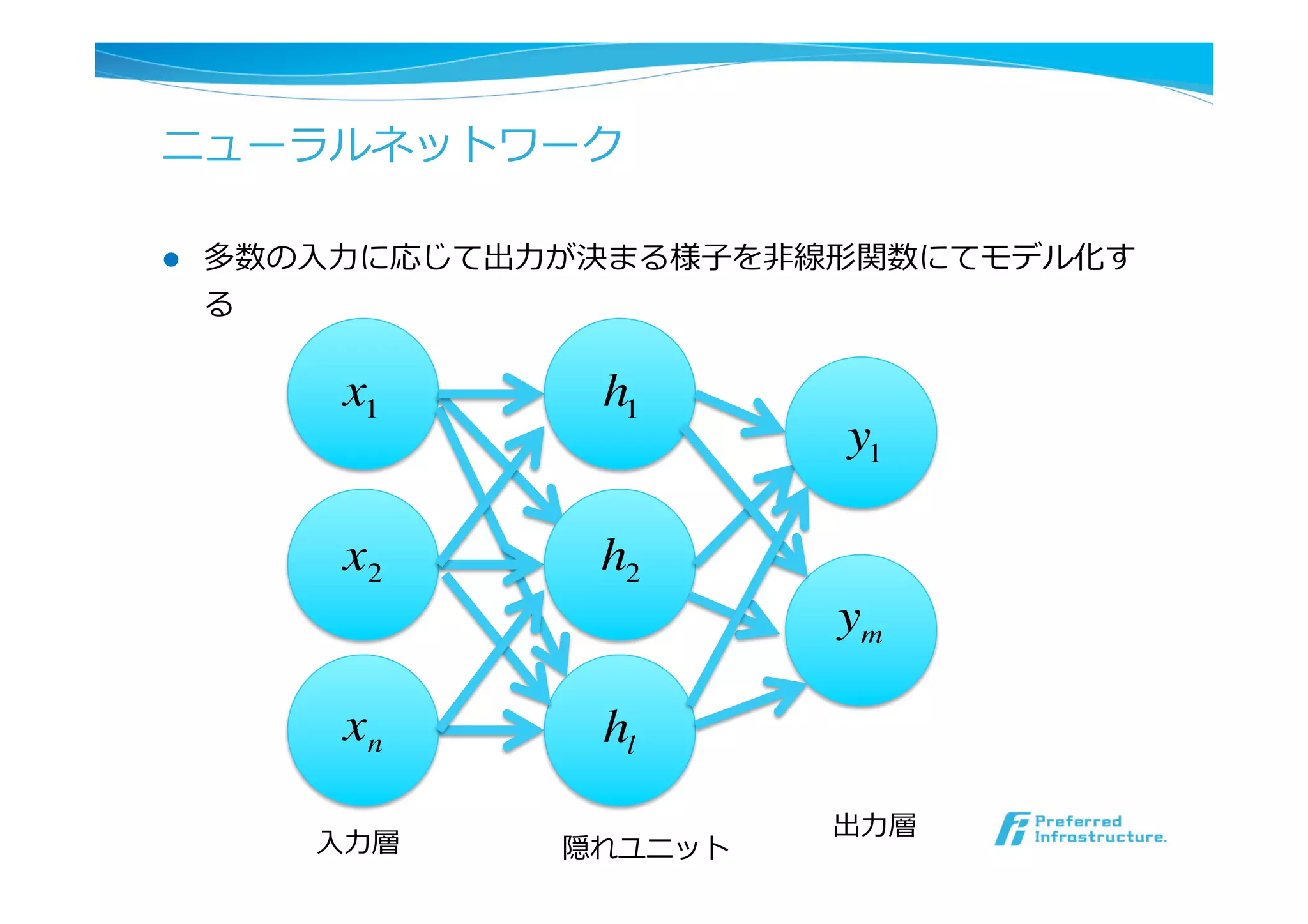
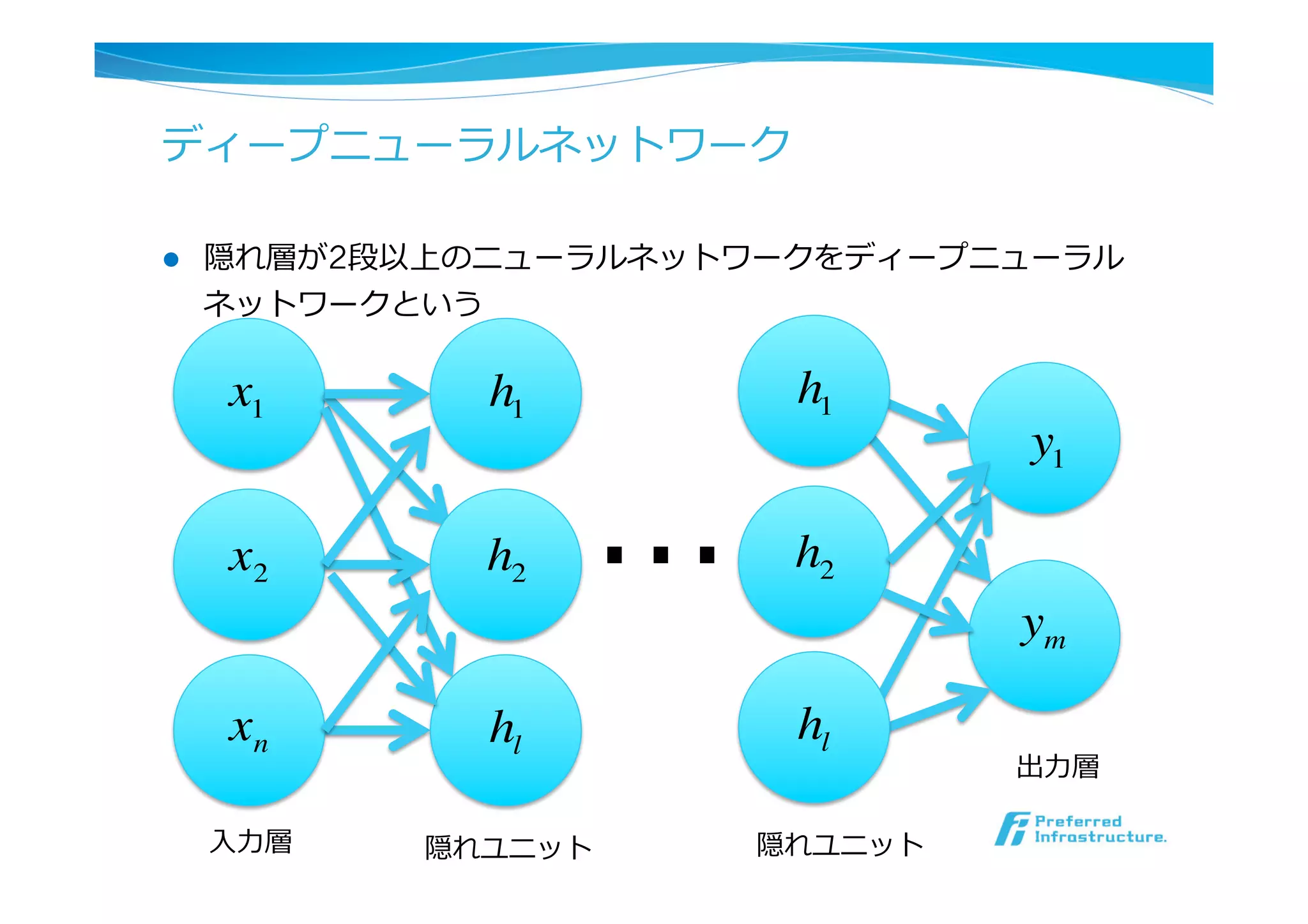
l ニューラルネットワーク
l Deep Learning
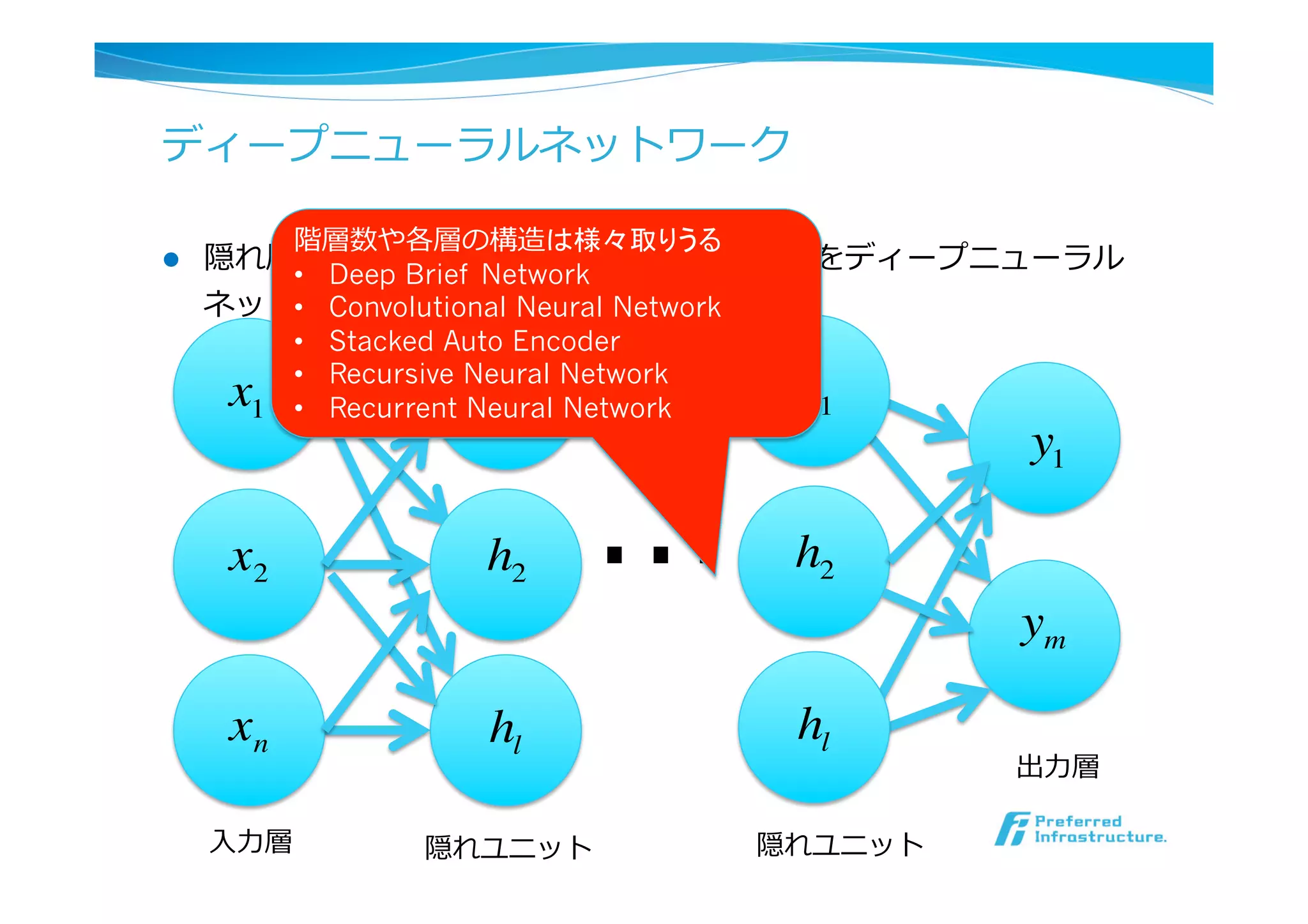
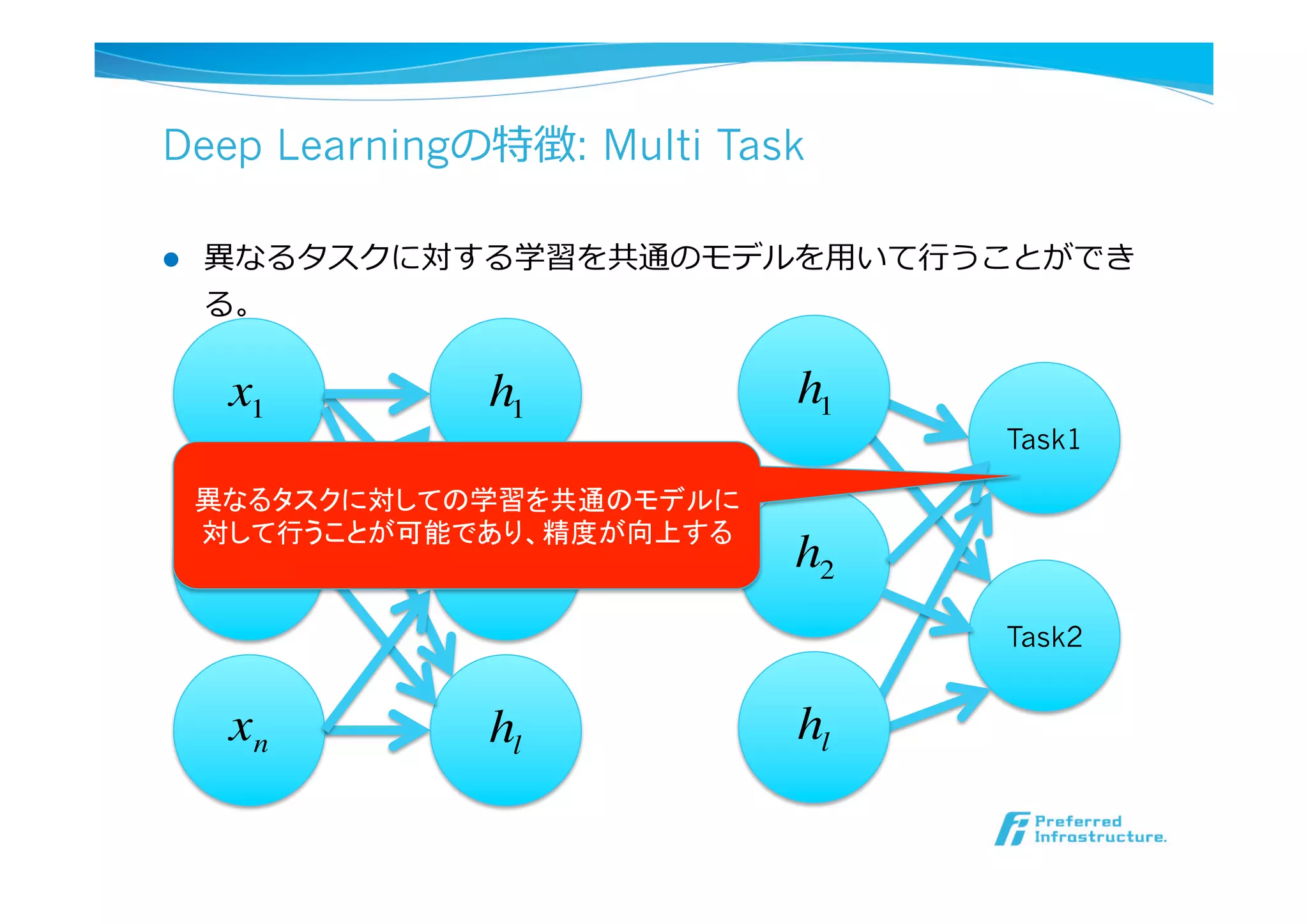
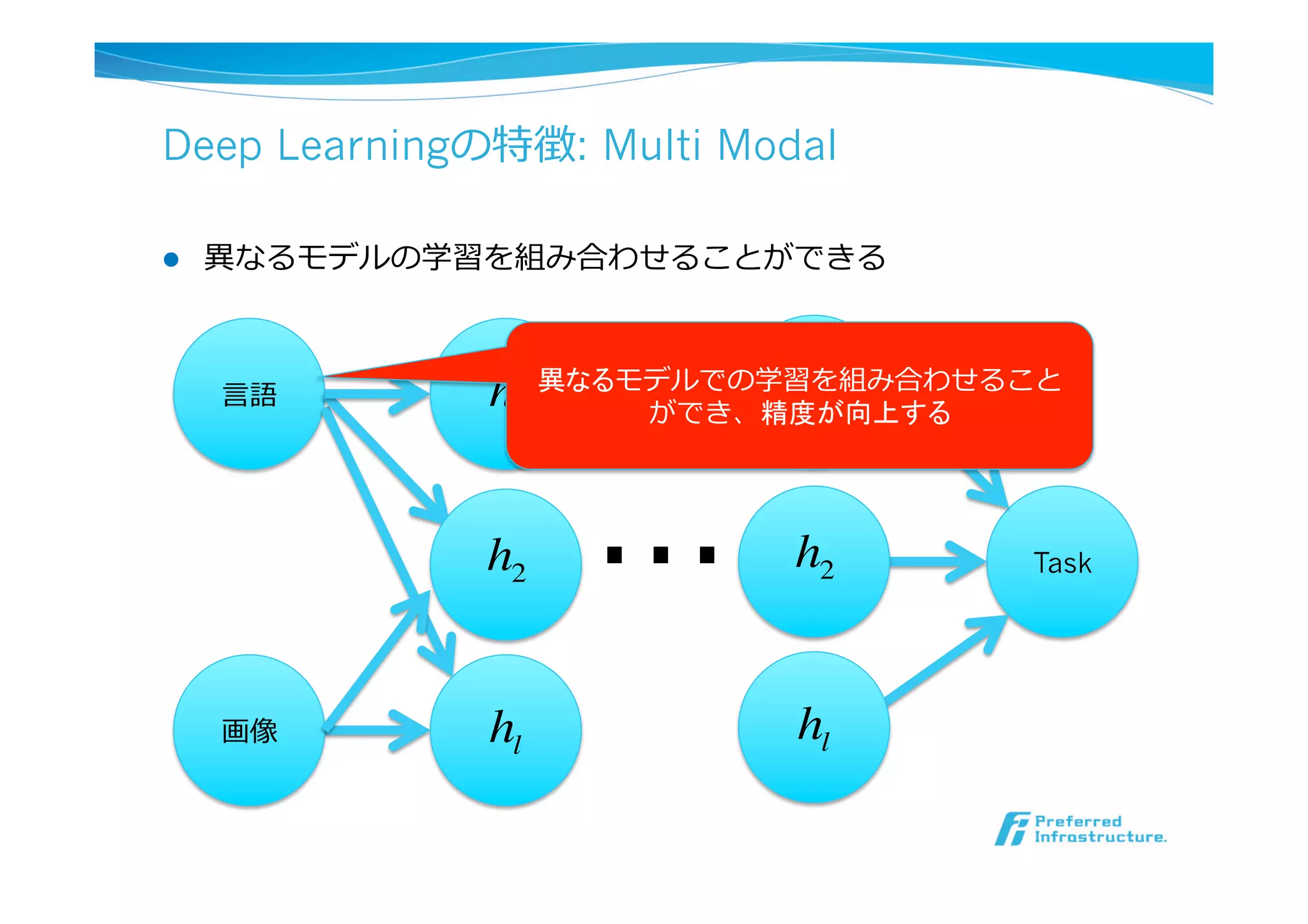
l Deep Learningの特徴
l Deep Learningの⾃自然⾔言語処理理への応⽤用
l NLPの基本タスク
l Word embedding
l ⽂文書分類
l Deep?
8.
Deep Learningとその⾃自然⾔言語処理理への応⽤用
l DeepLearningとは
l ニューラルネットワーク
l Deep Learning
l Deep Learningの特徴
l Deep Learningの⾃自然⾔言語処理理への応⽤用
l NLPの基本タスク
l Word embedding
l ⽂文書分類
l Deep?
Deep Learningとその⾃自然⾔言語処理理への応⽤用
l DeepLearningとは
l ニューラルネットワーク
l Deep Learning
l Deep Learningの特徴
l Deep Learningの⾃自然⾔言語処理理への応⽤用
l NLPの基本タスク
l Word embedding
l ⽂文書分類
l Deep?
