Downloaded 31 times





![Represent, ingest, cache
import org.apache.spark.sql.types._
val schema = new StructType()
.add("OBJECTID", LongType)
.add("Borough", StringType)
// etc
// limited columns to make query plans easier to read
case class PlantingSpace(
OBJECTID: Long,
Borough: String,
// etc
)
val ds = spark
.read
.option("inferSchema", false)
.option("header", true)
.option("sep", ",")
.schema(schema)
.csv("/path/to/csv")
.select(
$"OBJECTID", $"Borough", // etc
)
.as[PlantingSpace]
ds.cache()
ImportModel](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-6-320.jpg)




![Parsed Logical Plan
== Parsed Logical Plan ==
GlobalLimit 10
+- LocalLimit 10
+- Sort [streetSiteCount#1406L DESC NULLS LAST], true
+- Aggregate [Borough#1287, Postcode#1300L], [Borough#1287, Postcode#1300L, count(distinct
Number#1288, Street#1289) AS streetSiteCount#1406L]
+- Filter NOT (Postcode#1300L = cast(0 as bigint))
+- Filter isnotnull(Borough#1287)
+- Filter (PSSite#1290 = Street)
+- Project [OBJECTID#1286L, Borough#1287, Number#1288, Street#1289, PSSite#1290,
ParkName#1294, Postcode#1300L, Congressional#1304L, PSStatus#1306]
+- Relation[OBJECTID#1286L,Borough#1287,Number#1288,Street#1289,PSSite#1290,
PlantingSpaceOnStreet#1291,Width#1292,Length#1293,ParkName#1294,ParkZone#1295,CrossStreet1#1296,Cros
sStreet2#1297,CommunityBoard#1298L,SanitationZone#1299,Postcode#1300L,CouncilDistrict#1301L,StateSen
ate#1302L,StateAssembly#1303L,Congressional#1304L,PhysicalID#1305L,PSStatus#1306,Geometry#1307,Globa
lID#1308,CreatedDate#1309,... 11 more fields] csv](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-13-320.jpg)
![Analyzed Logical Plan
== Analyzed Logical Plan ==
Borough: string, Postcode: bigint, streetSiteCount: bigint
GlobalLimit 10
+- LocalLimit 10
+- Sort [streetSiteCount#1406L DESC NULLS LAST], true
+- Aggregate [Borough#1287, Postcode#1300L], [Borough#1287, Postcode#1300L, count(distinct
Number#1288, Street#1289) AS streetSiteCount#1406L]
+- Filter NOT (Postcode#1300L = cast(0 as bigint))
+- Filter isnotnull(Borough#1287)
+- Filter (PSSite#1290 = Street)
+- Project [OBJECTID#1286L, Borough#1287, Number#1288, Street#1289, PSSite#1290,
ParkName#1294, Postcode#1300L, Congressional#1304L, PSStatus#1306]
+- Relation[OBJECTID#1286L,Borough#1287,Number#1288,Street#1289,PSSite#1290,
PlantingSpaceOnStreet#1291,Width#1292,Length#1293,ParkName#1294,ParkZone#1295,CrossStreet1#1296,Cros
sStreet2#1297,CommunityBoard#1298L,SanitationZone#1299,Postcode#1300L,CouncilDistrict#1301L,StateSen
ate#1302L,StateAssembly#1303L,Congressional#1304L,PhysicalID#1305L,PSStatus#1306,Geometry#1307,Globa
lID#1308,CreatedDate#1309,... 11 more fields] csv](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-14-320.jpg)
![Optimized Logical Plan
== Optimized Logical Plan ==
GlobalLimit 10
+- LocalLimit 10
+- Sort [streetSiteCount#1406L DESC NULLS LAST], true
+- Aggregate [Borough#1287, Postcode#1300L], [Borough#1287, Postcode#1300L, count(distinct
Number#1288, Street#1289) AS streetSiteCount#1406L]
+- Project [Borough#1287, Number#1288, Street#1289, Postcode#1300L]
+- Filter ((((isnotnull(PSSite#1290) && isnotnull(Postcode#1300L)) && (PSSite#1290 =
Street)) && isnotnull(Borough#1287)) && NOT (Postcode#1300L = 0))
+- InMemoryRelation [OBJECTID#1286L, Borough#1287, Number#1288, Street#1289, PSSite#1290,
ParkName#1294, Postcode#1300L, Congressional#1304L, PSStatus#1306], StorageLevel(disk, memory,
deserialized, 1 replicas)
+- *(1) FileScan csv [OBJECTID#16L,Borough#17,Number#18,Street#19,PSSite#20,ParkName#24,
Postcode#30L,Congressional#34L,PSStatus#36] Batched: false, DataFilters: [], Format: CSV, Location:
InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_csv-3123a.gz], PartitionFilters:
[], PushedFilters: [], ReadSchema:
struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,PSSite:string,ParkName:string,P...
* Whole stage code generation mark](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-16-320.jpg)
![Physical Plan
== Physical Plan ==
TakeOrderedAndProject(limit=10, orderBy=[streetSiteCount#1406L DESC NULLS LAST],
output=[Borough#1287,Postcode#1300L,streetSiteCount#1406L])
+- *(3) HashAggregate(keys=[Borough#1287, Postcode#1300L], functions=[finalmerge_count(distinct merge
count#1497L) AS count(Number#1288, Street#1289)#1405L], output=[Borough#1287, Postcode#1300L,
streetSiteCount#1406L])
+- Exchange hashpartitioning(Borough#1287, Postcode#1300L, 200), [id=#1279]
+- *(2) HashAggregate(keys=[Borough#1287, Postcode#1300L], functions=[partial_count(distinct Number#1288,
Street#1289) AS count#1497L], output=[Borough#1287, Postcode#1300L, count#1497L])
+- *(2) HashAggregate(keys=[Borough#1287, Postcode#1300L, Number#1288, Street#1289], functions=[],
output=[Borough#1287, Postcode#1300L, Number#1288, Street#1289])
+- Exchange hashpartitioning(Borough#1287, Postcode#1300L, Number#1288, Street#1289, 200), [id=#1274]
+- *(1) HashAggregate(keys=[Borough#1287, Postcode#1300L, Number#1288, Street#1289], functions=[],
output=[Borough#1287, Postcode#1300L, Number#1288, Street#1289])
+- *(1) Project [Borough#1287, Number#1288, Street#1289, Postcode#1300L]
+- *(1) Filter ((((isnotnull(PSSite#1290) && isnotnull(Postcode#1300L)) && (PSSite#1290 =
Street)) && isnotnull(Borough#1287)) && NOT (Postcode#1300L = 0))
+- InMemoryTableScan [Borough#1287, Number#1288, PSSite#1290, Postcode#1300L, Street#1289],
[isnotnull(PSSite#1290), isnotnull(Postcode#1300L), (PSSite#1290 = Street), isnotnull(Borough#1287), NOT
(Postcode#1300L = 0)]
+- InMemoryRelation [OBJECTID#1286L, Borough#1287, Number#1288, Street#1289, PSSite#1290,
ParkName#1294, Postcode#1300L, Congressional#1304L, PSStatus#1306], StorageLevel(disk, memory, deserialized, 1
replicas)
+- *(1) FileScan csv [OBJECTID#16L,Borough#17,Number#18,Street#19,PSSite#20,ParkName#24,
Postcode#30L,Congressional#34L,PSStatus#36] Batched: false, DataFilters: [], Format: CSV, Location:
InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_csv-3123a.gz], PartitionFilters: [],
PushedFilters: [], ReadSchema: struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,
PSSite:string,ParkName:string,P...](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-18-320.jpg)



