Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Cloudera Japan
PPTX, PDF
12,672 views
HDFSネームノードのHAについて #hcj13w
Hadoop Conference Japan 2013 Winter で発表した、ネームノードHA についての資料です。10分だったのでかなり限定的な説明に終わっています。
Read more
9
Save
Share
Embed
Embed presentation
Download
Downloaded 127 times
1
/ 48
2
/ 48
3
/ 48
4
/ 48
5
/ 48
6
/ 48
7
/ 48
8
/ 48
9
/ 48
10
/ 48
11
/ 48
12
/ 48
13
/ 48
14
/ 48
15
/ 48
16
/ 48
17
/ 48
18
/ 48
19
/ 48
20
/ 48
21
/ 48
22
/ 48
23
/ 48
24
/ 48
25
/ 48
26
/ 48
27
/ 48
28
/ 48
29
/ 48
30
/ 48
31
/ 48
32
/ 48
33
/ 48
34
/ 48
35
/ 48
36
/ 48
37
/ 48
38
/ 48
39
/ 48
40
/ 48
41
/ 48
42
/ 48
43
/ 48
44
/ 48
45
/ 48
46
/ 48
47
/ 48
48
/ 48
More Related Content
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
全文検索でRedmineをさらに活用!
by
Kouhei Sutou
PDF
Redmineチューニングの実際と限界(旧資料) - Redmine performance tuning(old), See Below.
by
Kuniharu(州晴) AKAHANE(赤羽根)
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
全文検索でRedmineをさらに活用!
by
Kouhei Sutou
Redmineチューニングの実際と限界(旧資料) - Redmine performance tuning(old), See Below.
by
Kuniharu(州晴) AKAHANE(赤羽根)
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
What's hot
PPTX
PostgreSQLのgitレポジトリから見える2021年の開発状況(第30回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Pacemaker 操作方法メモ
by
Masayuki Ozawa
PPT
Bloom filter
by
Kumazaki Hiroki
PPTX
Hadoop -ResourceManager HAの仕組み-
by
Yuki Gonda
PDF
その ionice、ほんとに効いてますか?
by
Narimichi Takamura
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Avro vs Protocol Buffers
by
Seiya Mizuno
PDF
これからLDAPを始めるなら 「389-ds」を使ってみよう
by
Nobuyuki Sasaki
PDF
HTTP/2 入門
by
Yahoo!デベロッパーネットワーク
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
MQTTとAMQPと.NET
by
terurou
PPTX
地理分散DBについて
by
Kumazaki Hiroki
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
今だからこそ知りたい Docker Compose/Swarm 入門
by
Masahito Zembutsu
PDF
TiDBのトランザクション
by
Akio Mitobe
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQLのgitレポジトリから見える2021年の開発状況(第30回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Pacemaker 操作方法メモ
by
Masayuki Ozawa
Bloom filter
by
Kumazaki Hiroki
Hadoop -ResourceManager HAの仕組み-
by
Yuki Gonda
その ionice、ほんとに効いてますか?
by
Narimichi Takamura
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Apache Avro vs Protocol Buffers
by
Seiya Mizuno
これからLDAPを始めるなら 「389-ds」を使ってみよう
by
Nobuyuki Sasaki
HTTP/2 入門
by
Yahoo!デベロッパーネットワーク
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
MQTTとAMQPと.NET
by
terurou
地理分散DBについて
by
Kumazaki Hiroki
トランザクションの設計と進化
by
Kumazaki Hiroki
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
今だからこそ知りたい Docker Compose/Swarm 入門
by
Masahito Zembutsu
TiDBのトランザクション
by
Akio Mitobe
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Viewers also liked
PDF
IIJ GIOを支える統合運用監視基盤
by
IIJ
PDF
HDFS HA セミナー #hadoop
by
Cloudera Japan
PDF
第37回「Dockerのユースケースと将来」(2014/10/30 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
PDF
Docker勉強会2017 実践編 スライド
by
Shiojiri Ohhara
PDF
Simplify and Secure your Hadoop Environment with Hortonworks and Centrify
by
Hortonworks
PDF
Hadoop and Kerberos
by
Yuta Imai
PDF
AWSマネージドサービスをフル活用したヘルスケアIoTプラットフォーム
by
Hiroki Takeda
PDF
Dockerイメージの理解とコンテナのライフサイクル
by
Masahito Zembutsu
PDF
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
IIJ GIOを支える統合運用監視基盤
by
IIJ
HDFS HA セミナー #hadoop
by
Cloudera Japan
第37回「Dockerのユースケースと将来」(2014/10/30 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
Docker勉強会2017 実践編 スライド
by
Shiojiri Ohhara
Simplify and Secure your Hadoop Environment with Hortonworks and Centrify
by
Hortonworks
Hadoop and Kerberos
by
Yuta Imai
AWSマネージドサービスをフル活用したヘルスケアIoTプラットフォーム
by
Hiroki Takeda
Dockerイメージの理解とコンテナのライフサイクル
by
Masahito Zembutsu
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
More from Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
HDFSネームノードのHAについて #hcj13w
1.
