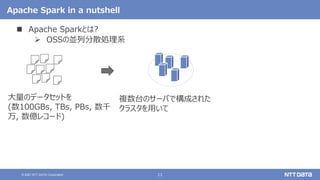
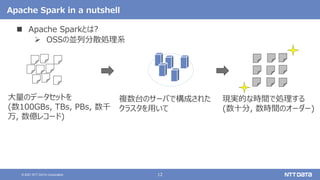
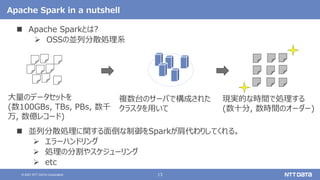
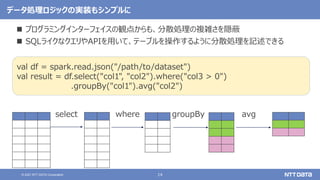
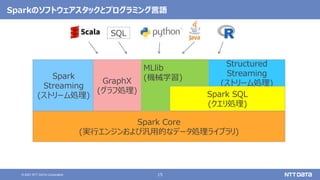
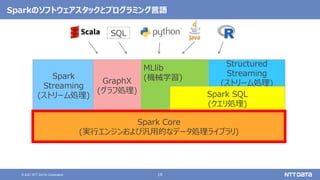
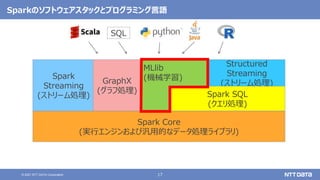
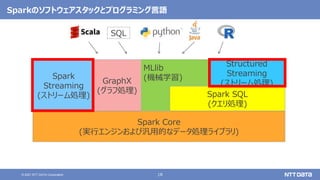
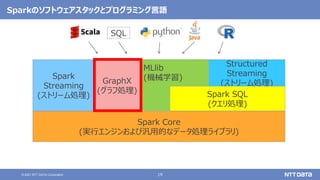
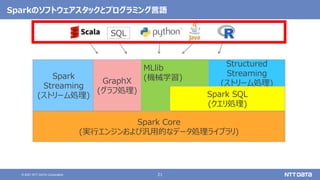
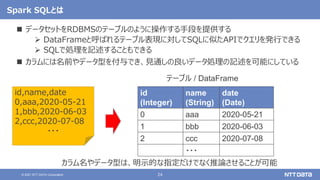
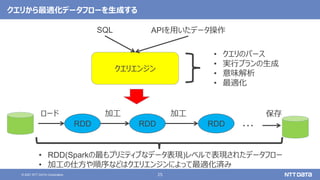
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference 2021 Online/Kyotoエディション - (Open Source Conference 2021 Online/Kyoto 発表資料) 2021年7月30日 株式会社NTTデータ 技術開発本部 先進コンピューティング技術センタ 猿田 浩輔


























![49
© 2021 NTT DATA Corporation
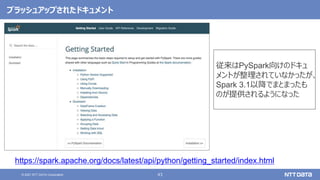
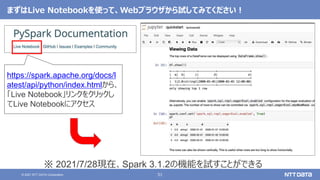
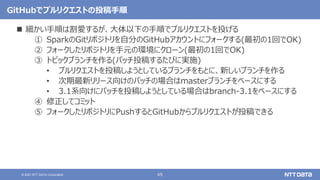
Koalas / pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import pyspark.pandas as ps
df = ps.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas
pandas API on Spark(Spark 3.2)](https://image.slidesharecdn.com/apachesparkosc2021onlinekyotonttdata-210728142427/85/OSS-Apache-Spark-Open-Source-Conference-2021-Online-Kyoto-49-320.jpg)











![67
© 2021 NTT DATA Corporation
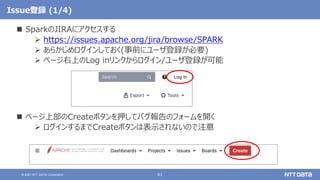
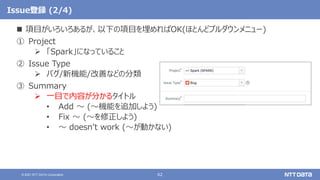
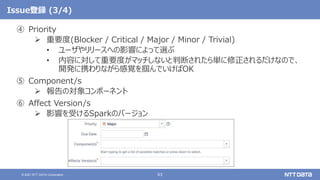
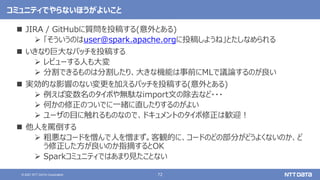
GitHubでプルリクエストを投稿する際の注意 - タイトル -
タイトルのつけ方に注意
「[対応するJIRAのチケット番号][コンポーネント名] タイトル」が基本形
• [SPARK-XXXX][SQL] Add new function to 〜
タイトルはJIRAからコピーでOK
コンポーネント名はJIRAで選択できるものと微妙に表記が異なるが、他のプルリクエ
ストを真似したり、指摘を受けながら覚えていけばよい
• CORE: Spark Core
• SS: Structured Streaming
• DOCS: Documentation
• ほかにも・・・
masterブランチ以外のブランチにプルリクエストを投稿する場合は[ブランチ名]のタグ
をつける
[SPARK-XXXX][3.1][MLlib] 〜](https://image.slidesharecdn.com/apachesparkosc2021onlinekyotonttdata-210728142427/85/OSS-Apache-Spark-Open-Source-Conference-2021-Online-Kyoto-67-320.jpg)































![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)























![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)




