19.
⾃自然⾔言語処理理の基本タスクを⾏行行うフレームワーク
(Collobert, et al.2013)
l ⾃自然⾔言語処理理の基本タスクを統⼀一的に扱うフレームワーク
l 品詞タグ付け
l チャンキング
l 固有表現抽出
l semantic role labeling
l 全てのタスクでそれまでの代表的な⼿手法と同程度度の精度度を達成
l Deep Learningのmulti taskの活かしてモデルを統⼀一
l 品詞タグ付けとSemantic role labelingにおいて判定は圧倒的に⾼高
速
20.
単語の表現⽅方法
l 学習データ
l 教師データ
l その他ラベル無しの⼤大量量データ
l Wikipedia
l Reuters RCV1
l 単語を50次元のベクトルに埋め込
む
All the Guys
Input Sentence
Lookup Table
Convolution
Max Over Time
Linear
HardTanh
Linear
Text The cat sat on the mat
Feature 1 w1
1 w1
2 . . . w1
N
...
Feature K wK
1 wK
2 . . . wK
N
LTW 1
...
LTW K
max(·)
M2
⇥ ·
M3
⇥ ·
d
Padding
Padding
n1
hu
M1
⇥ ·
n1
hu
n2
hu
n3
hu = #tags
Figure 2: Sentence approach network.
21.