High Availability for
the HDFS NameNode Cloudera 2013年1月21日 1
2.
自己紹介 • 小林 大輔(@daisukebe_) •
カスタマーオペレーションズエンジニアとして テクニカルサポート業務を担当 • email: daisuke@cloudera.com
3.
ネームノードHAとは? 3
4.
従来のネームノードの問題点
• 従来のHadoopではネームノードは単一障害点 (SPOF)だった • ネームノードは、ファイルシステムのメタデータ を管理している(editsログ/fsimageなど) • ネームノードがダウンしたらデータが読み込めず、 クラスタ自体が利用不可になる 4
5.
従来のネームノードの問題点
• 従来のHadoopではネームノードは単一障害点 (SPOF)だった • ネームノードは、ファイルシステムのメタデータ を管理している(editsログ/fsimageなど) • ネームノードがダウンしたらデータが読み込めず、 クラスタ自体が利用不可になる HA対応してほしいという需要 5
6.
ネームノードHAの要件
• メタデータの保存先として、カスタムハード ウェアに依存しないこと • アクティブ/スタンバイ構成において、メタデー タの同期が容易であること • デプロイが容易であること • スプリットブレインシンドロームを避けられる こと • SPOFがないこと • 既存のHadoopクラスタの資産を無駄にしないこ と 6
7.
ネームノードHAの要件
要は 7
8.
ネームノードHAの要件
(比較的)簡単に 既存のHadoopの仕組みを 無駄にすることなく HA構成を作れること 8
9.
ネームノードHA
• Apache Hadoop2.0では ネームノードHAが導入されました • CDH4.1にも含まれてます 9
10.
ネームノードHA
• クォーラムベースジャーナリング • 外部のハードウェアに依存しない • 自動フェイルオーバー • 障害発生時にも自動で切り替え可能 10
11.
今日は、、
• クォーラムベースジャーナリング • 外部のハードウェアに依存しない • 自動フェイルオーバー • 障害発生時にも自動で切り替え可能 11
12.
クォーラムベースジャーナリングについて 12
13.
クォーラムベースジャーナリング
• ネームノードのメタデータ(editsログ)を 複数の場所で保管 • ネームノードはクライアントとして、 editsを書き込む • 複数の書き込み先のうち、過半数 (クォーラム数)のノードに成功すれば editsはコミットとみなす 13
14.
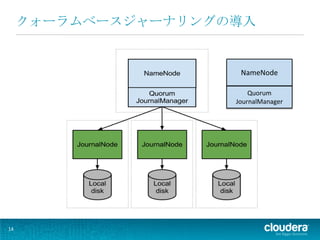
クォーラムベースジャーナリングの導入
NameNode Quorum JournalManager 14
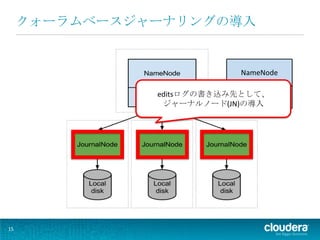
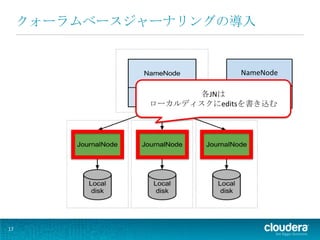
15.
クォーラムベースジャーナリングの導入
NameNode editsログの書き込み先として、Quorum JournalManager ジャーナルノード(JN)の導入 15
16.
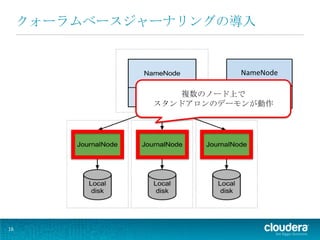
クォーラムベースジャーナリングの導入
NameNode 複数のノード上で Quorum JournalManager スタンドアロンのデーモンが動作 16
17.