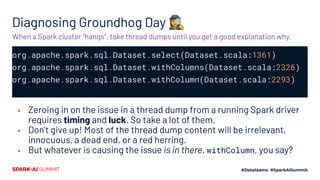
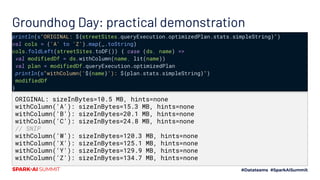
![Groundhog Day: the smoking gun
import scala.concurrent.duration.FiniteDuration
// hello friend, let's do some repetitive calculations
// using a list of metrics that are columns in our dataset
// and windowing back over our dataset over and over for different time periods
val colNames = Seq("foo", "bar", "baz", /* etc, */ )
val periods = Seq(6.months, 12.months, 18.months, /* etc */)
val metrics: List[(String, FiniteDuration)] =
for { col <- colNames; p <- periods} yield (col, p)
def doSomeCalc(ds: Dataframe, column: String, period: FiniteDuration): Column =
// boring calc goes here
// i like big query plans and i cannot lie
metrics.foldLeft(ds) { case (ds, (colName, period)) =>
ds.withColumn(colName+"_someCalc_"+period, doSomeCalc(ds, column, period))
}
TL;DR](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-24-320.jpg)