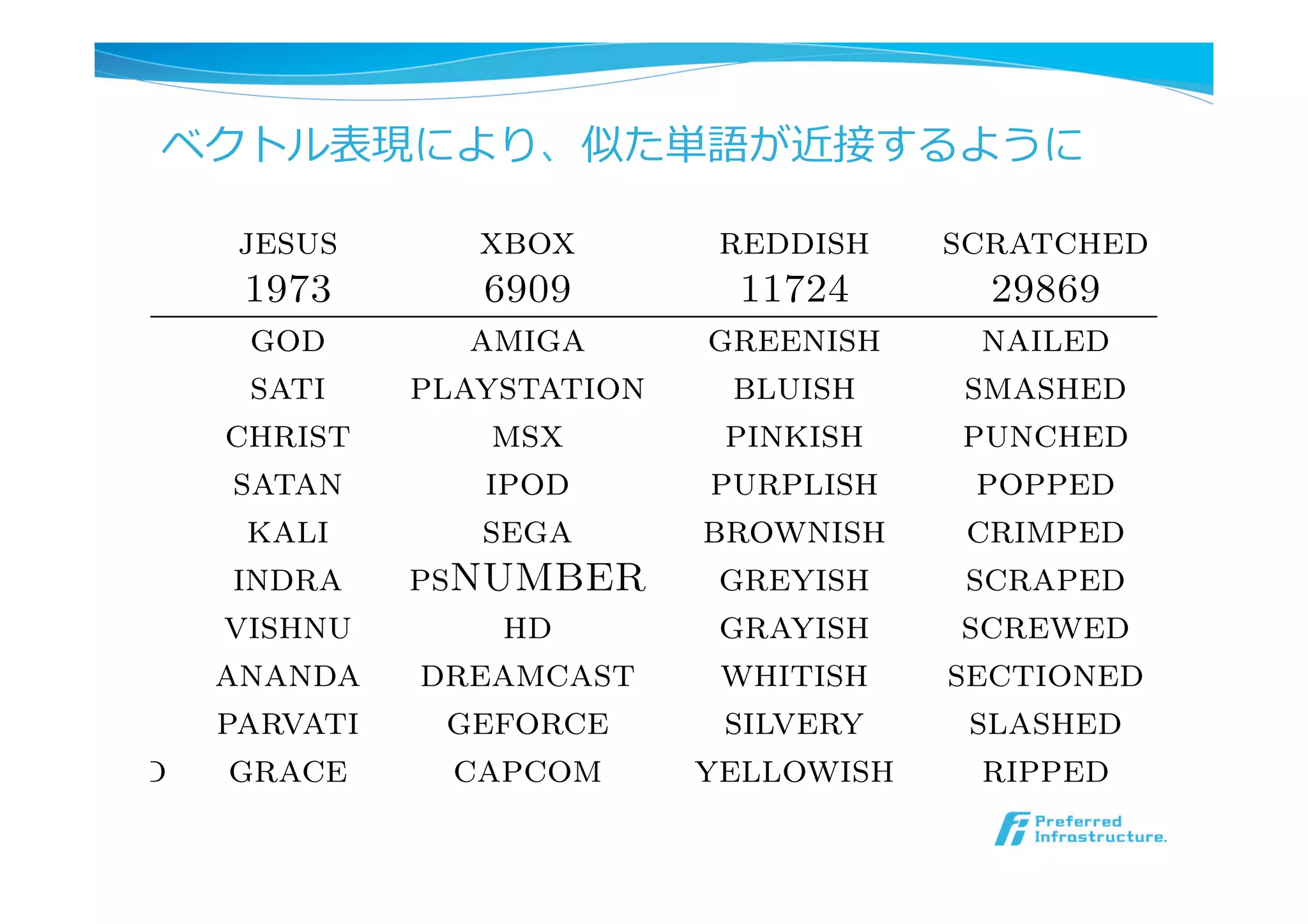
ベクトル表現により、似た単語が近接するように
Natural Language Processing(almost) from Scratch
rance jesus xbox reddish scratched mega
454 1973 6909 11724 29869 870
ustria god amiga greenish nailed oct
elgium sati playstation bluish smashed mb
ermany christ msx pinkish punched bit
italy satan ipod purplish popped bau
reece kali sega brownish crimped car
weden indra psNUMBER greyish scraped kbit
orway vishnu hd grayish screwed megah
urope ananda dreamcast whitish sectioned megap
ungary parvati geforce silvery slashed gbit
tzerland grace capcom yellowish ripped ampe
Word embeddings in the word lookup table of the language model neu
22.
隠れ層
l Window Approach
l 前後の単語の情報が単語のタグ
に影響すると仮定し、前後の単
語情報も含めて学習する
l Time Delay Networks
l Window Approachに加え、畳
み込みを⾏行行うことによって⽂文書
全体での情報も学習する
All the Guys
Input Sentence
Lookup Table
Convolution
Max Over Time
Linear
HardTanh
Linear
Text The cat sat on the mat
Feature 1 w1
1 w1
2 . . . w1
N
...
Feature K wK
1 wK
2 . . . wK
N
LTW 1
...
LTW K
max(·)
M2
⇥ ·
M3
⇥ ·
d
Padding
Padding
n1
hu
M1
⇥ ·
n1
hu
n2
hu
n3
hu = #tags
Figure 2: Sentence approach network.
23.
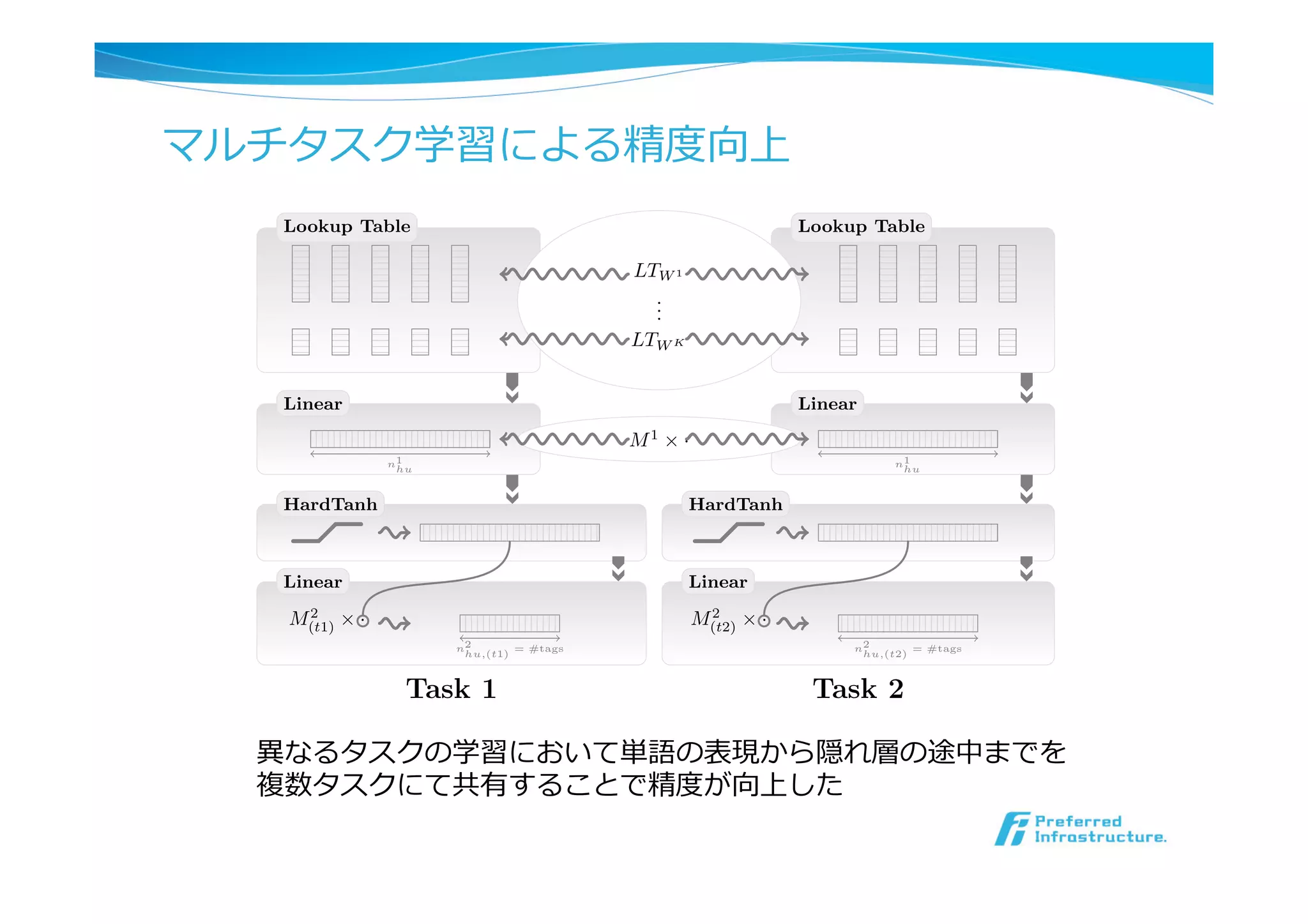
マルチタスク学習による精度度向上
Natural Language Processing(almost) from Scratch
Lookup Table
Linear
Lookup Table
Linear
HardTanh HardTanh
Linear
Task 1
Linear
Task 2
M2
(t1) ⇥ · M2
(t2) ⇥ ·
LTW 1
...
LTW K
M1
⇥ ·
n1
hu n1
hu
n2
hu,(t1)
= #tags n2
hu,(t2)
= #tags
Figure 3: Example of multitasking with NN. Task 1 and Task 2 are two tasks trained with
the architecture presented in Figure 1. Lookup tables as well as the first hidden layer are
shared. The last layer is task specific. The principle is the same with more than two tasks.
