ICML2013読み会 Local Deep Kernel Learning for Efficient Non-linear SVM Prediction
1.
Local Deep KernelLearning
for Efficient Non-linear SVM Prediction
読み人: 得居 誠也 @beam2d
(Preferred Infrastructure)
2013-07-09
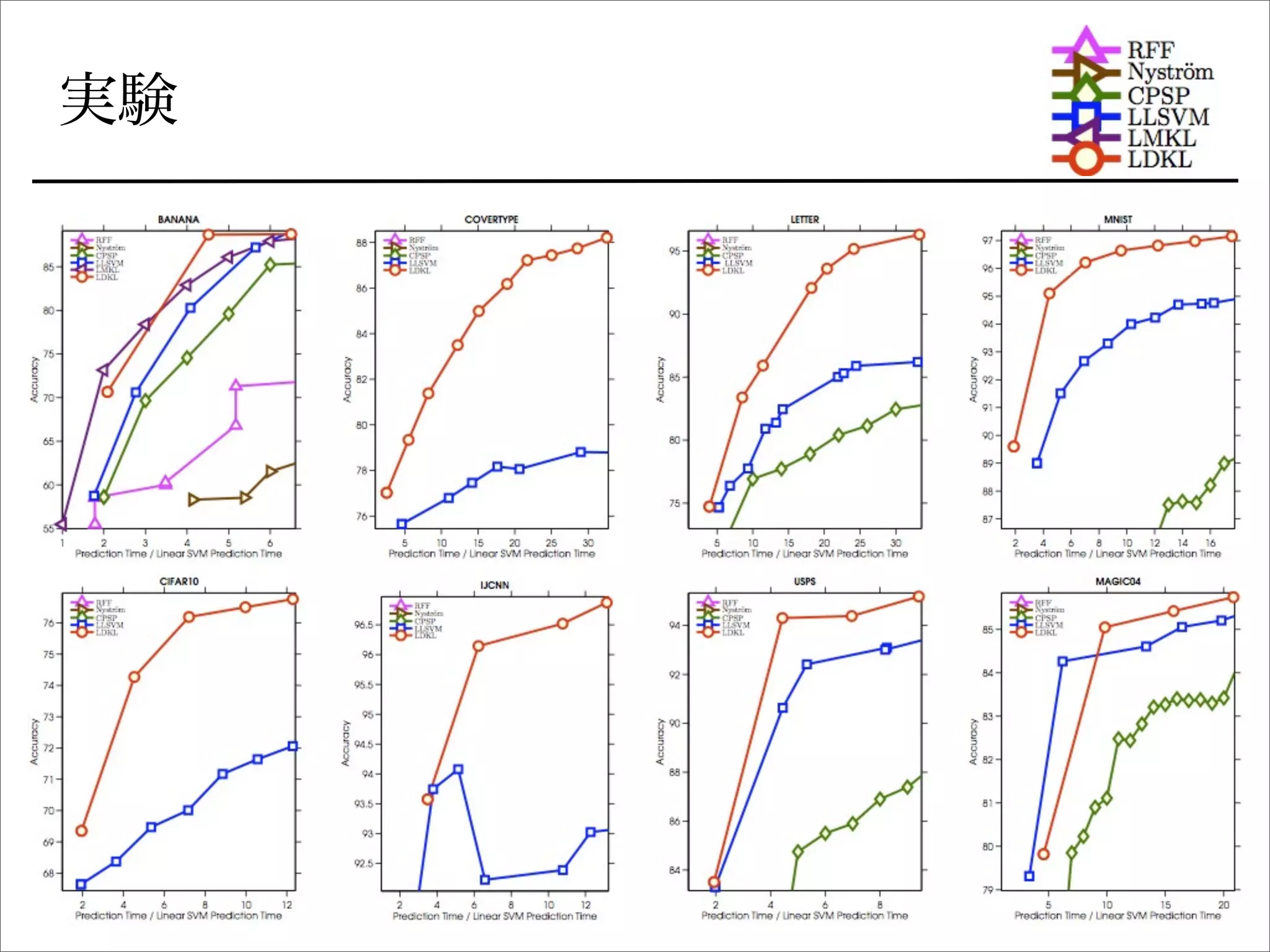
ICML 13読み会
Cijo Jose*, Prasoon Goyal*, Parv Aggrwal*, Manik Varma**
