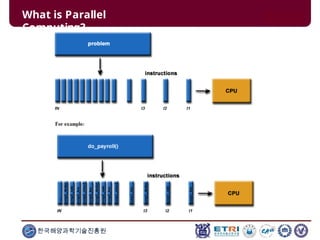
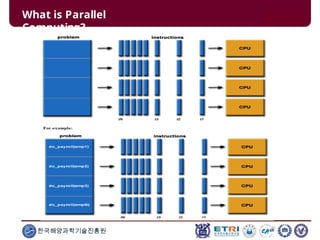
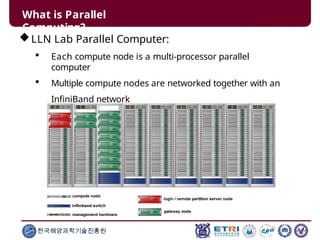
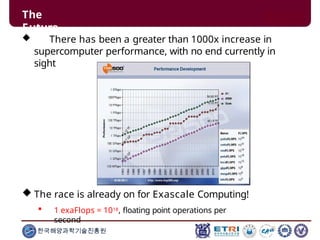
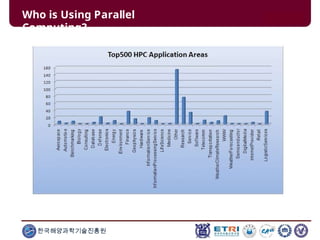
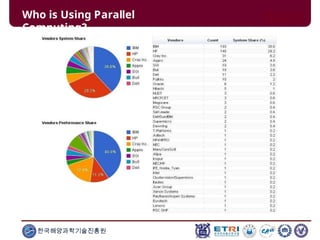
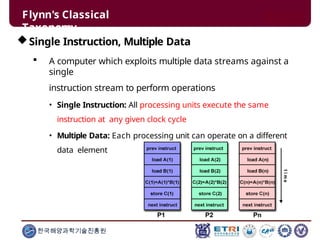
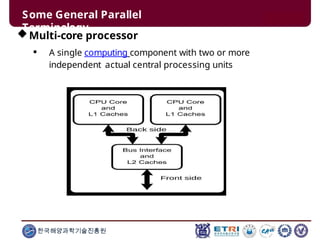
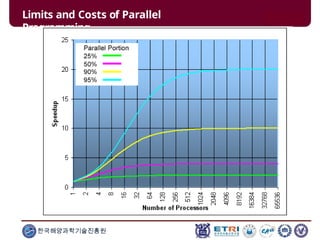
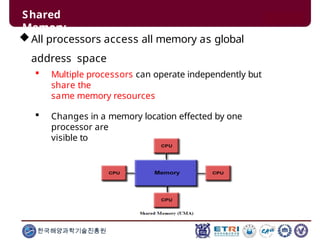
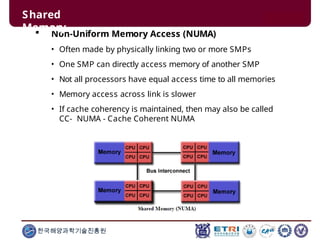
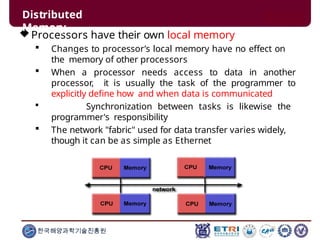
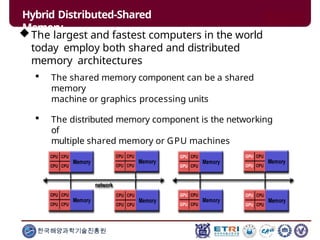
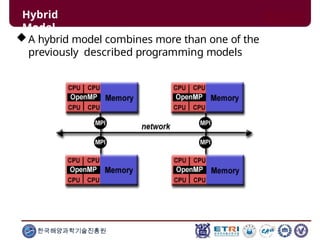
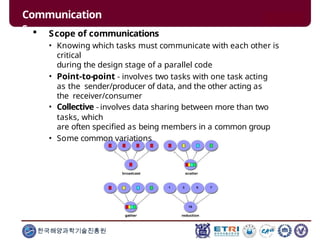
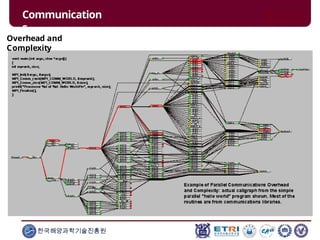
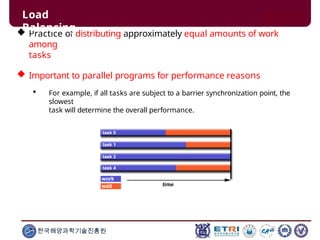
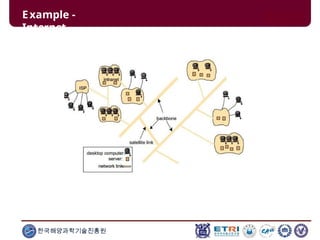
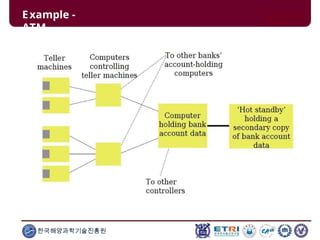
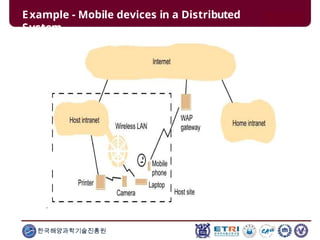
This document serves as an introduction to parallel computing, detailing its importance, methodologies, and applications in various fields such as science, engineering, and industry. It covers concepts like parallel memory architectures, programming models, and advantages over serial computing, highlighting the growing relevance of parallel systems in solving complex problems more efficiently. Additionally, it addresses the challenges of scalability, concurrency, and the intricacies involved in parallel programming.