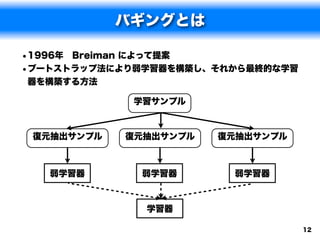
バギングのアルゴリズム
1.以下の手順を B 回繰り返す.
a.データからm 回復元抽出して、新しいデータを作る.
b.弱学習器 h を構築する.
2. B 個の弱学習器 h を用いて最終的な学習器を構築する.
•判別問題の場合: H(x) = argmax|{i|hi = y}|
B
X
•回帰問題の場合: H(x) = 1 hi
B i=1
13
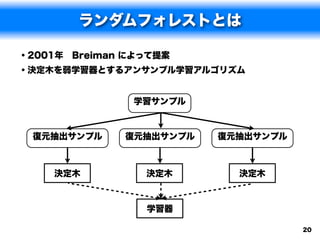
ランダムフォレストのアルゴリズム
1.以下の手順を B 回繰り返す.
a.訓練データからブートストラップサンプルを作成する.
b.ブートストラップサンプルから決定木 Tiを構築する.このとき,
指定したノード数 nmin になるまで,以下の手順を繰り返す.
i. p 個の説明変数から m 個の変数をランダムに選択する.
ii. m 個の説明変数から最も良い変数を分岐ノードとする.
2. B 個の決定木 Ti を用いて最終的な学習器を構築する
•判別問題の場合は多数決
•回帰問題の場合は平均
21
24.
アルゴリズムの補足
• パラメータ nminと m をどう決めれば良いのか?
p
• 判別問題の場合: nmin = 1, m = p
• 回帰問題に場合: nmin = 5, m = p/3
• バギングとランダムフォレストの違いは?
• バギングでは説明変数を全て使う
• ランダムフォレストでは説明変数をランダムサンプリングして使う
22
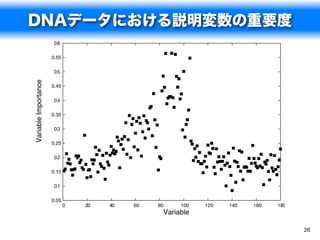
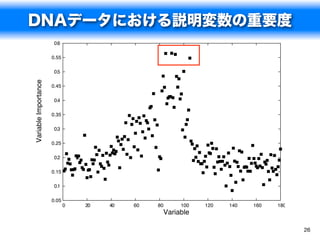
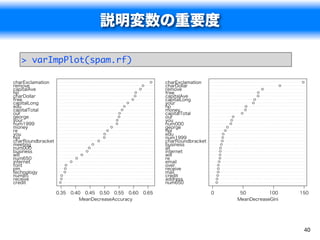
説明変数の重要度
spam.rf
> varImpPlot(spam.rf)
charExclamation charExclamation
remove charDollar
capitalAve remove
hp free
charDollar capitalAve
free capitalLong
capitalLong your
edu hp
capitalTotal money
our capitalTotal
george our
your you
num1999 num000
money george
re hpl
you edu
hpl num1999
charRoundbracket charRoundbracket
meeting business
num000 all
business internet
will will
num650 re
internet email
font over
pm receive
technology mail
num85 credit
receive address
credit num650
0.35 0.40 0.45 0.50 0.55 0.60 0.65 0 50 100 150
MeanDecreaseAccuracy MeanDecreaseGini
40















![AdaBoost のアルゴリズム
入力 (x1 , u1 ), . . . , (xm , ym ) where xi 2 X, yi 2 Y = { 1, +1}
初期化 重みの初期値を とする.
D1 (i) = 1/m
繰り返し t = 1, . . . , T として,以下の手順を繰り返す.
1.確率分布 Dt に従う弱学習器 ht : X ! { 1, +1} を構築する.
2.弱学習器 ht の誤り率 ✏t を計算する.
X
✏t = Prx⇠Dt [ft (xi ) 6= yi ] = Dt (i)
i:ht (xi )6=yi
3.弱学習器 ht の重要度 ↵t を計算 1 1 ✏t
↵t = log( )
4.重みを更新する. ⇢
2 ✏t
Dt (i) e ↵t if ht (xi ) = yi
Dt+1 (i) = ⇥
Zt e ↵t if ht (xi ) 6= yi
Dt (i)exp( ↵t yi ht (xi ))
=
Zt!
XT
出力 H(x) = sign ↵t ht (x) 16
t=1](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-18-320.jpg)













