Downloaded 55 times




























![Add extensions
38
# Evaluate the model with the test set at the end of each epoch
trainer.extend(extensions.Evaluator(tests_iter, model, device=0))
# Save a snapshot of the trainer at the end of each epoch
trainer.extend(extensions.snapshot())
# Collect performance, save it to a log file,
# and print some entries to the console
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss',
'main/accuracy', 'validation/main/accuracy']))
# Print a progress bar
trainer.extend(extensions.ProgressBar())](https://image.slidesharecdn.com/20160720chainer-intro-160720060414/75/Introduction-to-Chainer-38-2048.jpg)



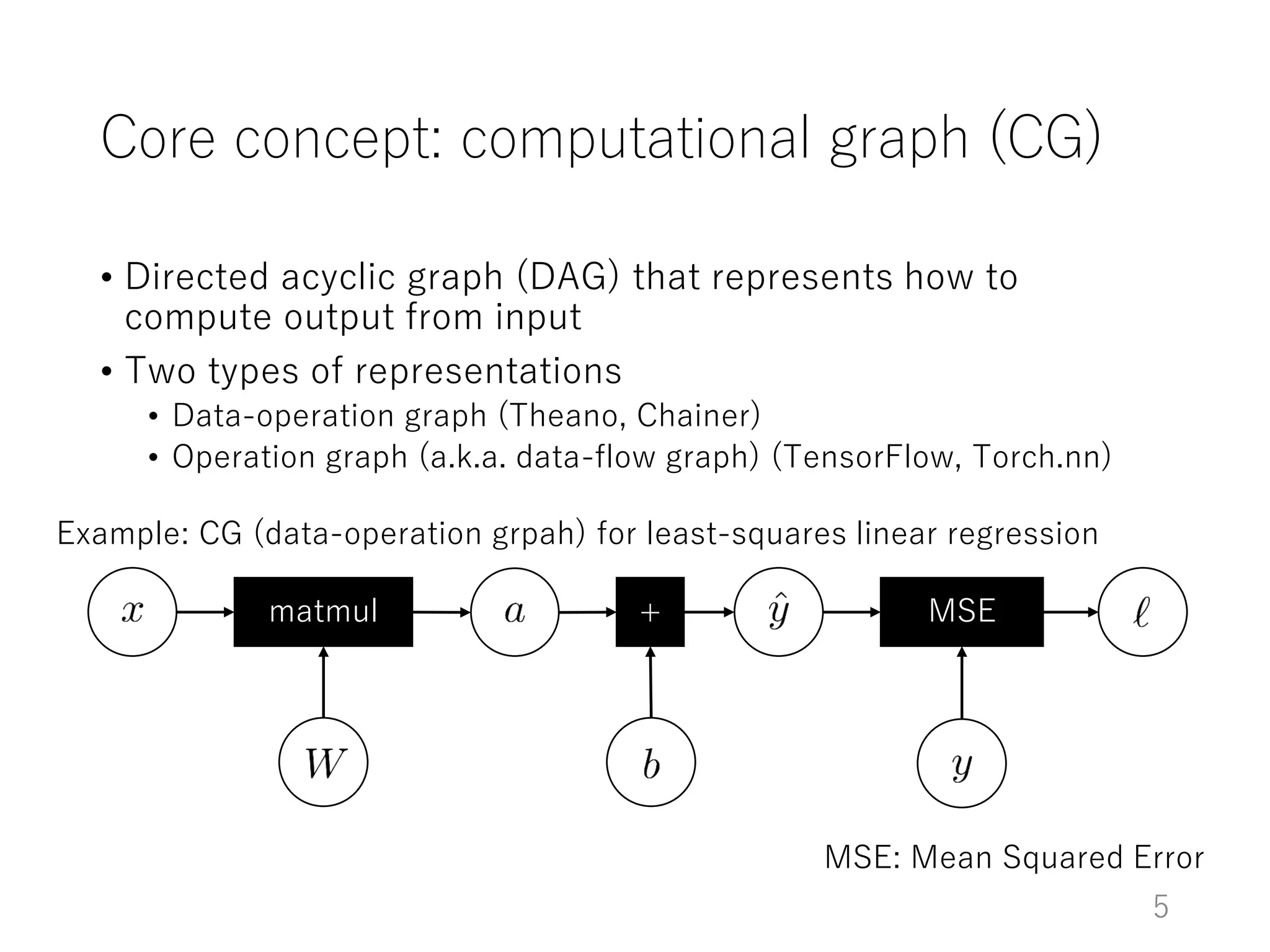
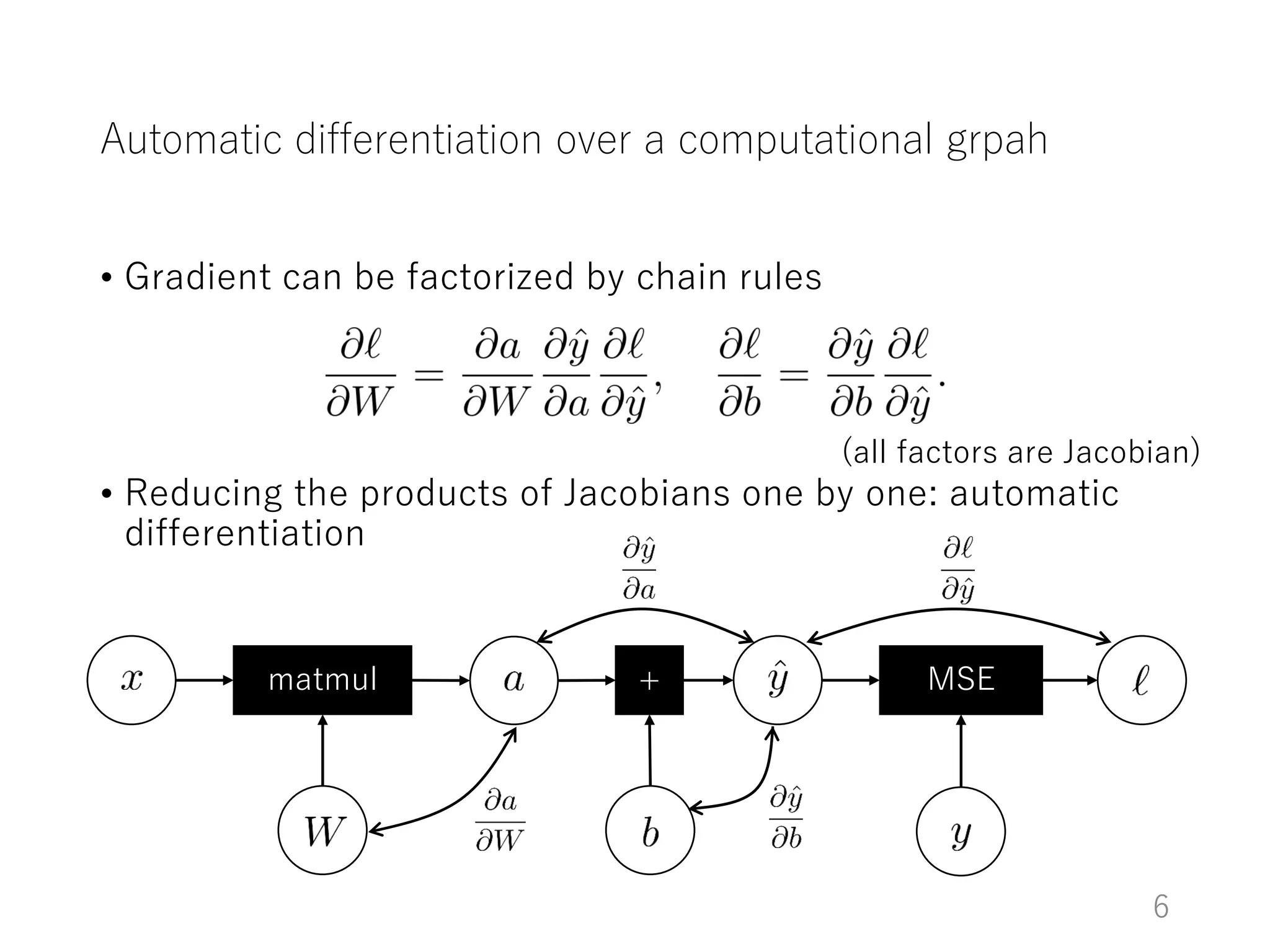
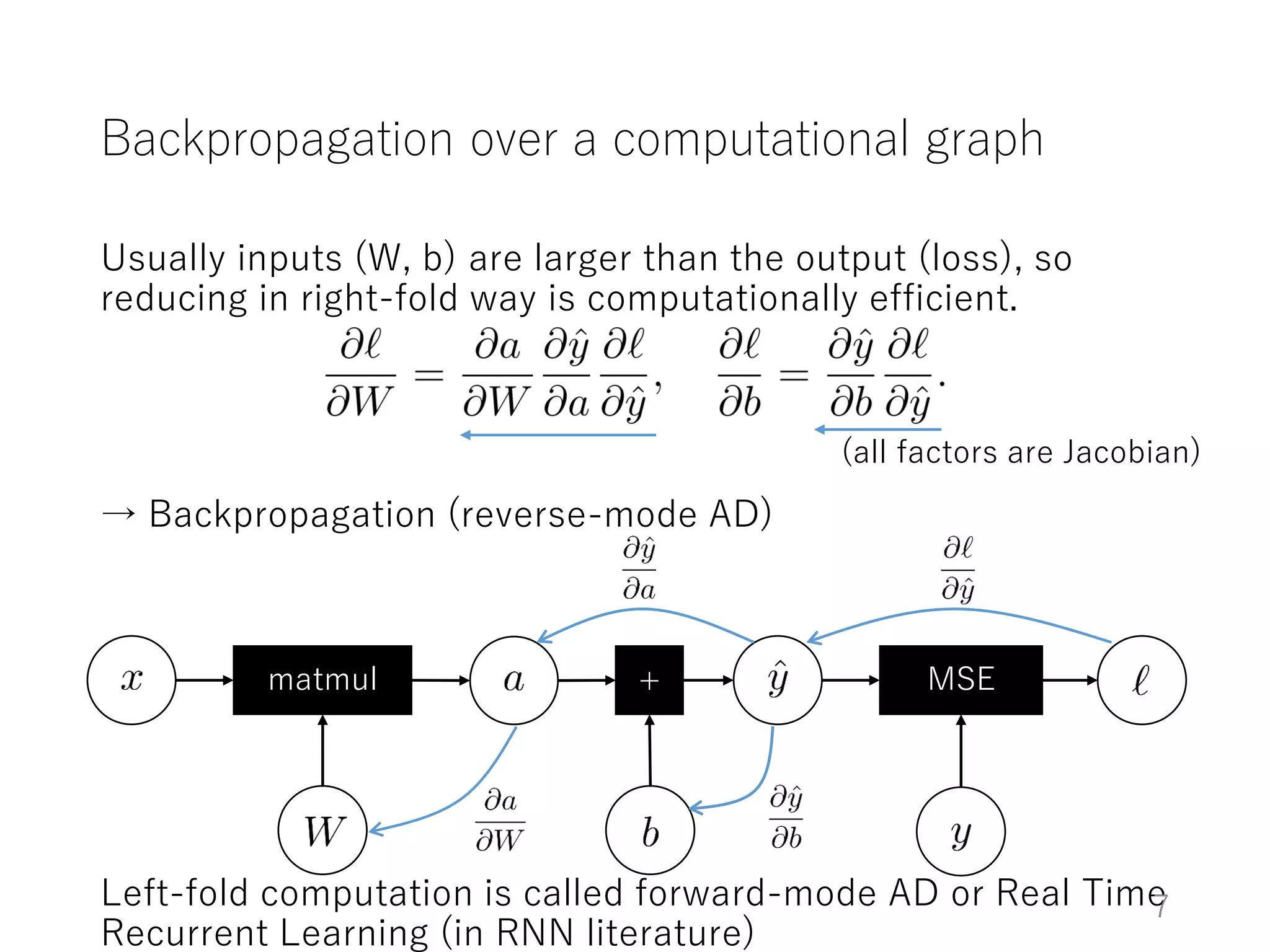
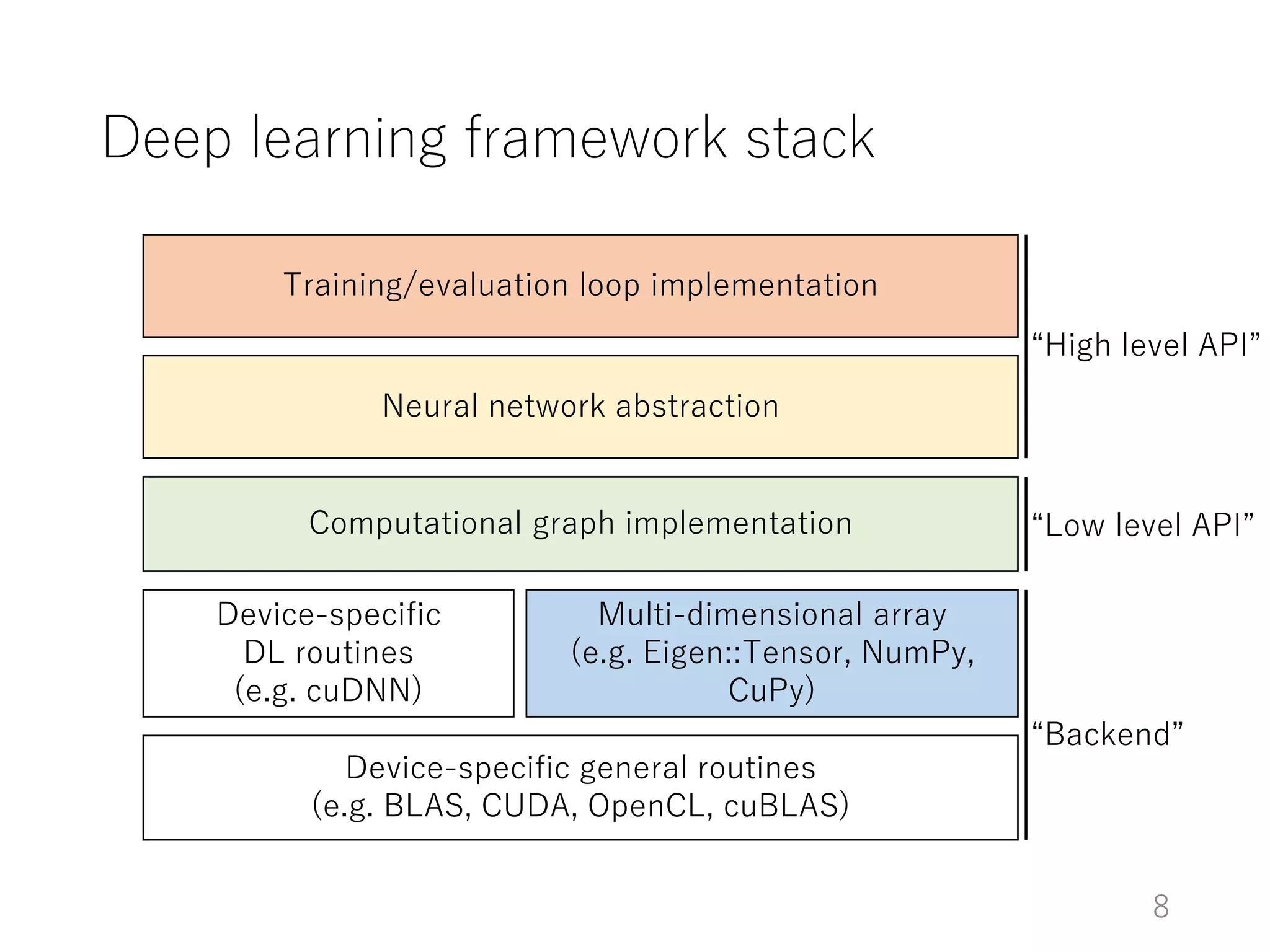
