Downloaded 93 times








![10 © Hortonworks Inc. 2011–2018. All rights reserved
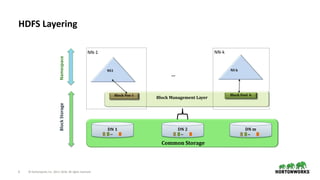
How it all Fits Together
Old HDFS NN
All namespace in
memory
Storage&IONamespace
HDFS Block storage on DataNodes
(Bid -> Data)
Physical Storage - Shared DataNodes and physical
storage shared between
Old HDFS and HDDS
Block Reports
BlockMap
(Bid ->IPAddress of DN
File = Bid[]
Ozone Master
K-V Flat
Namespace
File (Object) = Bid[]
Bid = Cid+ LocalId
New HDFS NN
(scalable)
Hierarchical
Namespace
File = Bid[]
Bid = Cid+ LocalId
Container Management
& Cluster Membership
HDDS Container Storage on DataNodes
(Bid -> Data, but blocks grouped in containers)
HDDS
HDDS – Clean
Separation of
Block layer
DataNodes
ContainerMap
(CId ->IPAddress of DNContainer Reports
NewExisting HDFS](https://image.slidesharecdn.com/ozoneandhdfs-180426223616/85/Ozone-and-HDFS-s-evolution-10-320.jpg)








![20 © Hortonworks Inc. 2011–2018. All rights reserved
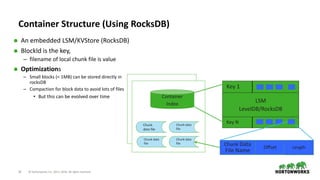
Ozone Master
DN1 DN2 DNn
Ozone Master
K-V
Namespace
File (Object) = Bid[]
Bid = Cid+ LocalId
CM
ContainerMap
(CId ->IPAddress of DN
Client
RocksDB
bId[]= Open(Key,..)
GetBlockLocations(Bid)
$$$
$$$ - Container Map Cache
$$$
Read, Write, …](https://image.slidesharecdn.com/ozoneandhdfs-180426223616/85/Ozone-and-HDFS-s-evolution-20-320.jpg)



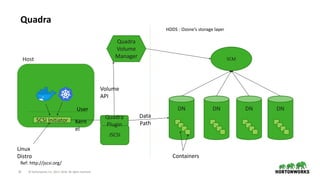





The document discusses scaling challenges with HDFS and proposed solutions from Hortonworks called HDDS and Ozone. HDFS scales well for data and IO but has limitations scaling the namespace beyond 500 million files. HDDS aims to scale the block layer using block containers which can reduce block reports. Ozone uses a flat key-value namespace that is easier to shard and scale beyond billions of objects compared to HDFS hierarchical namespace. It also provides an HDFS compatible filesystem called OzoneFS. Together HDDS and Ozone aim to retain HDFS features while scaling to exabytes of data and trillions of files.






















































