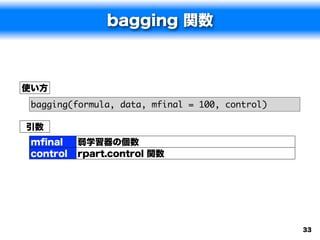
![bagging 関数の実行例
> set.seed(50)
> tr.num <- sample(4601, 2500)
> spam.train <- spam[tr.num,]
> spam.test <- spam[-tr.num,]
> spam.ba <- bagging(type~., data=spam.train)
> spam.bap <- predict(spam.ba, spam.test)
> spam.bap$confusion
Observed Class
Predicted Class nonspam spam
nonspam 1208 124
spam 74 695
> spam.bap$error
[1] 0.09424084
34](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-37-320.jpg)
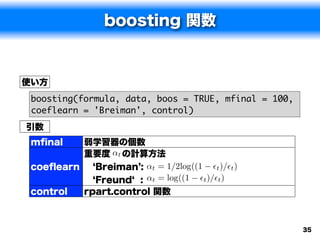
![boosting 関数の実行例
> spam.ad <- boosting(type~., data=spam.train)
> spam.adp <- predict(spam.ad, newdata=spam.test)
> spam.adp$confusion
Observed Class
Predicted Class nonspam spam
nonspam 1232 46
spam 50 773
> spam.adp$error
[1] 0.04569253
36](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-39-320.jpg)
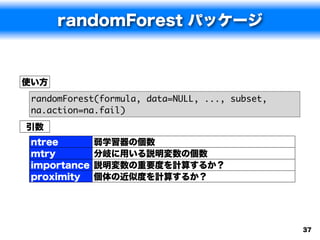
![randomForest の実行例
> spam.rf <- randomForest(type~., data=spam.train,
na.action="na.omit")
> spam.rfp<-predict(spam.rf, spam.test[,-58])
> (spam.rft<-table(spam.test[,58], spam.rfp))
spam.rfp
nonspam spam
nonspam 1240 42
spam 75 744
> sum(diag(spam.rft))/sum(spam.rft)
[1] 0.9443122
38](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-41-320.jpg)


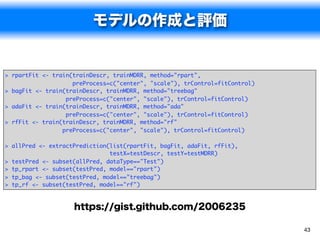
![モデルの比較①
> confusionMatrix(tp_rpar$pred, tp_rpa$obs) > confusionMatrix(tp_bag$pred, tp_bag$obs)
Confusion Matrix and Statistics Confusion Matrix and Statistics
Reference Reference
Prediction Active Inactive Prediction Active Inactive
Active 132 51 Active 129 32
Inactive 17 64 Inactive 20 83
Accuracy : 0.7424 Accuracy : 0.803
95% CI : (0.6852, 0.7941) 95% CI : (0.7499, 0.8493)
No Information Rate : 0.5644 No Information Rate : 0.5644
P-Value [Acc > NIR] : 1.514e-09 P-Value [Acc > NIR] : 2.566e-16
Kappa : 0.4579 Kappa : 0.5946
Mcnemar's Test P-Value : 6.285e-05 Mcnemar's Test P-Value : 0.1272
Sensitivity : 0.8859 Sensitivity : 0.8658
Specificity : 0.5565 Specificity : 0.7217
Pos Pred Value : 0.7213 Pos Pred Value : 0.8012
Neg Pred Value : 0.7901 Neg Pred Value : 0.8058
Prevalence : 0.5644 Prevalence : 0.5644
Detection Rate : 0.5000 Detection Rate : 0.4886
Detection Prevalence : 0.6932 Detection Prevalence : 0.6098
'Positive' Class : Active 'Positive' Class : Active 44](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-48-320.jpg)
![モデルの比較②
> confusionMatrix(tp_ada$pred, tp_ada$obs) > confusionMatrix(tp_rf$pred, tp_rf$obs)
Confusion Matrix and Statistics Confusion Matrix and Statistics
Reference Reference
Prediction Active Inactive Prediction Active Inactive
Active 133 33 Active 133 31
Inactive 16 82 Inactive 16 84
Accuracy : 0.8144 Accuracy : 0.822
95% CI : (0.7622, 0.8594) 95% CI : (0.7704, 0.8662)
No Information Rate : 0.5644 No Information Rate : 0.5644
P-Value [Acc > NIR] : < 2e-16 P-Value [Acc > NIR] : < 2e-16
Kappa : 0.6161 Kappa : 0.6325
Mcnemar's Test P-Value : 0.02227 Mcnemar's Test P-Value : 0.04114
Sensitivity : 0.8926 Sensitivity : 0.8926
Specificity : 0.7130 Specificity : 0.7304
Pos Pred Value : 0.8012 Pos Pred Value : 0.8110
Neg Pred Value : 0.8367 Neg Pred Value : 0.8400
Prevalence : 0.5644 Prevalence : 0.5644
Detection Rate : 0.5038 Detection Rate : 0.5038
Detection Prevalence : 0.6288 Detection Prevalence : 0.6212
'Positive' Class : Active 'Positive' Class : Active 45](https://image.slidesharecdn.com/random-120310022555-phpapp02/85/slide-49-320.jpg)




![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)












![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)



