Approach POS CHUNK NER
(PWA) (F1) (F1)
異異なるタスクの学習において単語の表現から隠れ層の途中までを
複数タスクにて共有することで精度度が向上した
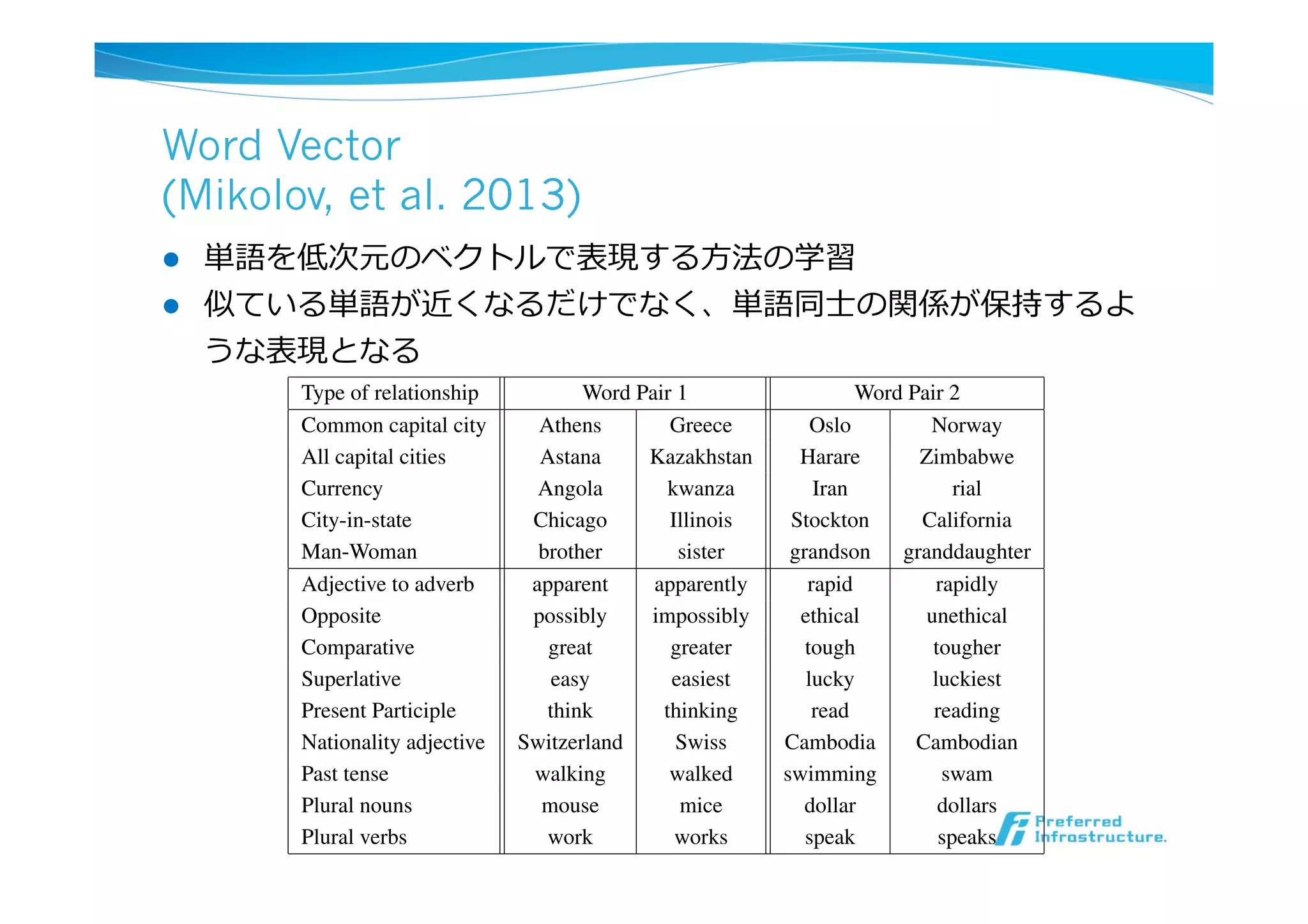
Word Vector
(Mikolov, etal. 2013)
l 単語を低次元のベクトルで表現する⽅方法の学習
l 似ている単語が近くなるだけでなく、単語同⼠士の関係が保持するよ
うな表現となる
Table 1: Examples of five types of semantic and nine types of syntactic questions in the Semantic-
Syntactic Word Relationship test set.
Type of relationship Word Pair 1 Word Pair 2
Common capital city Athens Greece Oslo Norway
All capital cities Astana Kazakhstan Harare Zimbabwe
Currency Angola kwanza Iran rial
City-in-state Chicago Illinois Stockton California
Man-Woman brother sister grandson granddaughter
Adjective to adverb apparent apparently rapid rapidly
Opposite possibly impossibly ethical unethical
Comparative great greater tough tougher
Superlative easy easiest lucky luckiest
Present Participle think thinking read reading
Nationality adjective Switzerland Swiss Cambodia Cambodian
Past tense walking walked swimming swam
Plural nouns mouse mice dollar dollars
Plural verbs work works speak speaks
4.1 Task Description
26.
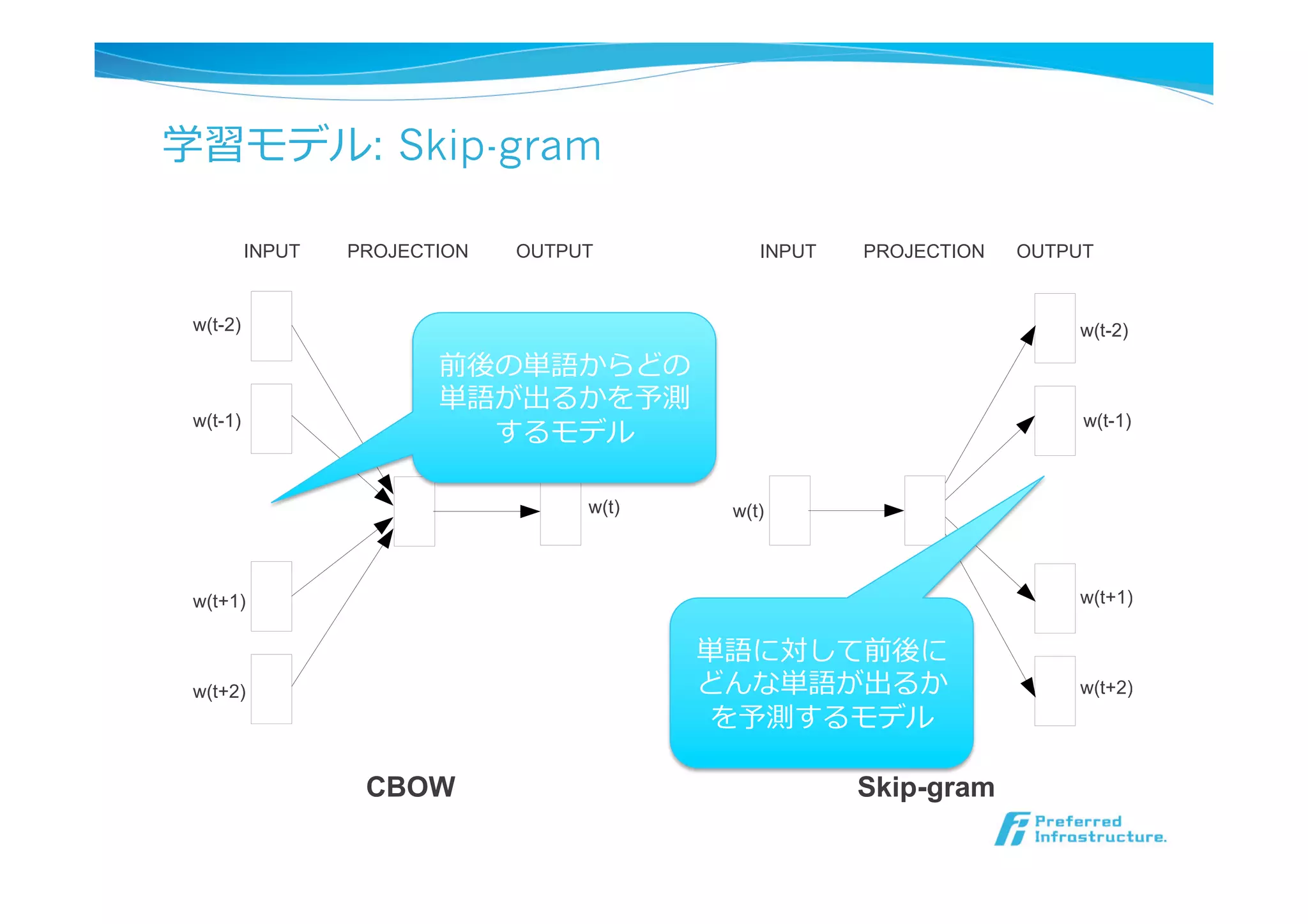
学習モデル: Skip-gram
w(t-2)
w(t+1)
w(t-1)
w(t+2)
w(t)
SUM
INPUT PROJECTIONOUTPUT
w(t)
INPUT PROJECTION OUTPUT
w(t-2)
w(t-1)
w(t+1)
w(t+2)
CBOW Skip-gram
Figure 1: New model architectures. The CBOW architecture predicts the current word based on the
単語に対して前後に
どんな単語が出るか
を予測するモデル
前後の単語からどの
単語が出るかを予測
するモデル
27.
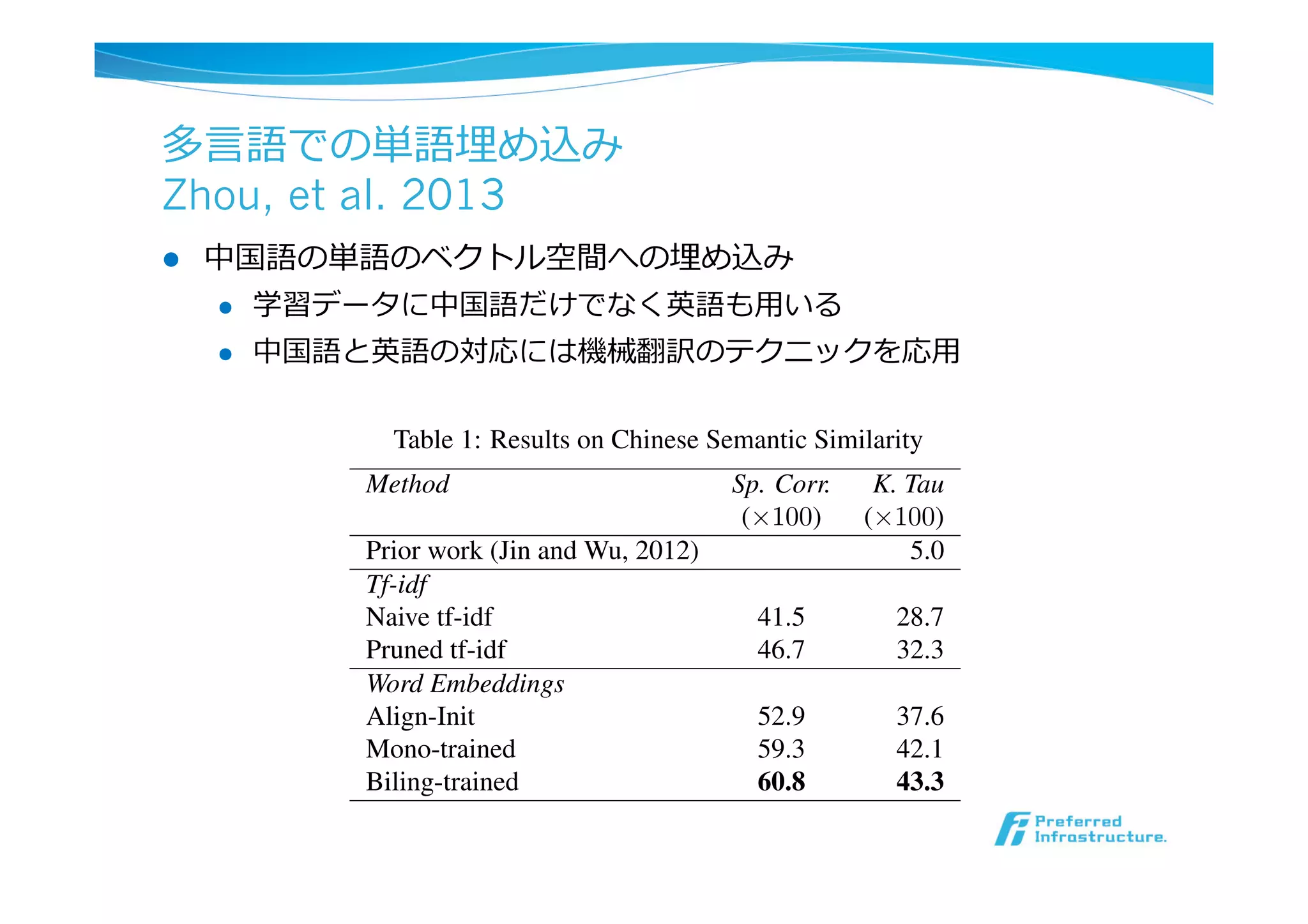
多⾔言語での単語埋め込み
Zhou, et al.2013
l 中国語の単語のベクトル空間への埋め込み
l 学習データに中国語だけでなく英語も⽤用いる
l 中国語と英語の対応には機械翻訳のテクニックを応⽤用
Table 1: Results on Chinese Semantic Similarity
Method Sp. Corr. K. Tau
(×100) (×100)
Prior work (Jin and Wu, 2012) 5.0
Tf-idf
Naive tf-idf 41.5 28.7
Pruned tf-idf 46.7 32.3
Word Embeddings
Align-Init 52.9 37.6
Mono-trained 59.3 42.1
Biling-trained 60.8 43.3
ganizers of SemEval-2012 Task 4. This test-set con-
Table 2: Results on Na
Embeddings Prec.