クォーラムベースジャーナリングの導入
NameNode 各JNは Quorum JournalManager ローカルディスクにeditsを書き込む 17
18.
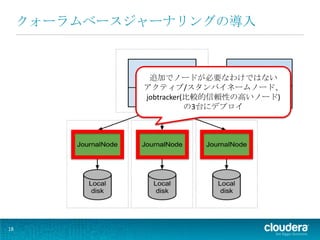
クォーラムベースジャーナリングの導入
NameNode 追加でノードが必要なわけではない アクティブ/スタンバイネームノード、 Quorum jobtracker(比較的信頼性の高いノード) JournalManager の3台にデプロイ 18
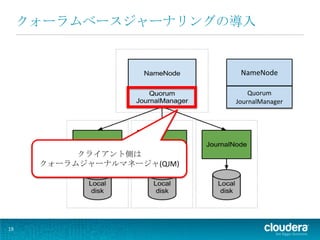
19.
クォーラムベースジャーナリングの導入
NameNode Quorum JournalManager クライアント側は クォーラムジャーナルマネージャ(QJM) 19
20.
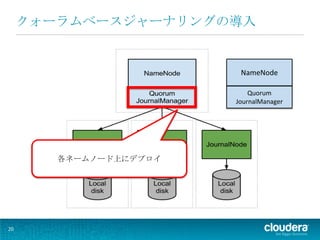
クォーラムベースジャーナリングの導入
NameNode Quorum JournalManager 各ネームノード上にデプロイ 20
21.
では、、
editsは どのように 書き込まれるのか? 21
22.
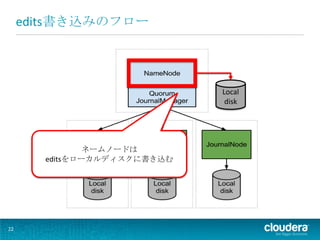
edits書き込みのフロー
Local disk ネームノードは editsをローカルディスクに書き込む 22
23.
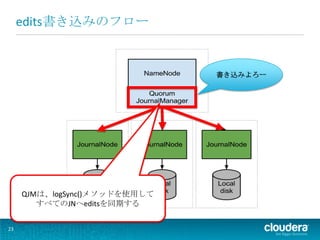
edits書き込みのフロー
書き込みよろー QJMは、logSync()メソッドを使用して すべてのJNへeditsを同期する 23
24.
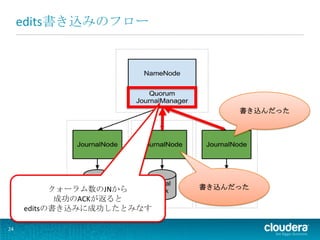
edits書き込みのフロー
書き込んだった クォーラム数のJNから 書き込んだった 成功のACKが返ると editsの書き込みに成功したとみなす 24
25.
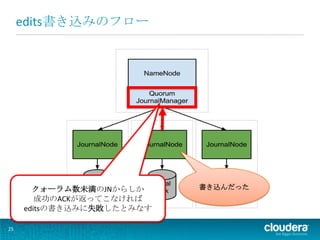
edits書き込みのフロー
クォーラム数未満のJNからしか 書き込んだった 成功のACKが返ってこなければ editsの書き込みに失敗したとみなす 25
26.
ところで、、
ネームノードHAは アクティブ/スタンバイ構成 26
27.
ところで、、
両ネームノードからeditsが 書き込まれる恐れはないの? 27
28.
これは、、
両ネームノードから 同時に書き込んでしまうと データに不整合が生じてしまう 28
29.
ファイルシステムとしての
信頼性が損なわれる 29
30.
最悪
データ破損も招きかねないので 非常に危険! 30
31.
NameNode
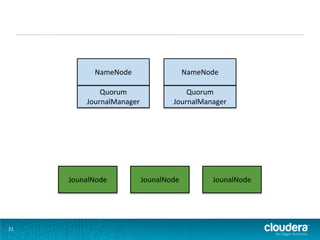
NameNode Quorum Quorum JournalManager JournalManager JounalNode JounalNode JounalNode 31
32.
NameNode
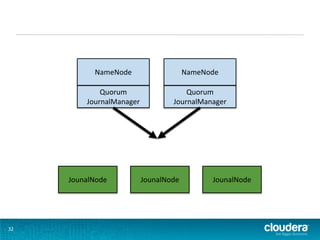
NameNode Quorum Quorum JournalManager JournalManager JounalNode JounalNode JounalNode 32
33.