* Indian Institute of Technology Dehli
** Microsoft Research India
LDKLのカーネル=
局所カーネル 大域カーネル
K(xi, xj)= KL(xi, xj)KG(xi, xj)
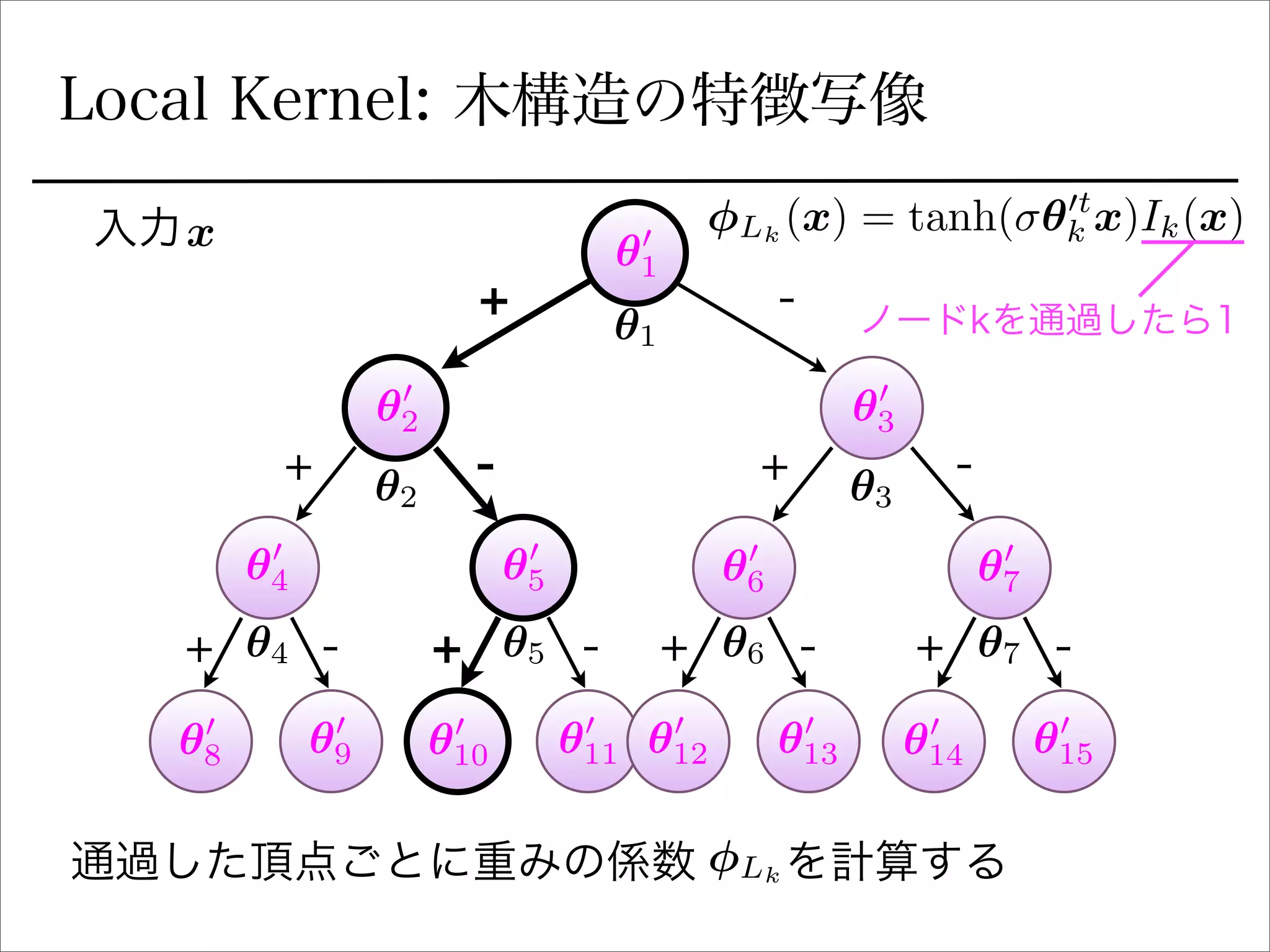
Local Kernel
(特徴写像 )L
Global Kernel
(特徴写像 )G
• の特徴写像は (クロネッカー積)
• 今回は とする(線形カーネル)
- 特徴写像を陽に書ければなんでも良い
- e.g.)