Align-Init 0.34
Mono-trained 0.54
Biling-trained 0.48
Table 3: Vector Matching A
ter)
Embeddings P
Mono-trained 0
Biling-trained 0
join optimization, is not
28.
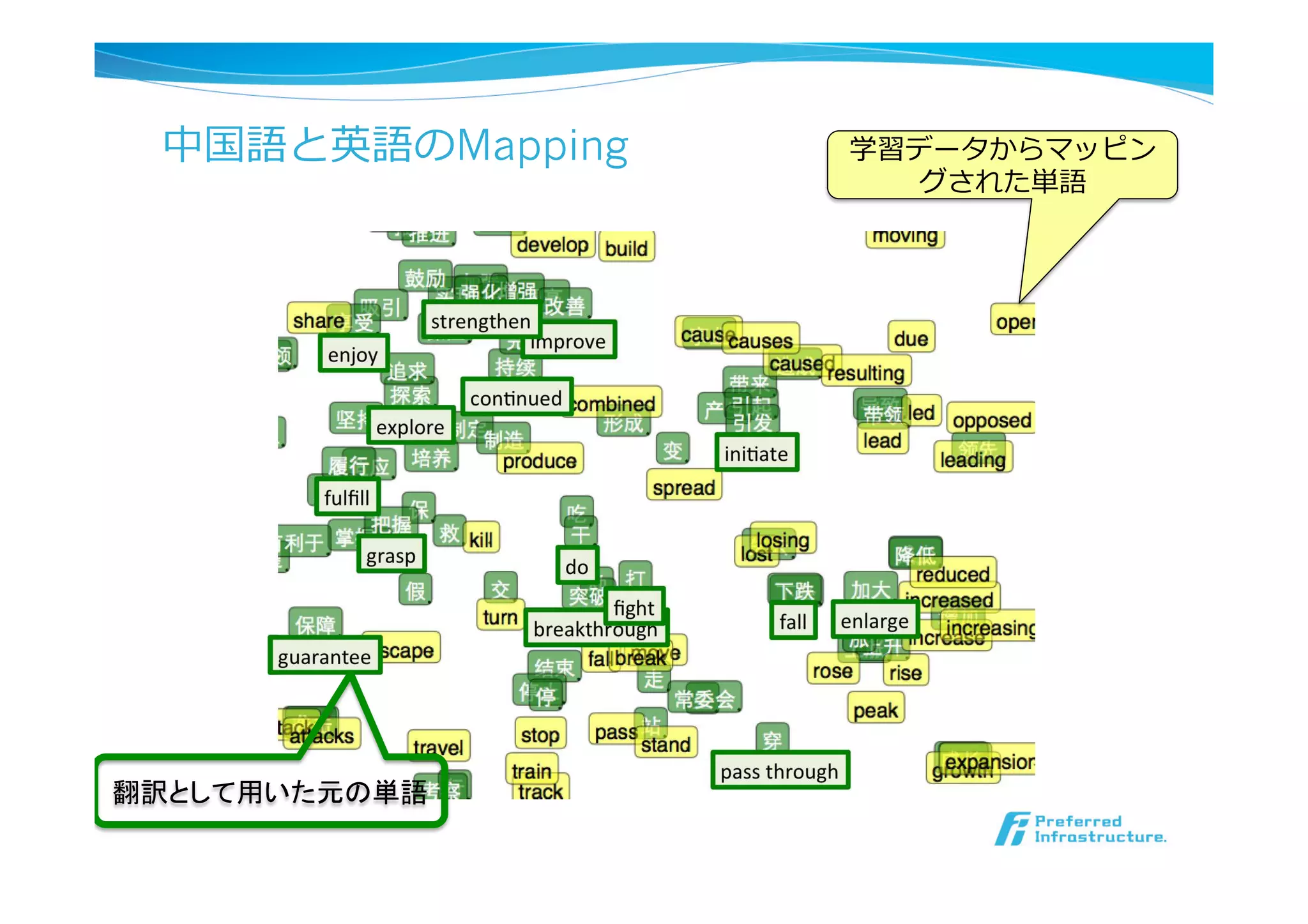
中国語と英語のMapping
edding, and the
Ven.With the
the Translation
zhVen∥2
(3)
enVzh∥2
(4)
ve during train-
optimize for:
h (5)
mize for:
n (6)
the value of λ
r both J and
sible, subsets of Chinese words are provided with
reference translations in boxes with green borders.
Words across the two languages are positioned by
the semantic relationships implied by their embed-
dings.
Figure 1: Overlaid bilingual embeddings: English words
are plotted in yellow boxes, and Chinese words in green;
翻訳として用いた元の単語
学習データからマッピン
グされた単語
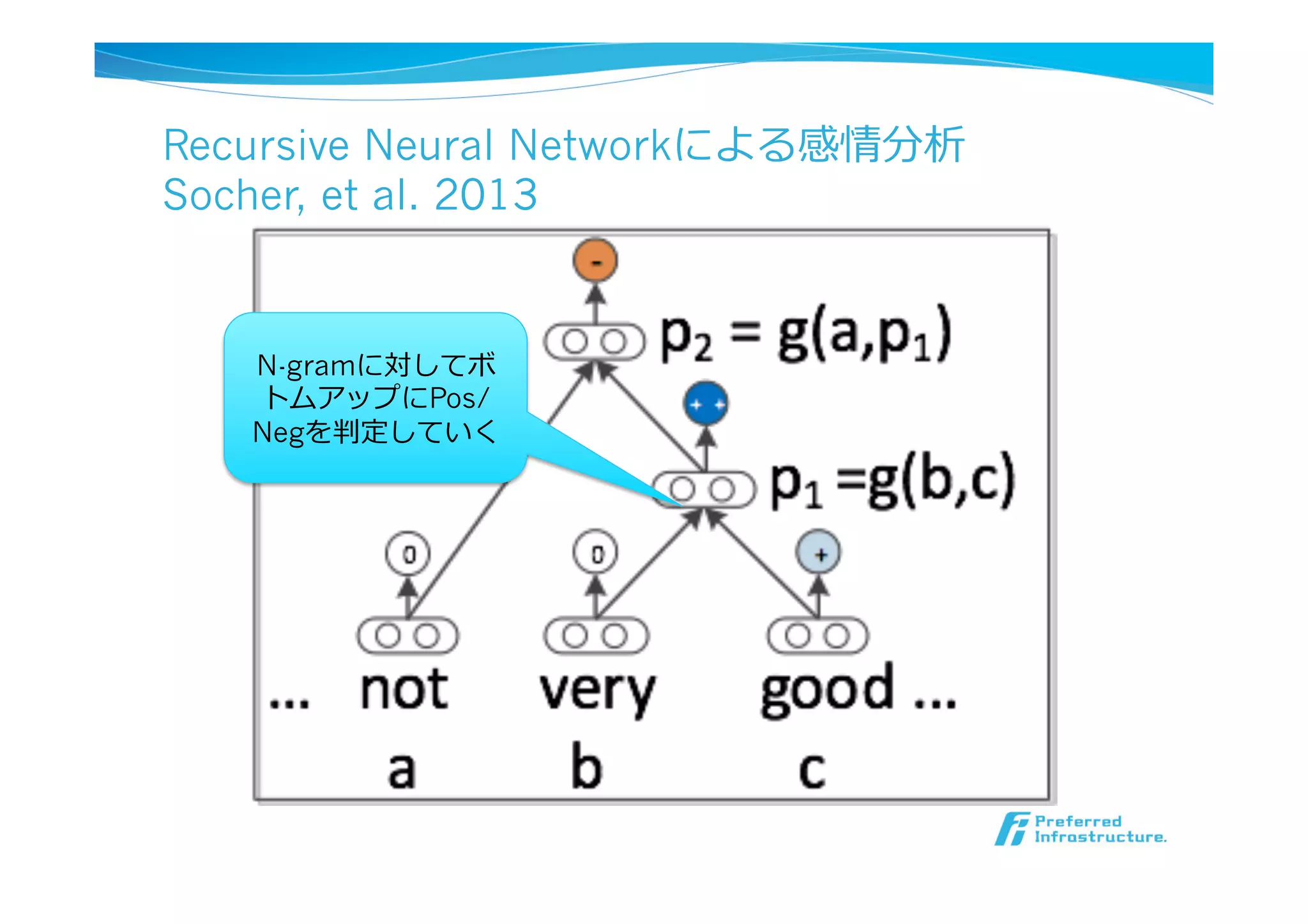
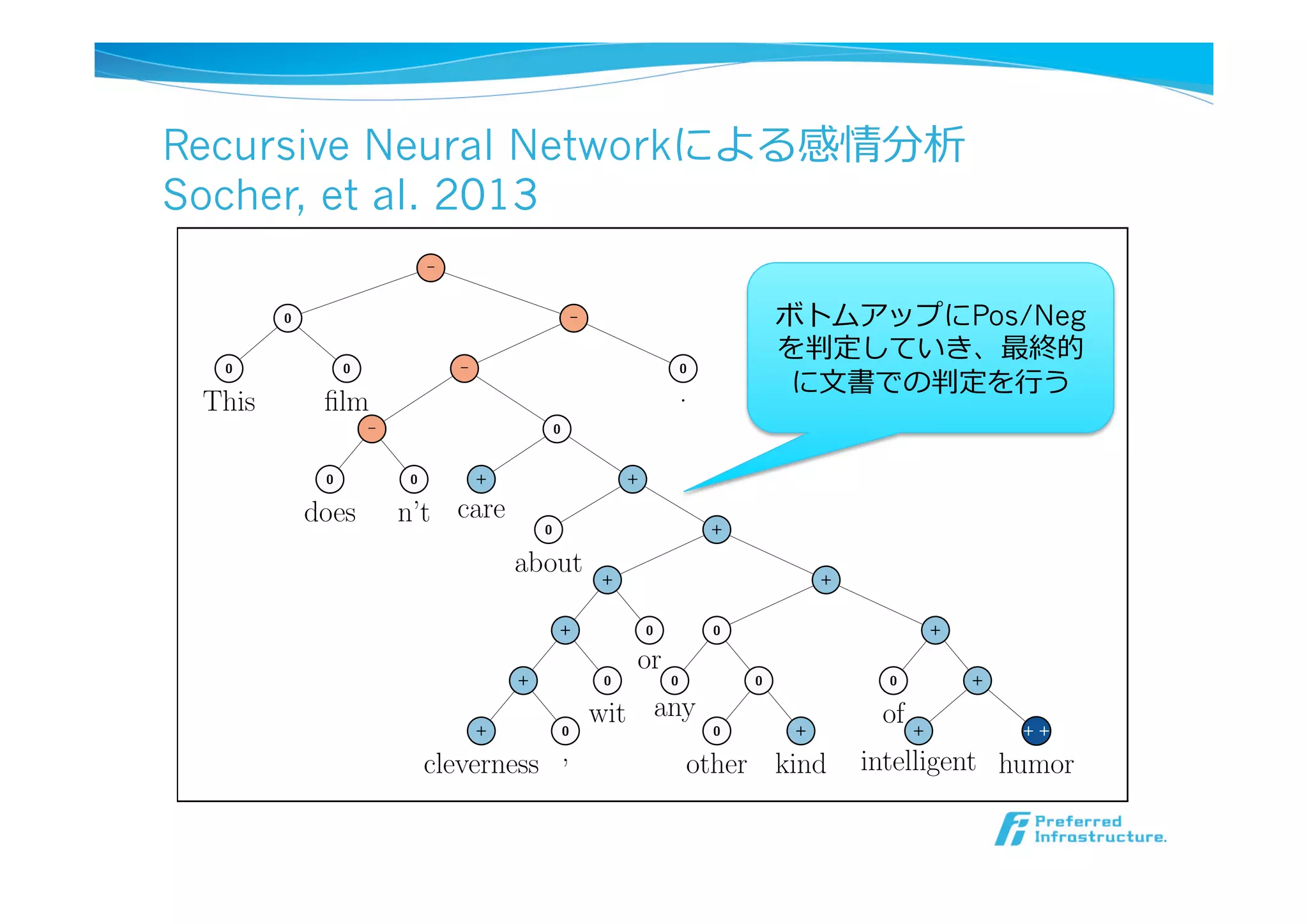
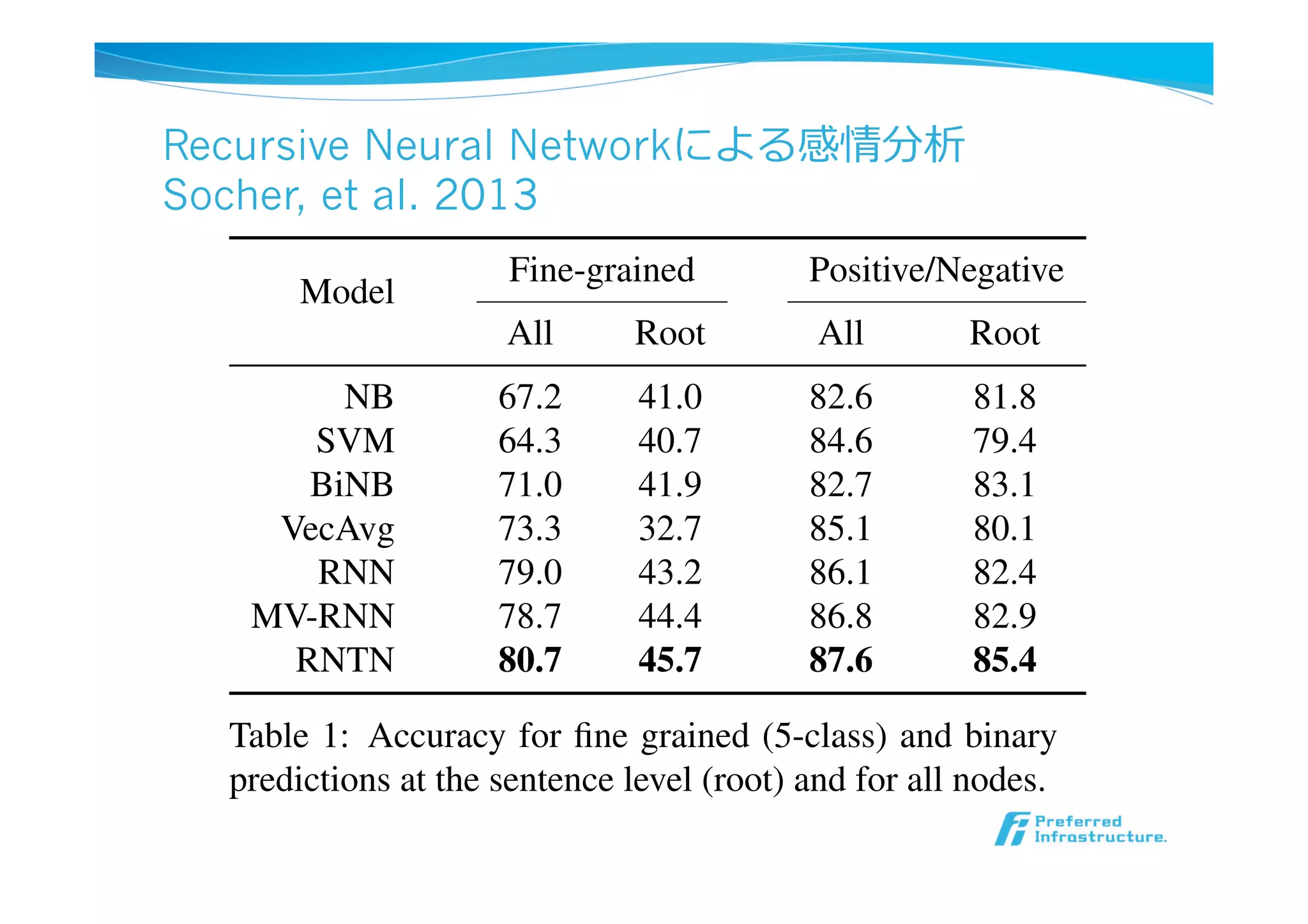
Recursive Neural Networkによる感情分析
Socher,et al. 2013
sity, Stanford, CA 94305, USA
relyg,jcchuang,ang}@cs.stanford.edu
