Downloaded 16 times









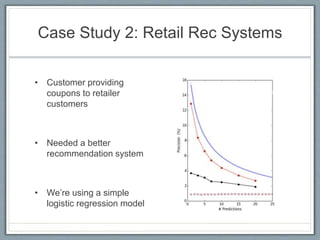





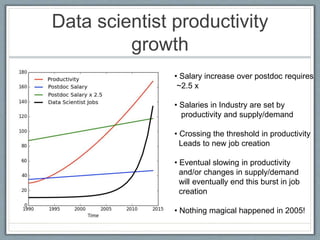










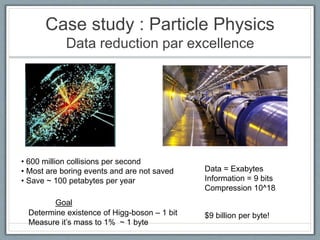





This document summarizes a presentation on data science consulting. It discusses: 1) The Agile Analytics group at ThoughtWorks which does data science consulting projects using probabilistic modeling, machine learning, and big data technologies. 2) Two case studies are described, including developing a machine learning model to improve matching of healthcare product data and using logistic regression for retail recommendation systems. 3) The origins and future of the field are discussed, noting that while not entirely new, data science has grown due to improvements in technology, programming languages, and libraries that have increased productivity and driven new career opportunities in the field.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





