𝑟 が変動する場合
変形すると・・・
→ exponential,recency-weighted average
Q学習(即時報酬だけの場合)
),(),(),( 11 asQrasQasQ kkkk
i
ik
k
i
k
k rQQ
)1()1(
1
0
Formal Theory ofCreativity & Fun & Intrinsic
Motivation (1990-2010) by Jürgen Schmidhuber
http://people.idsia.ch/~juergen/creativity.html
• (A) an adaptive predictor of the growing data
history as the agent is interacting with its
environment
• (B) a reinforcement learner selecting the
actions that shape the history
• (B) is motivated to learn to invent
interesting things that (A) does not yet know
but can easily learn.
13.
(つづき)
• To maximizefuture expected reward, (B)
learns more and more complex behaviors that
yield initially surprising (but eventually
boring) novel patterns that make (A) quickly
improve.
14.
(つづき)
• O(t): thestate of some observer O at time t
• H(t): its history of previous actions &
sensations & rewards until time t
• Beauty B(D,O(t)) of any data D: the negative
number of bits required to encode D
• Interestingness I(D,O(t)) of data D for
observer O at discrete time
step t>0: I(D,O(t))= B(D,O(t))-B(D,O(t-1))
参考資料
• Second InterdisciplinarySymposium on
Information-Seeking, Curiosity and Attention
https://openlab-flowers.inria.fr/t/second-
interdisciplinary-symposium-on-information-
seeking-curiosity-and-attention-neurocuriosity-
2016/187
• Information-seeking, curiosity, and attention:
computational and neural mechanisms
http://www.pyoudeyer.com/TICSCuriosity2013.pdf







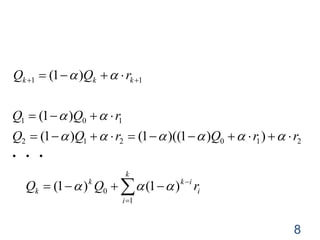



























![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)


