ing,cgpotts}@stanford.edu
-
r
s
n
s
-
-
a
d
e
s
–
0
0
This
0
film
–
–
–
0
does
0
n’t
0
+
care
+
0
about
+
+
+
+
+
cleverness
0
,
0
wit
0
or
+
0
0
any
0
0
other
+
kind
+
0
of
+
+
intelligent
+ +
humor
0
.
Figure 1: Example of the Recursive Neural Tensor Net-
ボトムアップにPos/Neg
を判定していき、最終的
に⽂文書での判定を⾏行行う
31.
Recursive Neural Networkによる感情分析
Socher,et al. 2013
a
p1
◆
,
a
p1
half of this
message for
Model
Fine-grained Positive/Negative
All Root All Root
NB 67.2 41.0 82.6 81.8
SVM 64.3 40.7 84.6 79.4
BiNB 71.0 41.9 82.7 83.1
VecAvg 73.3 32.7 85.1 80.1
RNN 79.0 43.2 86.1 82.4
MV-RNN 78.7 44.4 86.8 82.9
RNTN 80.7 45.7 87.6 85.4
Table 1: Accuracy for fine grained (5-class) and binary
predictions at the sentence level (root) and for all nodes.
showed that the recursive models worked signifi-
32.
Deep Learningとその⾃自然⾔言語処理理への応⽤用
l DeepLearningとは
l ニューラルネットワーク
l Deep Learning
l Deep Learningの特徴
l Deep Learningの⾃自然⾔言語処理理への応⽤用
l NLPの基本タスク
l Word embedding
l ⽂文書分類
l Deep?
