Downloaded 28 times







![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
An Example of Hierarchically Organized Table
Real estate information can be naturally modeled by
case class Address(houseNumber: Int,
streetAddress: String,
city: String,
state: String,
zipCode: String)
case class Facts(price: Int,
size: Int,
yearBuilt: Int)
case class School(name: String)
case class Home(address: Address,
facts: Facts,
schools: List[School])](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-7-320.jpg)

![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
sql("select address.city from homes where facts.price > 2000000”)
.explain(true)
Find cities with houses worth more than 2M
== Physical Plan ==
*(1) Project [address#55.city AS city#75]
+- *(1) Filter (isnotnull(facts#56) && (facts#56.price > 2000000))
+- *(1) FileScan parquet [address#55,facts#56],
DataFilters: [isnotnull(facts#56), (facts#56.price > 2000000)],
Format: Parquet,
PushedFilters: [IsNotNull(facts)],
ReadSchema: struct<address:struct<houseNumber:int,streetAddress:string,
city:string,state:string,zipCode:strin…,
facts:struct(address:int…)>
• We only need two nested columns, address.city and facts.prices
• But entire address and facts are read](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-9-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
[SPARK-4502], [SPARK-25363] Parquet with Nested Columns
• Parquet is a columnar storage format with complex nested data
structures in mind
• Support very efficient compression and encoding schemes
• As a columnar format, each nested column is stored separately as if it's a
flattened table
• No easy way to cherry pick couple nested columns in Spark
• Foundation - Allow reading subset of nested columns right after Parquet
FileScan](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-10-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
sql("select address.city from homes where facts.price > 2000000”)
Find cities with houses worth more than 2M
== Physical Plan ==
*(1) Project [address#55.city AS city#77]
+- *(1) Filter (isnotnull(facts#56) && (facts#56.price > 2000000))
+- *(1) FileScan parquet [address#55,facts#56]
DataFilters: [isnotnull(facts#56), (facts#56.price > 2000000)],
Format: Parquet,
PushedFilters: [IsNotNull(facts)],
ReadSchema: struct<address:struct<city:string>,facts:struct<price:int>>
• Only two nested columns are read!
• With [SPARK-4502], [SPARK-25363]](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-11-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Find cities with houses worth more than 2M
== Physical Plan ==
*(1) Project [address#55.city AS city#77]
+- *(1) Filter (isnotnull(facts#56) && (facts#56.price > 2000000))
+- *(1) FileScan parquet [address#55,facts#56]
DataFilters: [isnotnull(facts#56), (facts#56.price > 2000000)],
Format: Parquet,
PushedFilters: [IsNotNull(facts)],
ReadSchema: struct<address:struct<city:string>,facts:struct<price:int>>
• Parquet predicate pushdown are not working for nested fields in Spark
sql("select address.city from homes where facts.price > 2000000”)
• With [SPARK-4502], [SPARK-25363]](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-12-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Find cities with houses worth more than 2M
== Physical Plan ==
*(1) Project [address#55.city AS city#77]
+- *(1) Filter (isnotnull(facts#56) && (facts#56.price > 2000000))
+- *(1) FileScan parquet [address#55,facts#56]
DataFilters: [isnotnull(facts#56), (facts#56.price > 2000000)],
Format: Parquet,
PushedFilters: [IsNotNull(facts), GreaterThan(facts.price,2000000)],
ReadSchema: struct<address:struct<city:string>,facts:struct<price:int>>
• Predicate Pushdown in Parquet for nested fields provides significant
performance gain by eliminating non-matches earlier to read less data
and save the cost of processing them
sql("select address.city from homes where facts.price > 2000000”)
• With [SPARK-25556]](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-13-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
val areaUdf = udf{ (city: String, state: String, zipCode: String) =>
s"$city, $state $zipCode"
}
val query = sql("select * from homes").repartition(1).select(
areaUdf(col("address.city"),
col("address.state"),
col("address.zipCode"))
).explain()
Applying an UDF after repartition
== Physical Plan ==
*(2) Project [UDF(address#58.city, address#58.state, address#58.zipCode) AS
UDF(address.city, address.state, address.zipCode)#70]
+- Exchange RoundRobinPartitioning(1)
+- *(1) Project [address#58]
+- *(1) FileScan parquet [address#58] Format: Parquet,
ReadSchema: struct<address:struct<houseNumber:int,streetAddress:string,
city:string,state:string,zipCode:string>>](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-14-320.jpg)

![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
[SPARK-25603] Generalize Nested Column Pruning
• [SPARK-4502], [SPARK-25363] are foundation to support nested
structures better with Parquet in Spark
• If an operator such as Repartition, Sample, or Limit are applied after
Parquet FileScan, nested column pruning will not work
• We address this by flattening the nested fields using Alias right after data
read](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-16-320.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
val query = sql("select * from homes").repartition(1).select(
areaUdf(col("address.city"),
col("address.state"),
col("address.zipCode"))
).explain()
Applying an UDF after repartition
== Physical Plan ==
*(2) Project [UDF(_gen_alias_84#84, _gen_alias_85#85, _gen_alias_86#86) AS UDF(address.city,
address.state, address.zipCode)#64]
+- Exchange RoundRobinPartitioning(1)
+- *(1) Project [address#55.city AS _gen_alias_84#84, address#55.state AS _gen_alias_85#85,
address#55.zipCode AS _gen_alias_86#86]
+- *(1) FileScan parquet [address#55]
ReadSchema: struct<address:struct<city:string,state:string,zipCode:string>>
• Nested fields are replaced by Alias with flatten structures
• Only three used nested fields are read from Parquet files](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-17-320.jpg)

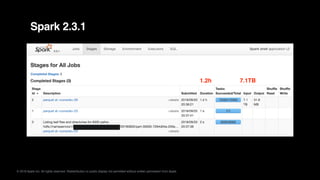
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Spark 2.4 with [SPARK-4502], [SPARK-25363], and [SPARK-25556]
3.3min 840GB
7.1TB1.2h](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-20-320.jpg)



![• [SPARK-4502]
• [SPARK-25363]
• [SPARK-25556]
• [SPARK-25603]](https://image.slidesharecdn.com/043016cesardelgadodbtsai-190508231536/85/Making-Nested-Columns-as-First-Citizen-in-Apache-Spark-SQL-24-320.jpg)


The document discusses advancements in Apache Spark SQL, particularly the handling of nested columns, which have become essential for processing large datasets efficiently. It highlights challenges with nested data structures, presents methods to improve performance through optimizations, such as better column pruning, and demonstrates significant performance gains with various Spark versions. The findings emphasize the importance of engineering rigor and optimization to achieve high scalability in data processing.























































































