
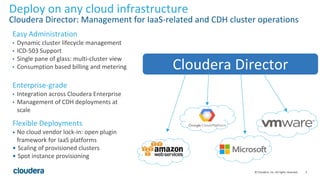

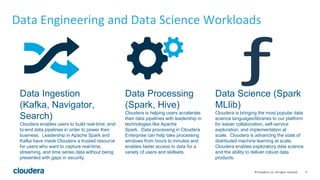


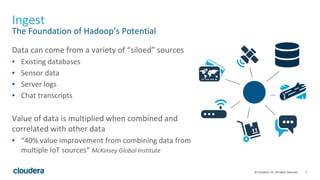







The document discusses the modernization of organizations through data science and emphasizes Cloudera's tools for managing and processing data across various platforms. It highlights the importance of bridging skill gaps in government data science and outlines use cases for decision science and data products. Additionally, it details the role of data ingestion, processing, and machine learning in enhancing data utilization and driving business value.






































![[Ai in finance] AI in regulatory compliance, risk management, and auditing](https://cdn.slidesharecdn.com/ss_thumbnails/aiinfinanceaiinregulatorycomplianceriskmanagementandauditing1-161109114320-thumbnail.jpg?width=640&height=640&fit=bounds)
































