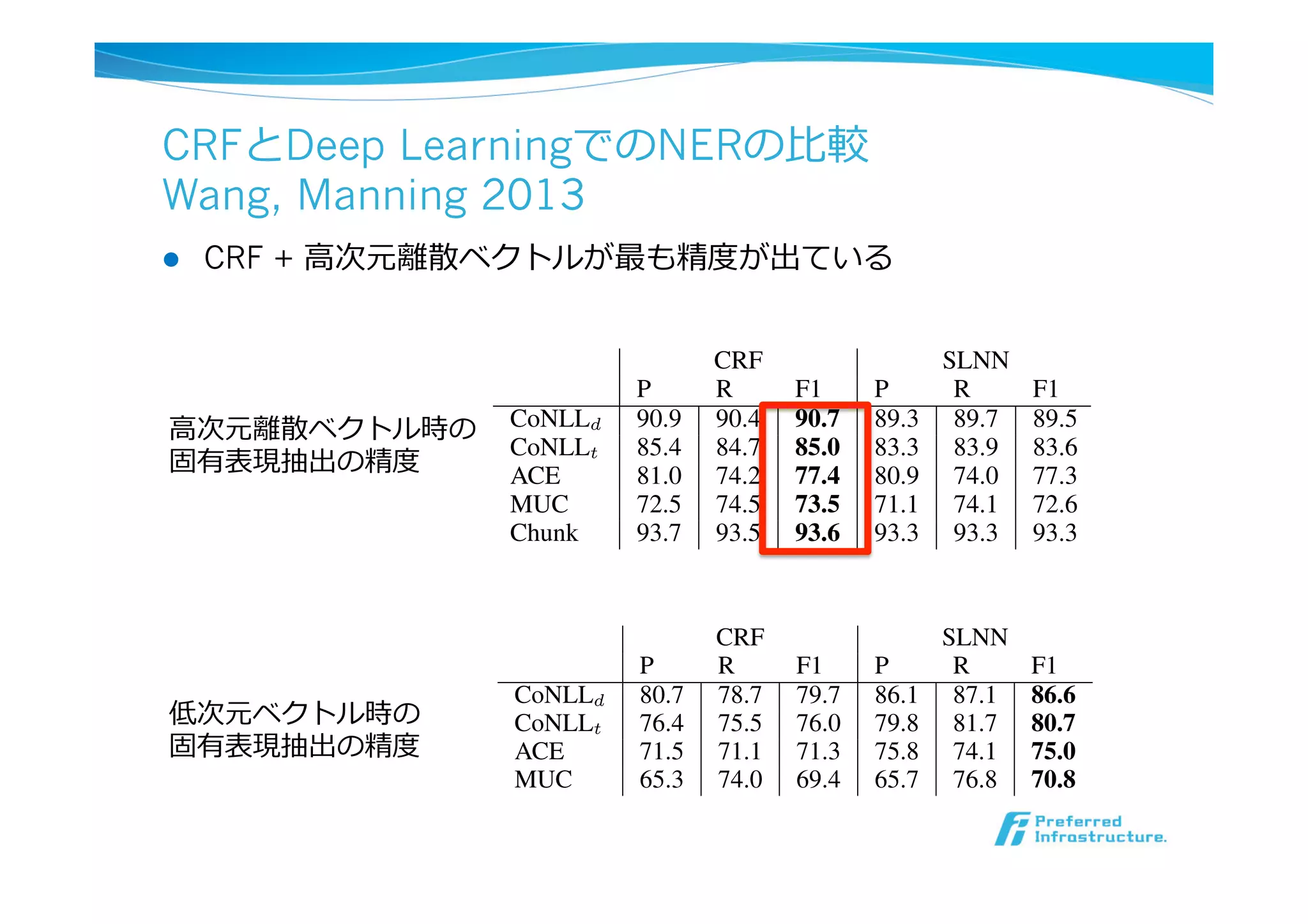
CRFとDeep LearningでのNERの⽐比較
Wang, Manning2013
l CRF + ⾼高次元離離散ベクトルが最も精度度が出ている
CRF SLNN
P R F1 P R F1
CoNLLd 90.9 90.4 90.7 89.3 89.7 89.5
CoNLLt 85.4 84.7 85.0 83.3 83.9 83.6
ACE 81.0 74.2 77.4 80.9 74.0 77.3
MUC 72.5 74.5 73.5 71.1 74.1 72.6
Chunk 93.7 93.5 93.6 93.3 93.3 93.3
Table 1: Results of CRF versus SLNN, over
discrete feature space. CoNLLd stands for the
CoNLL development set, and CoNLLt is the test
set. Best F1 score on each dataset is highlighted in
bold.
5.1 Results of Discrete Representation
The first question we address is the following:
CoNLLd
CoNLLt
ACE
MUC
Chunk
Table 2: Res
feature space
performance
ing.
A distinct
dimensional
sized text co
0.2 0.4 0.6 0.8 1
70
80
SLNN
CRF
Figure 2: The learning curve of SLNN vs. CRF
on CoNLL-03 dev set, with respect to the percent-
age of discrete features used (i.e., size of input di-
mension). Y-axis is the F1 score (out of 100), and
X-axis is the percentage of features used.
CRF SLNN
P R F1 P R F1
CoNLLd 80.7 78.7 79.7 86.1 87.1 86.6
CoNLLt 76.4 75.5 76.0 79.8 81.7 80.7
ACE 71.5 71.1 71.3 75.8 74.1 75.0
MUC 65.3 74.0 69.4 65.7 76.8 70.8
Table 3: Results of CRF versus SLNN, over con-
tinuous space feature representations.
SLNNcontinuou
SLNNjoin
Table 4: Res
embeddings
Numbers sho
provements
written digit
al., 2009; Do
sionality is a
5.3 Combi
Featur
When we joi
tures, we see
especially in
sults are show
A similar e
al. (2010). T
SLNN increa
the CRF mod
performance
6 Conclus
⾼高次元離離散ベクトル時の
固有表現抽出の精度度
低次元ベクトル時の
固有表現抽出の精度度
35.
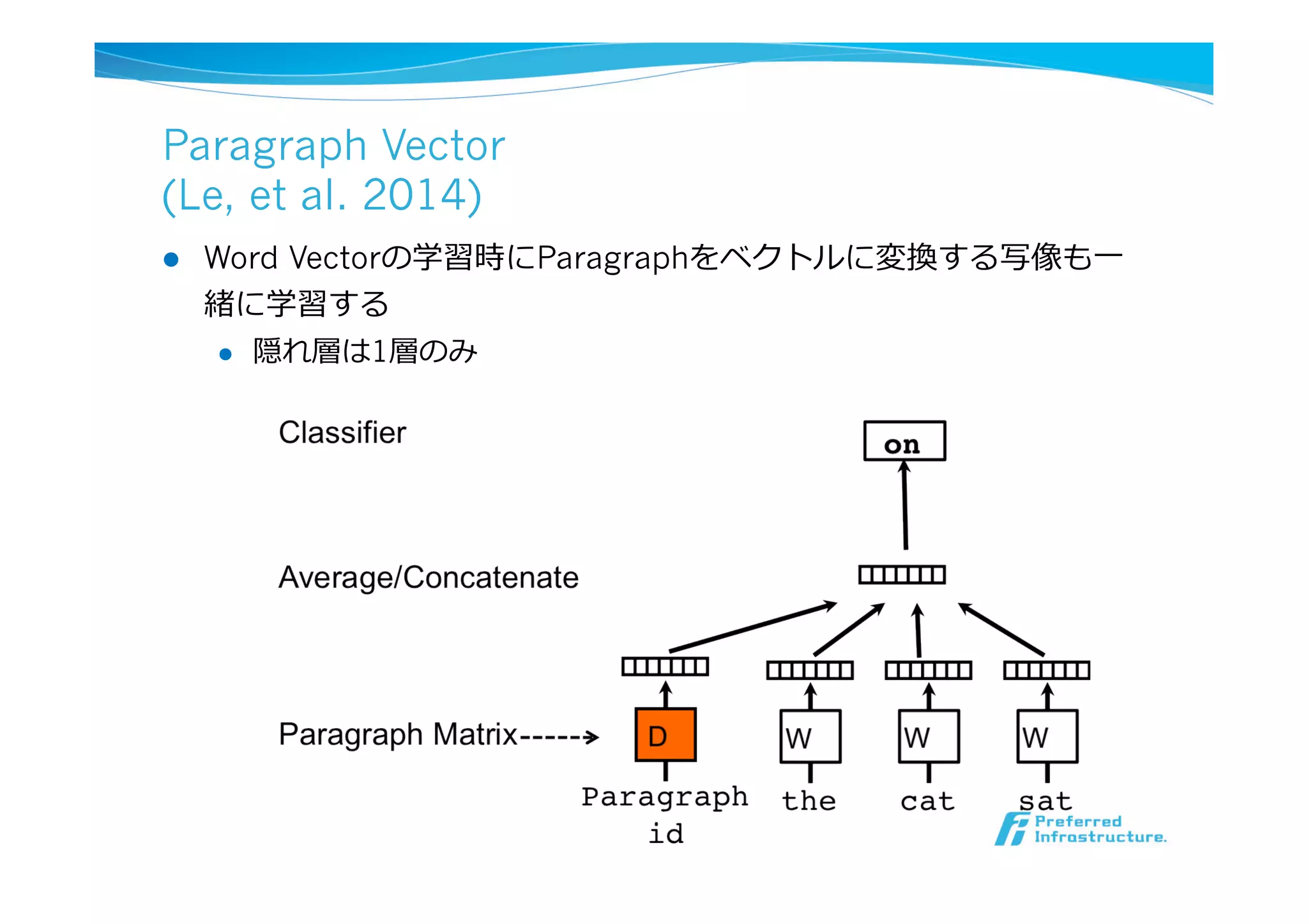
Paragraph Vector
(Le, etal. 2014)
l Word Vectorの学習時にParagraphをベクトルに変換する写像も⼀一
緒に学習する
l 隠れ層は1層のみ
2), natural lan-
n, 2008; Zhila
(Mikolov et al.,
anding (Frome
er et al., 2013a).
mory model
s is inspired by
The inspiration
bute to a predic-
nce. So despite
randomly, they
ect result of the
paragraph vec-
vectors are also
f the next word
graph.
igure 2), every
epresented by a
so mapped to a
matrix W. The
the softmax weights, are fixed.
Suppose that there are N paragraphs in the corpus, M
words in the vocabulary, and we want to learn paragraph
vectors such that each paragraph is mapped to p dimen-
sions and each word is mapped to q dimensions, then the
model has the total of N ⇥ p + M ⇥ q parameters (ex-
cluding the softmax parameters). Even though the number
of parameters can be large when N is large, the updates
during training are typically sparse and thus efficient.
