Downloaded 91 times











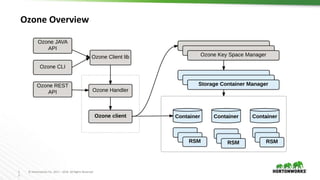
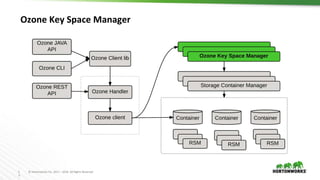


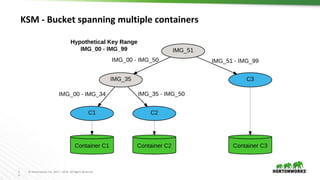


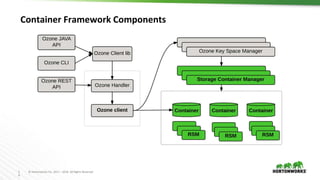
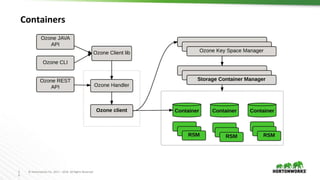


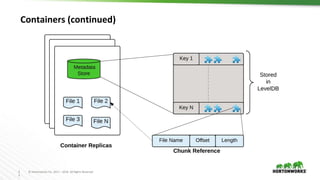

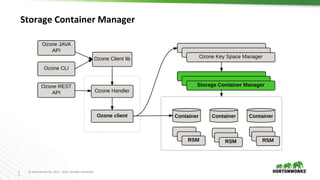



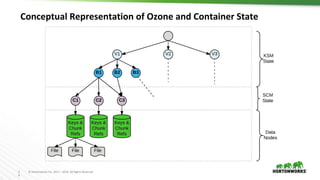

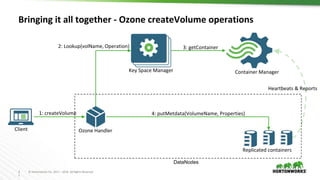
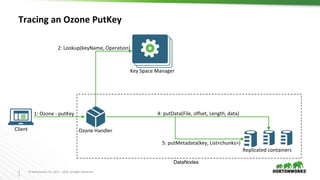















Ozone is an object store for Apache Hadoop that is designed to scale to trillions of objects. It uses a distributed metadata store to avoid single points of failure and enable parallelism. Key components of Ozone include containers, which provide the basic storage and replication functionality, and the Key Space Manager (KSM) which maps Ozone entities like volumes and buckets to containers. The Storage Container Manager manages the container lifecycle and replication.























































































