Downloaded 734 times






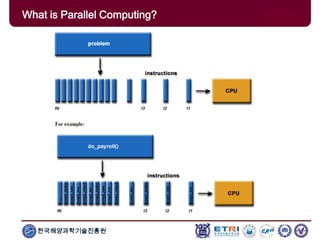

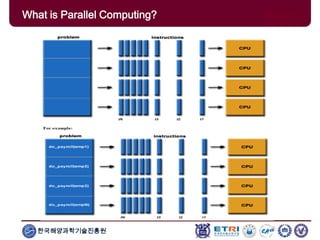













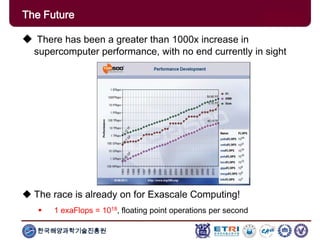
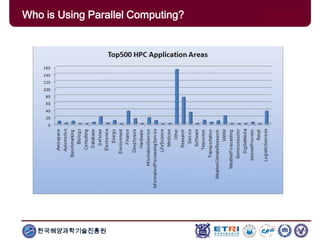
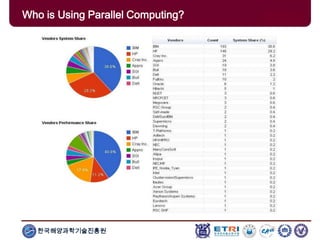







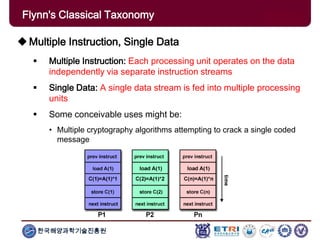








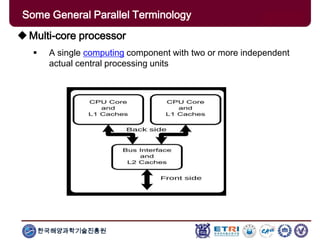


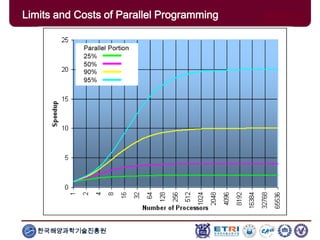





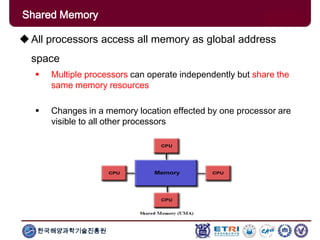

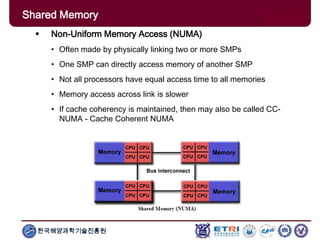

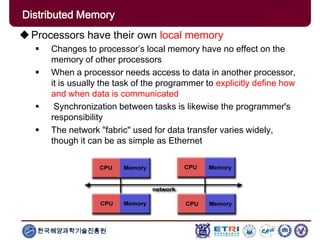

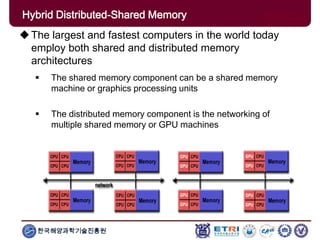










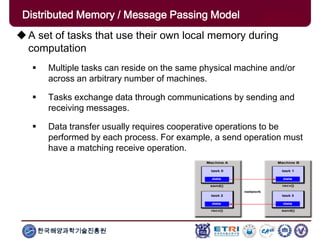
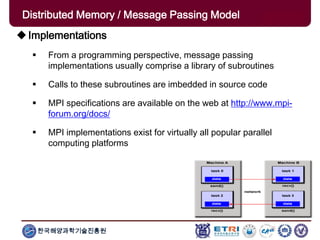
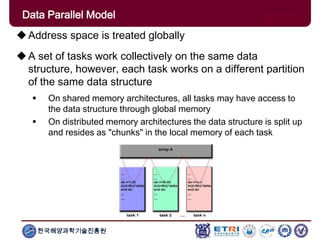

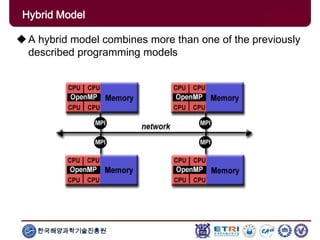







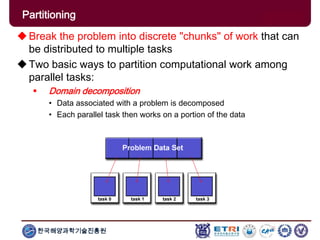
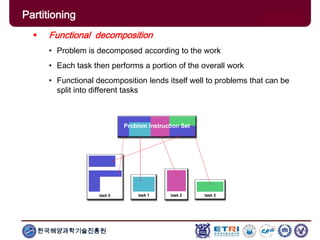





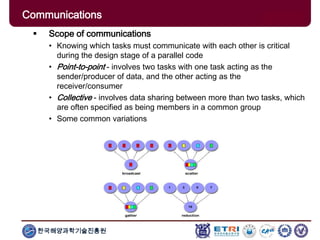

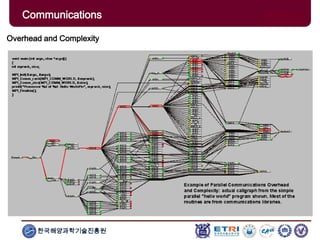






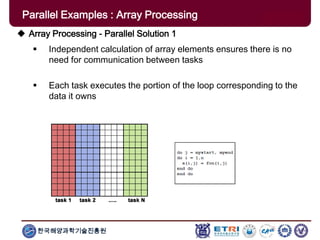







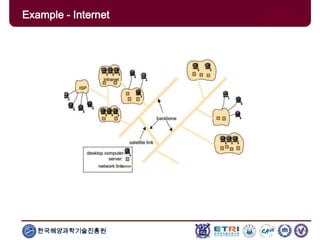
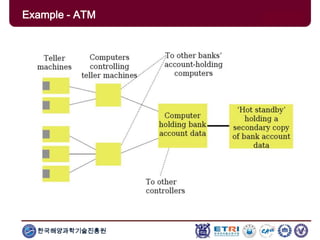
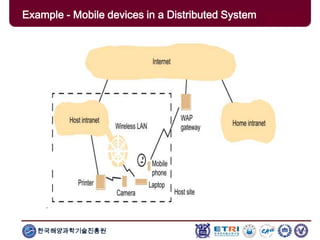










The document provides an introduction to parallel computing, describing its significance, architecture, and programming models. It emphasizes the advantages of using parallel computing in various fields including science, engineering, and commercial applications, while addressing the limitations and complexities associated with parallel programming. Moreover, it discusses memory architectures such as shared, distributed, and hybrid models, along with key concepts like scalability and communication.





















































