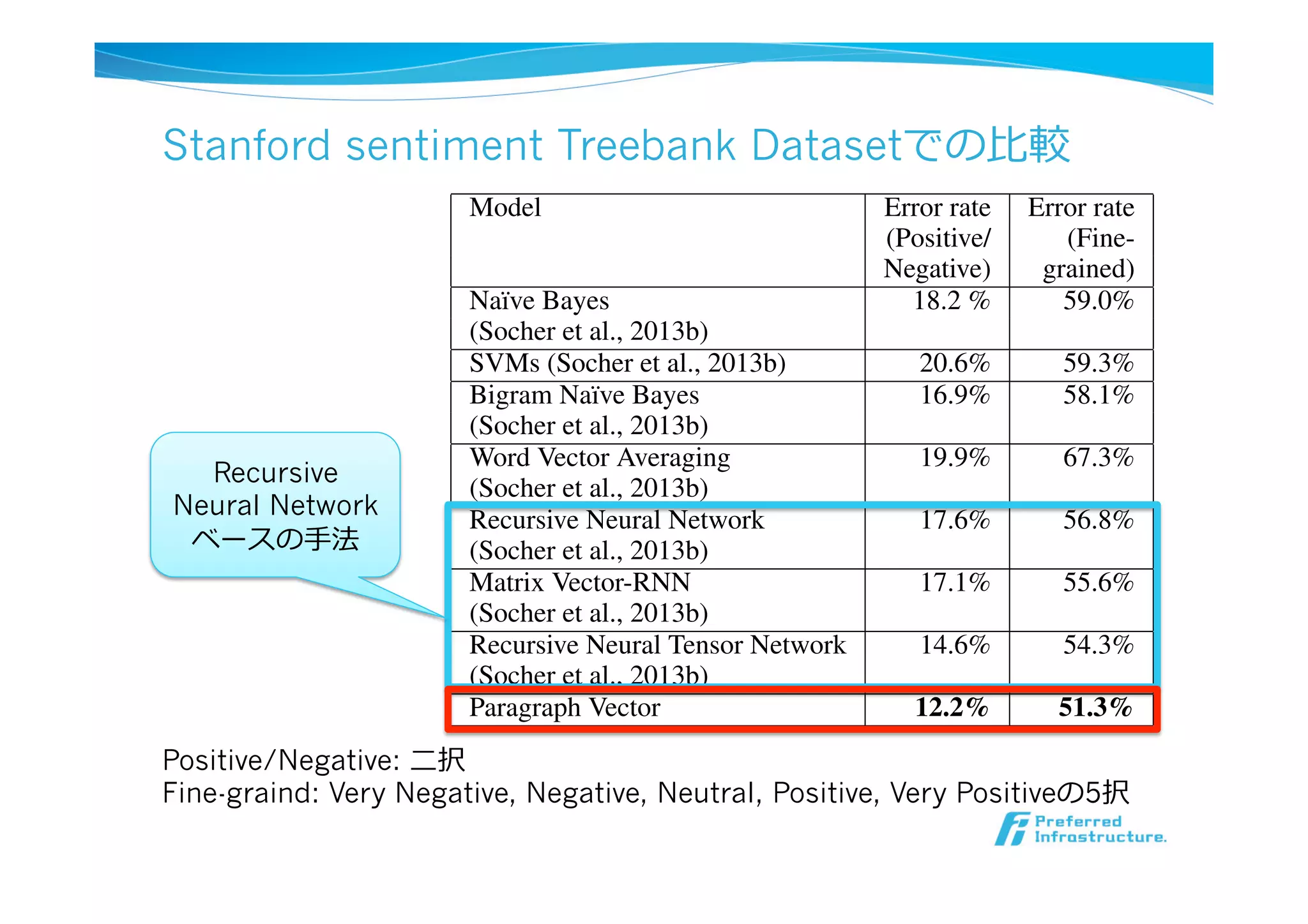
Stanford sentiment TreebankDatasetでの⽐比較
Distributed Representations of Sentences and Documents
(Socher et al., 2013b), the au-
benchmarking. First, one could
ined classification task where
ative, Negative, Neutral, Posi-
-way coarse-grained classifica-
are {Negative, Positive}. The
terms of whether we should la-
l phrases in the sentence. In this
eling the full sentences.
, 2013b) apply several methods
t their Recursive Neural Tensor
er than bag-of-words model. It
ecause movie reviews are often
plays an important role in de-
s positive or negative, as well as
oes given the rather tiny size of
We follow the experimental
Socher et al., 2013b). To make
d data, in our model, each sub-
ependent sentence and we learn
he subphrases in the training set.
Table 1. The performance of our method compared to other ap-
proaches on the Stanford Sentiment Treebank dataset. The error
rates of other methods are reported in (Socher et al., 2013b).
Model Error rate Error rate
(Positive/ (Fine-
Negative) grained)
Na¨ıve Bayes 18.2 % 59.0%
(Socher et al., 2013b)
SVMs (Socher et al., 2013b) 20.6% 59.3%
Bigram Na¨ıve Bayes 16.9% 58.1%
(Socher et al., 2013b)
Word Vector Averaging 19.9% 67.3%
(Socher et al., 2013b)
Recursive Neural Network 17.6% 56.8%
(Socher et al., 2013b)
Matrix Vector-RNN 17.1% 55.6%
(Socher et al., 2013b)
Recursive Neural Tensor Network 14.6% 54.3%
(Socher et al., 2013b)
Paragraph Vector 12.2% 51.3%
more advanced methods (such as Recursive Neural Net-
work (Socher et al., 2013b)), which require parsing and
take into account the compositionality, perform much bet-
Recursive
Neural Network
ベースの⼿手法
Positive/Negative: ⼆二択
Fine-graind: Very Negative, Negative, Neutral, Positive, Very Positiveの5択
38.
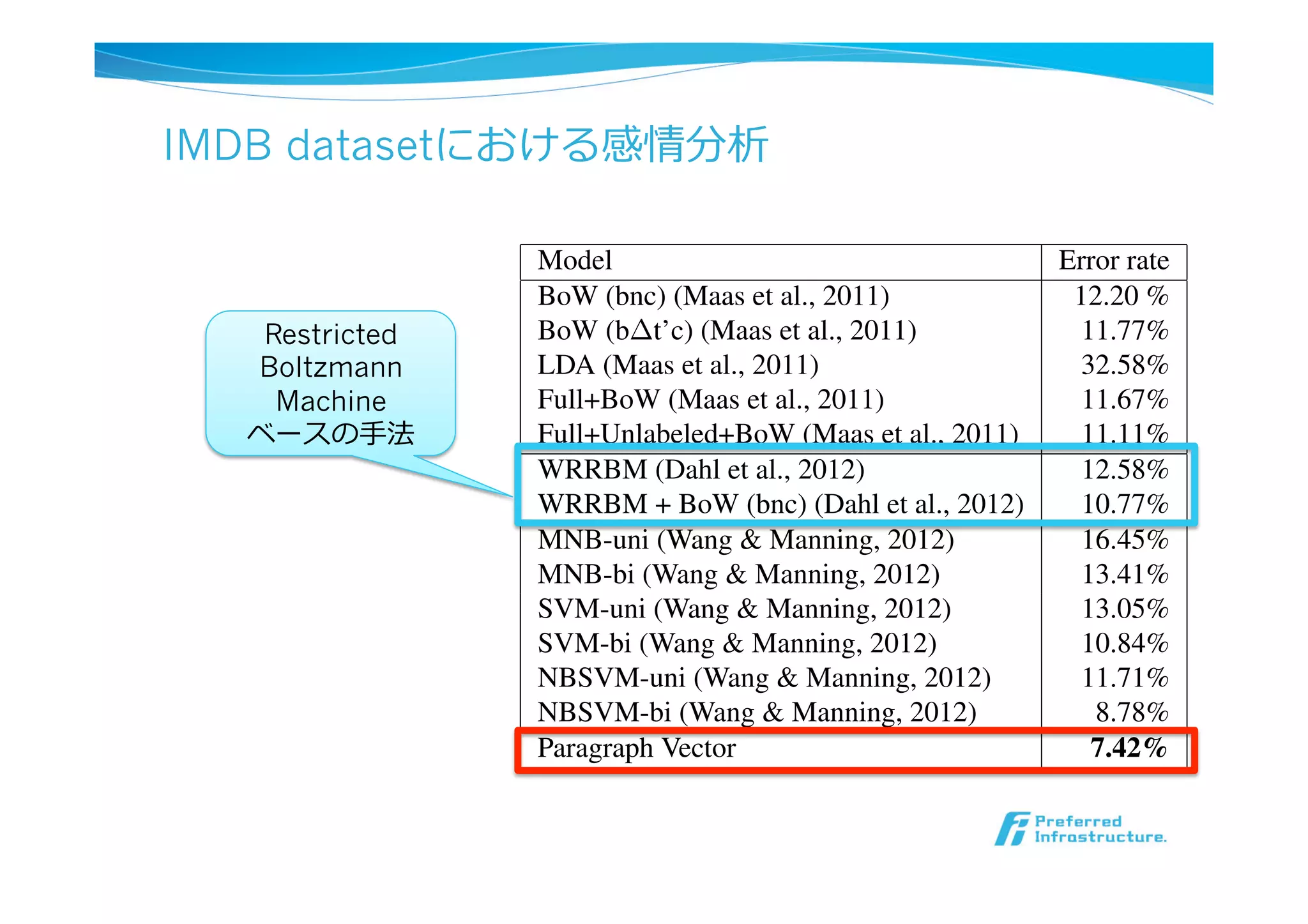
IMDB datasetにおける感情分析
aining instances,25,000 labeled test in-
0 unlabeled training instances. There are
s: Positive and Negative. These labels are
he training and the test set. The dataset
d at http://ai.Stanford.edu/
entiment/index.html
otocols: We learn the word vectors and
using 75,000 training documents (25,000
00 unlabeled instances). The paragraph
25,000 labeled instances are then fed
network with one hidden layer with 50
c classifier to learn to predict the senti-
n a test sentence, we again freeze the rest
d learn the paragraph vectors for the test
nt descent. Once the vectors are learned,
ugh the neural network to predict the sen-
ws.
ers of our paragraph vector model are se-
e manner as in the previous task. In par-
validate the window size, and the opti-
is 10 words. The vector presented to the
catenation of two vectors, one from PV-
rom PV-DM. In PV-DBOW, the learned
ions have 400 dimensions. In PV-DM,
It achieves 7.42% which is another 1.3% absolute improve-
ment (or 15% relative improvement) over the best previous
result of (Wang & Manning, 2012).
Table 2. The performance of Paragraph Vector compared to other
approaches on the IMDB dataset. The error rates of other methods
are reported in (Wang & Manning, 2012).
Model Error rate
BoW (bnc) (Maas et al., 2011) 12.20 %
BoW (b t’c) (Maas et al., 2011) 11.77%
LDA (Maas et al., 2011) 32.58%
Full+BoW (Maas et al., 2011) 11.67%
Full+Unlabeled+BoW (Maas et al., 2011) 11.11%
WRRBM (Dahl et al., 2012) 12.58%
WRRBM + BoW (bnc) (Dahl et al., 2012) 10.77%
MNB-uni (Wang & Manning, 2012) 16.45%
MNB-bi (Wang & Manning, 2012) 13.41%
SVM-uni (Wang & Manning, 2012) 13.05%
SVM-bi (Wang & Manning, 2012) 10.84%
NBSVM-uni (Wang & Manning, 2012) 11.71%
NBSVM-bi (Wang & Manning, 2012) 8.78%
Paragraph Vector 7.42%
3.3. Information Retrieval with Paragraph Vectors
We turn our attention to an information retrieval task which
Restricted
Boltzmann
Machine
ベースの⼿手法
39.
まとめ
l Deep Learningを⾃自然⾔言語処理理に⽤用いている例例を紹介
l POS, NER, Chunking, SRL, WSを統⼀一的に扱えるフレームワーク
l 他の⾔言語と組み合わせたWord Embedding
l ⽂文書分類
l Word embedding + 従来⼿手法(ロジスティック回帰、分類)を組み合
わせる事でも精度度が上がる例例も出ている
l Deep Learningで培われたテクニックをDeepではないところで使う
⽅方法もでている























![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/alpha-gan-inpl-180417074219-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)

























