Download as PDF, PPTX
































![Data Landscape
• The physical location of data - where stored / what environment - is a
significant cost factor for almost all aspects of analytical work.
!
• Distributed data (managed / located in multiple stores) increases costs for
many individual steps in analytical workflows.
!
• Distributed data costs often = barrier to conducting insightful analysis using
multiple techniques / steps. Default to basic / simple analysis to avoid high
effort / low probability of success.
!
• For analysts with low levels of db / data wrangling skill, even marginal
distributed data costs = preventative barrier for engaging with data.
!
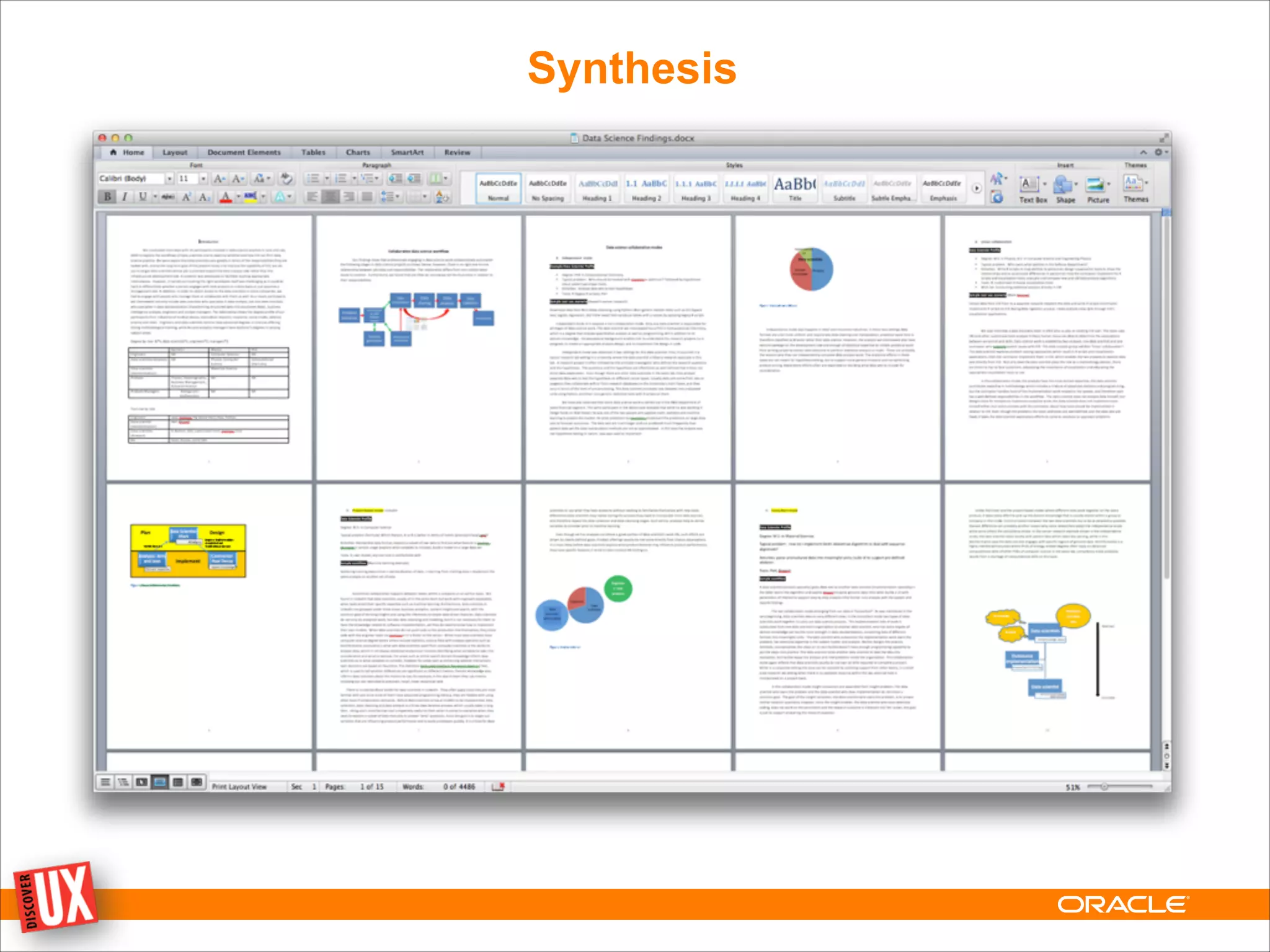
• Most analysts reported having to migrate all of the data sets into the same
data processing framework to begin analysis. [If all the data were in one
place...]](https://image.slidesharecdn.com/datasciencehighlightspubliccopy-140327155424-phpapp02/75/Data-Science-Highlights-44-2048.jpg)













Square is hiring a data scientist for its risk team, responsible for using machine learning and data mining to mitigate financial loss and identify suspicious activity. The role requires proficiency in Java, Python, or R, with responsibilities including investigating and building machine learning systems, creating visualizations, and collaborating with analysts and engineers. Candidates should have advanced analytical skills, knowledge of classification techniques, and the capability to communicate complex ideas effectively.