![Bonus stacktrace: beware the mega-query
ERROR AsyncEventQueue: Listener DBCEventLoggingListener threw an exception
com.fasterxml.jackson.databind.JsonMappingException: Exceeded 2097152 bytes
(current = 2101045) (through reference chain:
org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart["physicalPlanDescr
iption"])
Caused by: com.databricks.spark.util.LimitedOutputStream$LimitExceededException:
Exceeded 2097152 bytes (current = 2101045)
at
com.databricks.spark.util.LimitedOutputStream.write(LimitedOutputStream.scala:45)
The query plan so large Spark blew up trying to log it
The text file for Charles Dickens’ David Copperfield, a 500+ page book, is
2,033,139 bytes on Project Gutenberg.
This physical query plan was 67,906 bytes larger than David Copperfield when the
logger - thankfully - gave up.](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-27-320.jpg)
![Groundhog Day: the fix
val ds: Dataframe = ???
val existingCols: Seq[Column] =
ds.columns.toSeq // Seq[String]
.map(col) // def col: String => Column
val newColumns: Seq[(String, Column)] = metrics.map { case (colName, period) =>
val newColName = colName+"_someCalc_"+period
doSomeCalc(ds, colName, period).as(newColName)
}
// just once :)
ds.select((existingCols ++ newColumns): _*)
// take a look at the query lineage going forward - caching should solve the problem
// if not, truncate query lineage by checkpointing or writing out to cloud storage](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-28-320.jpg)

















![== Subtree 1 / 2 ==
*(1) HashAggregate(keys=[Borough#17, Postcode#30L], functions=[partial_count(OBJECTID#16L) AS
count#1247L], output=[Borough#17, Postcode#30L, count#1247L])
+- *(1) Project [OBJECTID#16L, Borough#17, Postcode#30L]
+- *(1) Filter ((((isnotnull(PSSite#20) && isnotnull(Postcode#30L)) && (PSSite#20 = Street)) &&
isnotnull(Borough#17)) && NOT (Postcode#30L = 0))
+- InMemoryTableScan [Borough#17, OBJECTID#16L, PSSite#20, Postcode#30L],
[isnotnull(PSSite#20), isnotnull(Postcode#30L), (PSSite#20 = Street), isnotnull(Borough#17), NOT
(Postcode#30L = 0)]
+- InMemoryRelation [OBJECTID#16L, Borough#17, Number#18, Street#19, PSSite#20,
ParkName#24, Postcode#30L, Congressional#34L, PSStatus#36, Latitude#44, Longitude#45],
StorageLevel(disk, memory, deserialized, 1 replicas)
+- *(1) FileScan csv [OBJECTID#16L, Borough#17, Number#18, Street#19, PSSite#20,
ParkName#24,Postcode#30L,Congressional#34L,PSStatus#36,Latitude#44,Longitude#45] Batched: false,
DataFilters: [], Format: CSV, Location:
InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_csv-3123a.gz], PartitionFilters:
[], PushedFilters: [], ReadSchema:
struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,PSSite:string,ParkName:string,P...
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* ETC */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends
org.apache.spark.sql.execution.BufferedRowIterator {
/* ETC */
/* 419 */ }
Triggered by .cache](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-47-320.jpg)
![== Subtree 2 / 2 ==
*(2) HashAggregate(keys=[Borough#17, Postcode#30L], functions=[finalmerge_count(merge count#1247L) AS
count(OBJECTID#16L)#1180L], output=[Borough#17, Postcode#30L, count#1181L])
+- Exchange hashpartitioning(Borough#17, Postcode#30L, 200), [id=#953]
+- *(1) HashAggregate(keys=[Borough#17, Postcode#30L], functions=[partial_count(OBJECTID#16L) AS
count#1247L], output=[Borough#17, Postcode#30L, count#1247L])
+- *(1) Project [OBJECTID#16L, Borough#17, Postcode#30L]
+- *(1) Filter ((((isnotnull(PSSite#20) && isnotnull(Postcode#30L)) && (PSSite#20 = Street)) &&
isnotnull(Borough#17)) && NOT (Postcode#30L = 0))
+- InMemoryTableScan [Borough#17, OBJECTID#16L, PSSite#20, Postcode#30L], [isnotnull(PSSite#20),
isnotnull(Postcode#30L), (PSSite#20 = Street), isnotnull(Borough#17), NOT (Postcode#30L = 0)]
+- InMemoryRelation [OBJECTID#16L, Borough#17, Number#18, Street#19, PSSite#20, ParkName#24,
Postcode#30L, Congressional#34L, PSStatus#36, Latitude#44, Longitude#45], StorageLevel(disk, memory,
deserialized, 1 replicas)
+- *(1) FileScan csv [OBJECTID#16L, Borough#17, Number#18, Street#19, PSSite#20,
ParkName#24,Postcode#30L,Congressional#34L,PSStatus#36,Latitude#44,Longitude#45] Batched: false, DataFilters:
[], Format: CSV, Location: InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_csv-3123a.gz],
PartitionFilters: [], PushedFilters: [], ReadSchema:
struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,PSSite:string,ParkName:string,P…
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* ETC */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends
org.apache.spark.sql.execution.BufferedRowIterator {
/* ETC */
/* 174 */ }
From the physical plan
SHUFFLE
Sends data
across
network](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-48-320.jpg)