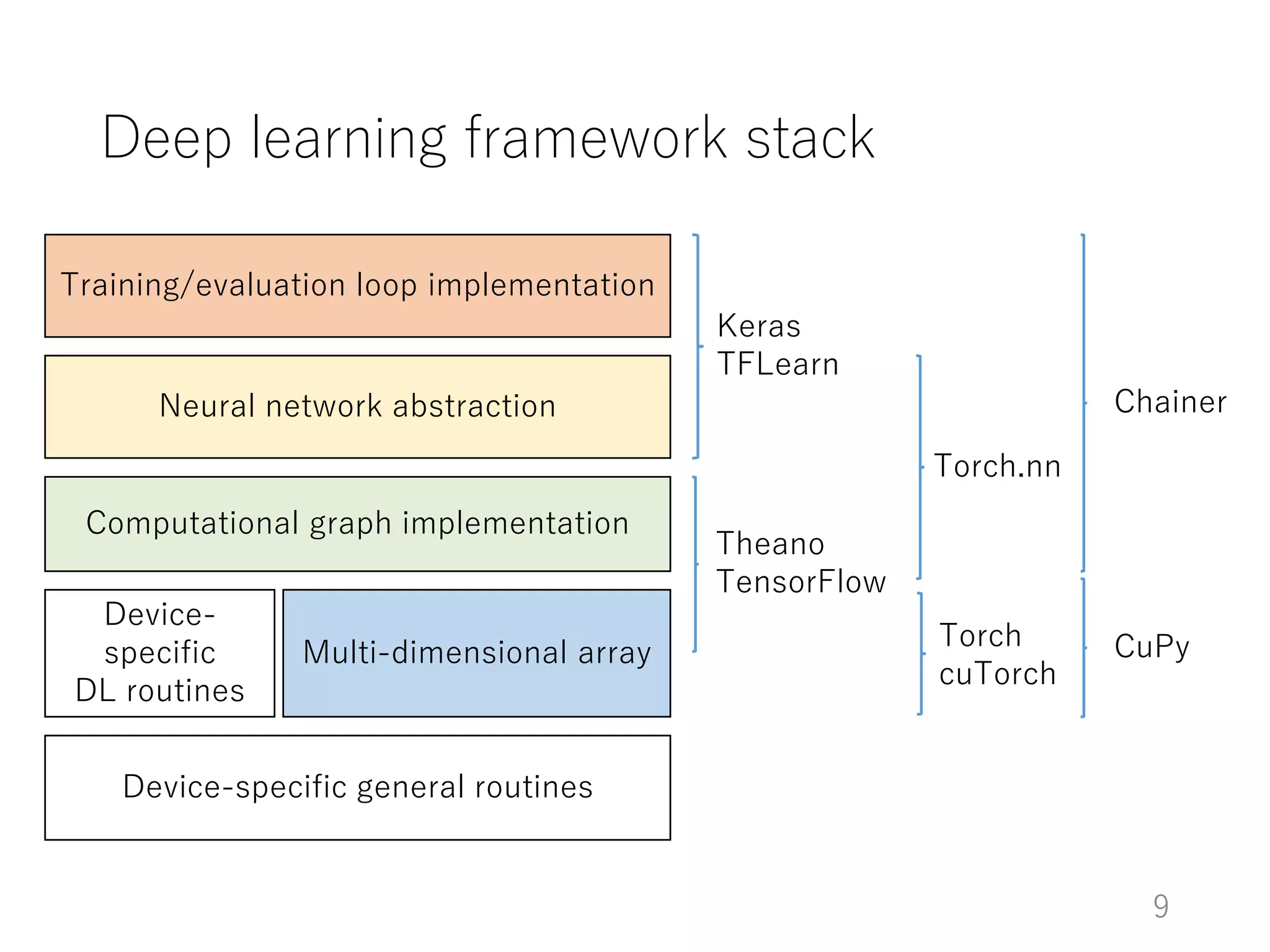
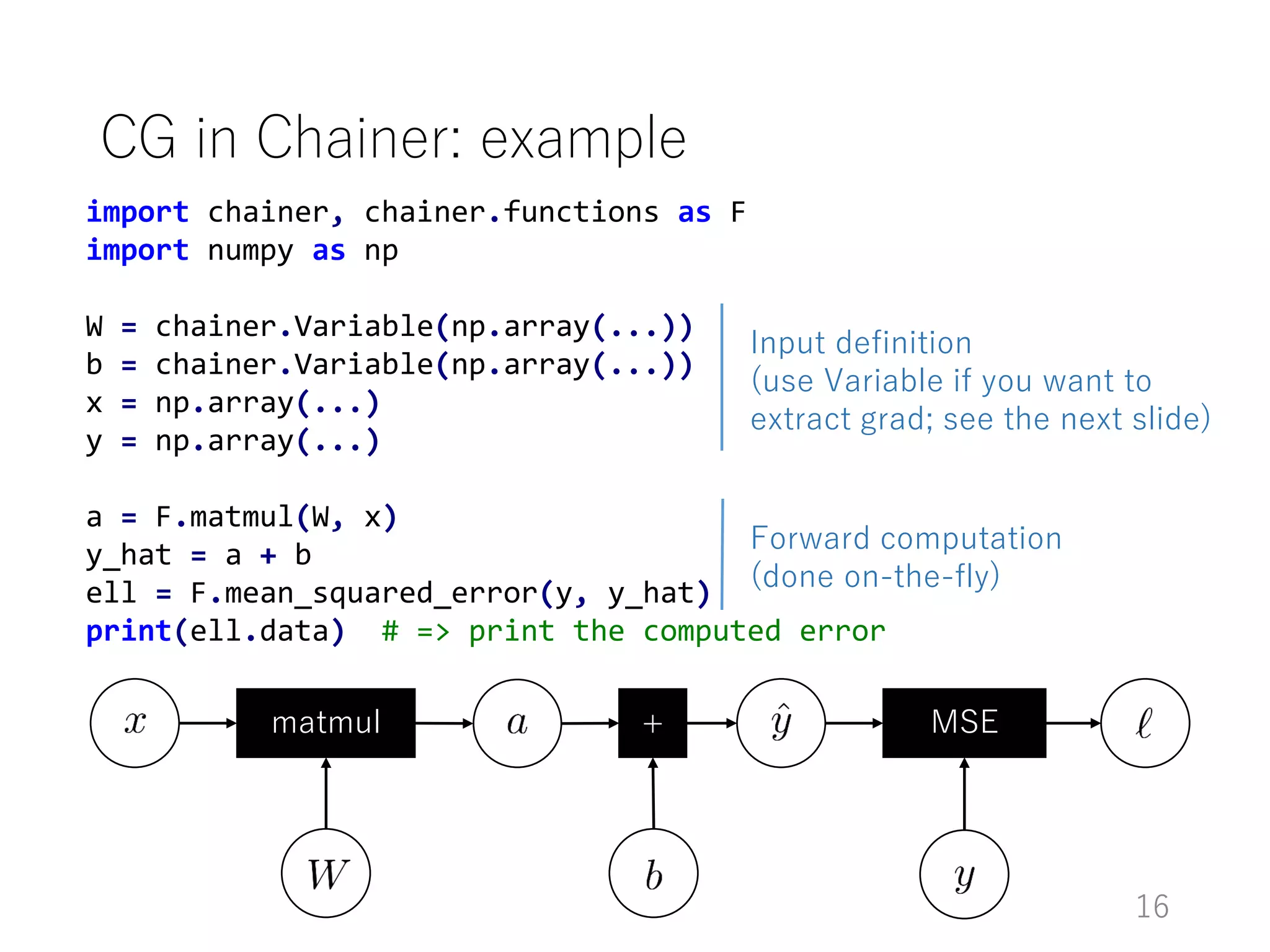
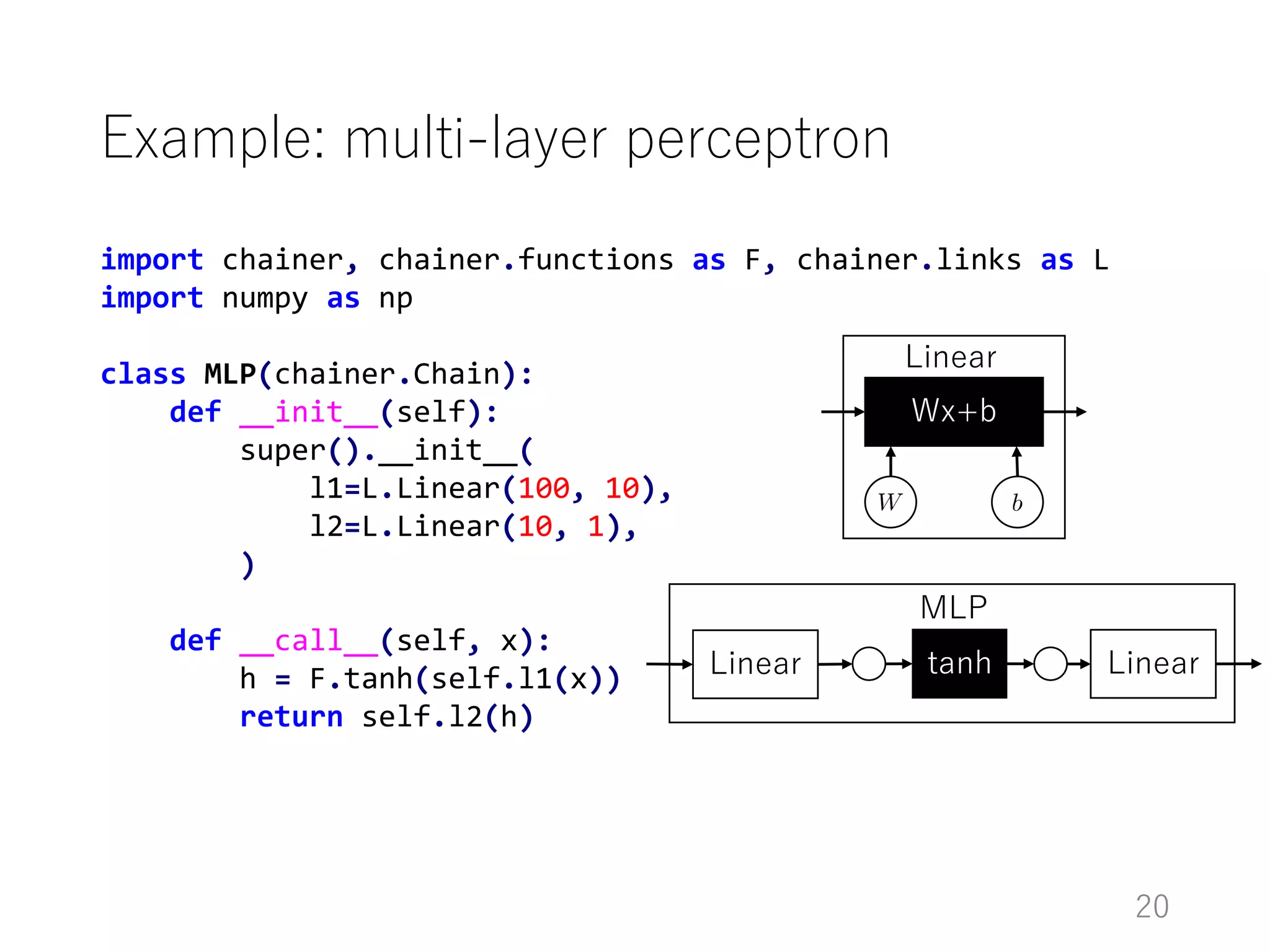
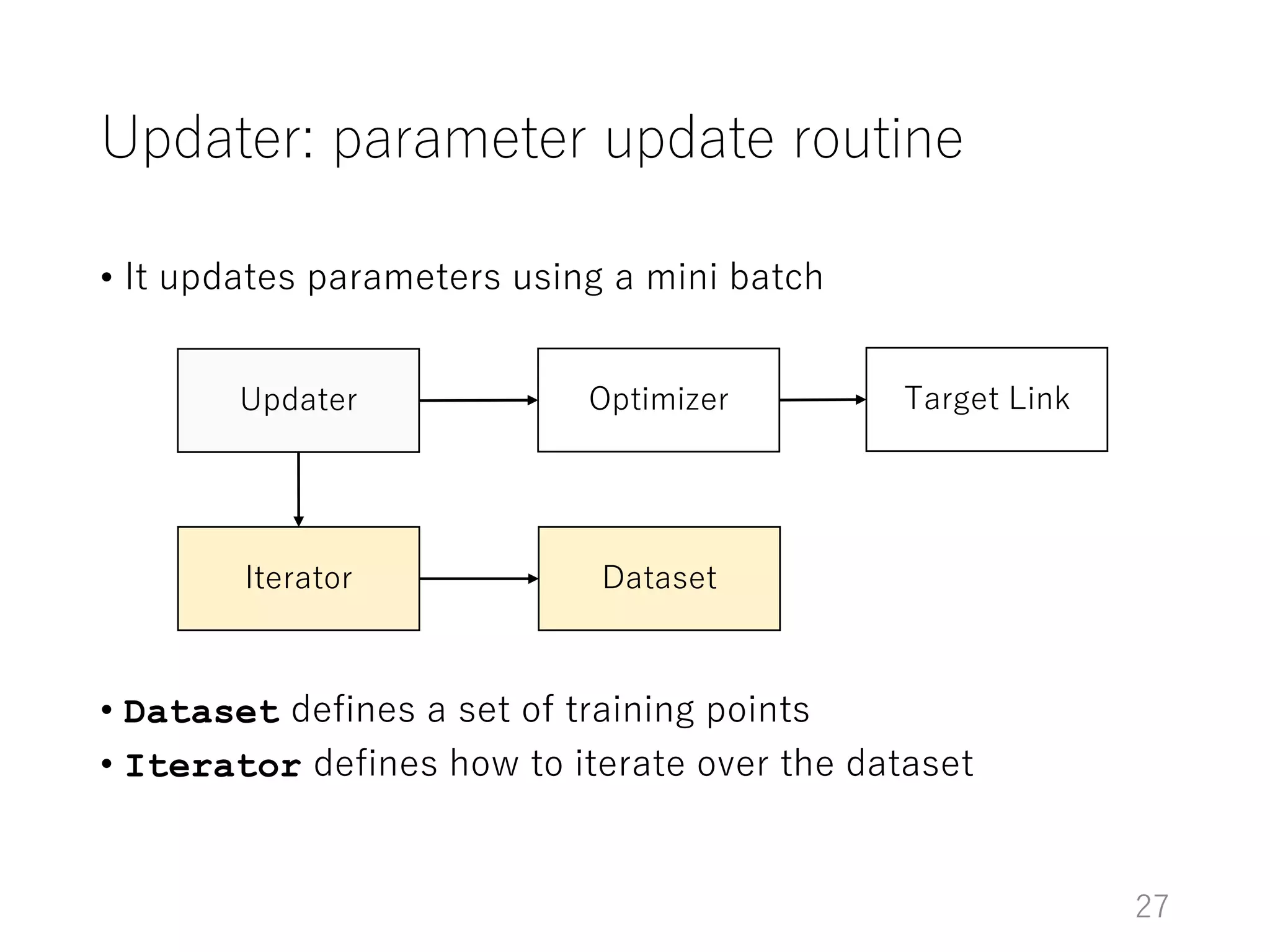
The document introduces Chainer, an open-source framework for neural networks, highlighting its core concepts such as computational graphs, automatic differentiation, and backpropagation. It discusses the features of Chainer version 1.11, including dynamic computational graphs, model abstractions, and built-in datasets and optimizers. Additionally, it provides an example of using Chainer with the MNIST dataset for classification tasks, illustrating the setup of models, training loops, and performance evaluation.

































![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)




















