NameNode
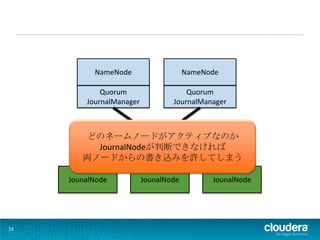
NameNode Quorum Quorum JournalManager JournalManager どのネームノードがアクティブなのか JournalNodeが判断できなければ 両ノードからの書き込みを許してしまう JounalNode JounalNode JounalNode 33
34.
そこで、、
クォーラムベースジャーナリング にはフェンシングの 仕組みがある 34
35.
そこで、、
フェンシング: editsを書き込めるネームノードは 常にただ1つだけであることを 保証する仕組み 35
36.
QJMのフェンシング
エポック番号を使う 36
37.
エポック番号
JNが アクティブネームノードを 一意に識別するために 使う番号 37
38.
エポック番号によるフェンシング
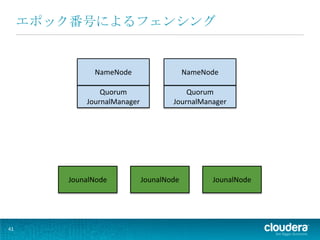
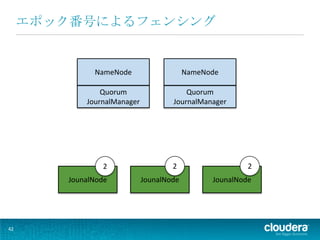
• アクティブになるたびに新しい エポック番号が割り振られる • 両ネームノードが同時に同じエポック 番号をもつことはない • JNは最新のエポック番号を保存する 38
39.
エポック番号によるフェンシング
時系列でみてみると... 39
40.
エポック番号によるフェンシング
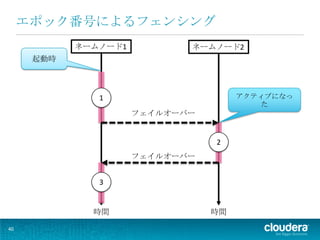
ネームノード1 ネームノード2 起動時 1 アクティブになっ た フェイルオーバー 2 フェイルオーバー 3 時間 時間 40
41.
エポック番号によるフェンシング
NameNode NameNode Quorum Quorum JournalManager JournalManager JounalNode JounalNode JounalNode 41
42.
エポック番号によるフェンシング
NameNode NameNode Quorum Quorum JournalManager JournalManager 2 2 2 JounalNode JounalNode JounalNode 42
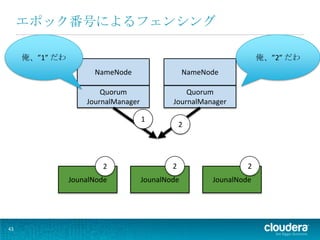
43.
エポック番号によるフェンシング
俺、”1” だわ 俺、”2” だわ NameNode NameNode Quorum Quorum JournalManager JournalManager 1 2 2 2 2 JounalNode JounalNode JounalNode 43
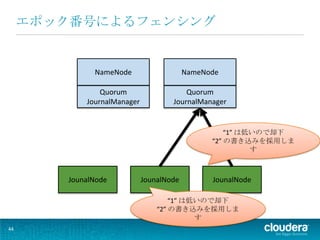
44.
エポック番号によるフェンシング
NameNode NameNode Quorum Quorum JournalManager JournalManager “1” は低いので却下 “2” の書き込みを採用しま す JounalNode JounalNode JounalNode “1” は低いので却下 “2” の書き込みを採用しま す 44
45.
エポック番号によるフェンシング
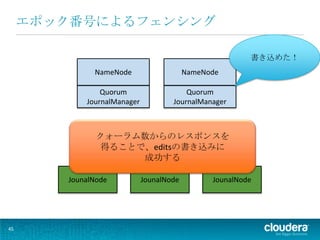
書き込めた! NameNode NameNode Quorum Quorum JournalManager JournalManager クォーラム数からのレスポンスを 得ることで、editsの書き込みに 成功する JounalNode JounalNode JounalNode 45
46.
まとめ
• クォーラムベースジャーナリングを使用 したネームノードHAを紹介しました • editsを複数ノードで分散して保存するこ とで信頼性が高まっています • エポック番号を使用することで、両ネー ムノードから書き込みが発生することを 防いでいます。 46
47.
宣伝
• Cloudera Managerを使用することで ネームノードHAへの移行が非常に簡単に できます • Cloudera社のブースでデモを行なって いるので、立ち寄ってみてください 47
48.
48
Download