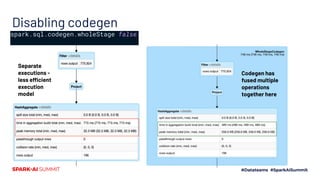

![Query planning can’t fix poor partitioning choices
> q.rdd.toDebugString
(188) MapPartitionsRDD[43] at rdd at command-2858540230021050:1 []
| SQLExecutionRDD[42] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[41] at rdd at command-2858540230021050:1 []
| MapPartition
sRDD[40] at rdd at command-2858540230021050:1 []
| ShuffledRowRDD[39] at rdd at command-2858540230021050:1 []
+-(200) MapPartitionsRDD[38] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[34] at rdd at command-2858540230021050:1 []
| ShuffledRowRDD[33] at rdd at command-2858540230021050:1 []
+-(1) MapPartitionsRDD[32] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[31] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[30] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[29] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[28] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[27] at rdd at command-2858540230021050:1 []
| FileScan csv
[OBJECTID#2L,Borough#3,Number#4,Street#5,PSSite#6,ParkName#10,Postcode#16L,Congressional#20L,PSStatus#22,Latitude#30,Longit
ude#31] Batched: false, DataFilters: [], Format: CSV, Location:
InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_csv-3123a.gz], PartitionFilters: [], PushedFilters: [],
ReadSchema: struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,PSSite:string,ParkName:string,P...
MapPartitionsRDD[2] at collectResult at OutputAggregator.scala:149 []
| CachedPartitions: 1; MemorySize: 46.9 MB; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| MapPartitionsRDD[1] at collectResult at OutputAggregator.scala:149 []
| FileScanRDD[0] at collectResult at OutputAggregator.scala:149 []
Wait, why are there so many
partitions?
🤦♂ Default is 200 partitions for
aggregations and joins.
Clue was back in physical plan
under Exchange (= shuffle)
hashpartitioning](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-53-320.jpg)
![Updating shuffle partitions
> q.rdd.toDebugString
(2) MapPartitionsRDD[37] at rdd at command-2858540230021050:1 []
| SQLExecutionRDD[36] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[35] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[34] at rdd at command-2858540230021050:1 []
| ShuffledRowRDD[33] at rdd at command-2858540230021050:1 []
+-(2) MapPartitionsRDD[32] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[28] at rdd at command-2858540230021050:1 []
| ShuffledRowRDD[27] at rdd at command-2858540230021050:1 []
+-(1) MapPartitionsRDD[26] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[25] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[24] at rdd at command-2858540230021050:1 []
| MapPartitionsRDD[23] at rdd at command-2858540230021050:1 []
| *(1) FileScan csv
[OBJECTID#2L,Borough#3,Number#4,Street#5,PSSite#6,ParkName#10,Post
code#16L,Congressional#20L,PSStatus#22,Latitude#30,Longitude#31]
Batched: false, DataFilters: [], Format: CSV, Location:
InMemoryFileIndex[dbfs:/FileStore/tables/Forestry_Planting_Spaces_
csv-3123a.gz], PartitionFilters: [], PushedFilters: [],
ReadSchema:
struct<OBJECTID:bigint,Borough:string,Number:string,Street:string,
PSSite:string,ParkName:string,P...
spark.sql.shuffle.partitions 2
Faster, uses less
memory
🚀](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-54-320.jpg)









![Spark issues and KB Articles
▪ Apache Spark Jobs hang due to non-deterministic custom UDF
▪ https://kb.databricks.com/jobs/spark-udf-performance.html
▪ SPARK-27761: Make UDFs non-deterministic by default (open, interesting discussion)
▪ https://issues.apache.org/jira/browse/SPARK-27761
▪ SPARK-27969: Non-deterministic expressions in filters or projects can unnecessarily prevent all
scan-time column pruning, harming performance
▪ https://issues.apache.org/jira/browse/SPARK-27969
▪ [SPARK-27692][SQL] Add new optimizer rule to evaluate the deterministic scala udf only once if all inputs
are literals 👈 unmerged PR with interesting discussion
▪ https://github.com/apache/spark/pull/24593](https://image.slidesharecdn.com/598rosetoomey-200708202842/85/Care-and-Feeding-of-Catalyst-Optimizer-64-320.jpg)



The document discusses the Spark SQL Catalyst Optimizer, detailing its role in query optimization and execution on Spark clusters. It includes case studies of challenges encountered in production, highlighting the importance of monitoring performance issues like excessive memory usage. Furthermore, the document presents data analysis examples and features introduced in Spark 3, such as enhanced query planning and physical execution strategies.





































































![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)