K L ⌦ G
G(x) = x
G(x) = x ⌦ x
LDKLの最適化は主空間でのSGD
rwk
P(xi) = Wwk iyi Lk
(xi)xi,
r✓k
P(xi) = ⇥✓k iyi
X
l
tanh( ✓0t
l xi)r✓k
Il(xi)wt
l xi
r✓0
k
P(xi) = ⇥0 ✓0
k iyi (1 tanh2
( ✓0t
k xi))Ik(xi)wt
kxixi.
• = のマージンが1未満なら1, そうでなければ0
• 下線部以外は簡単に計算できる
i xi
勾配は次式
18.
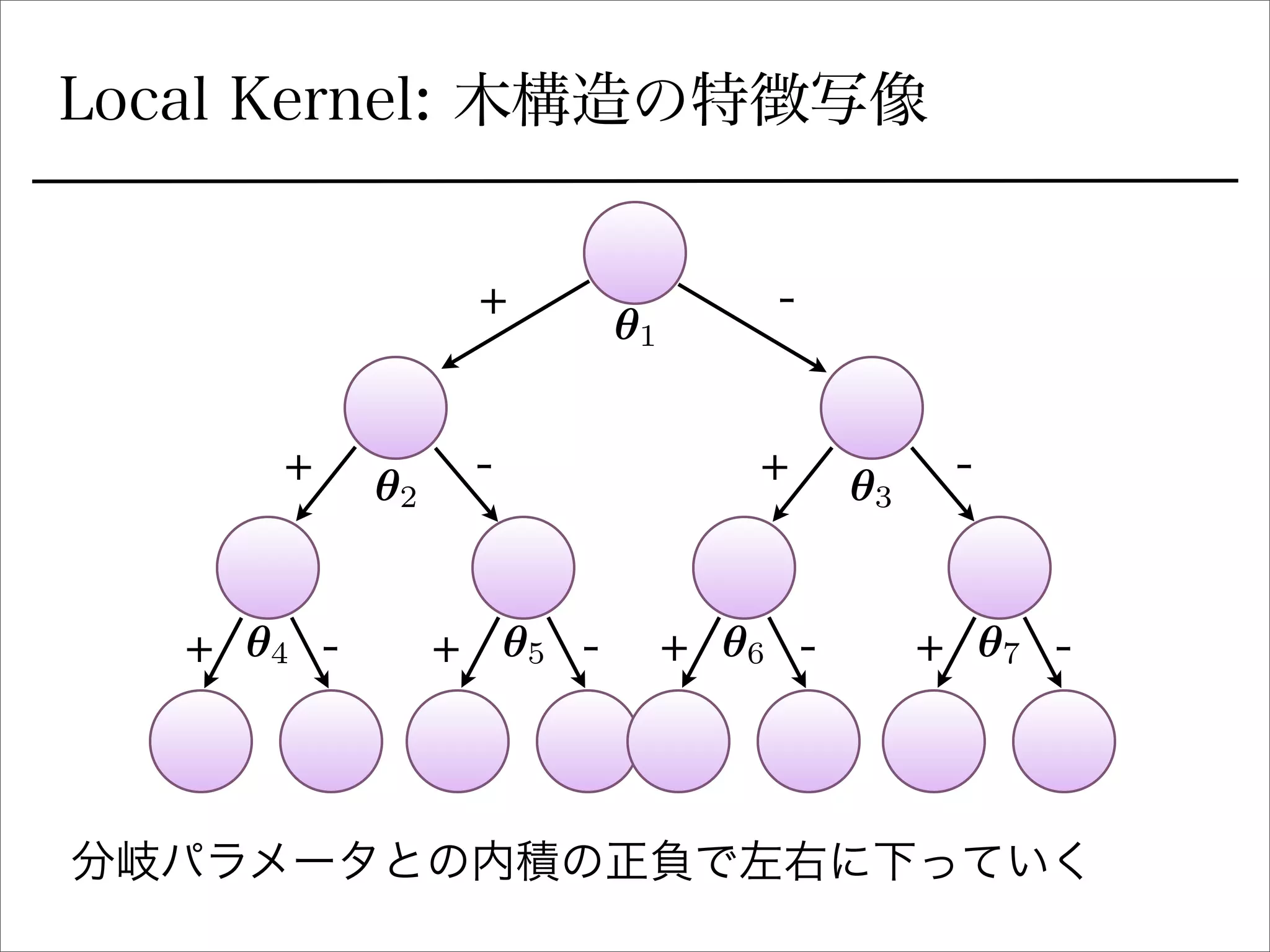
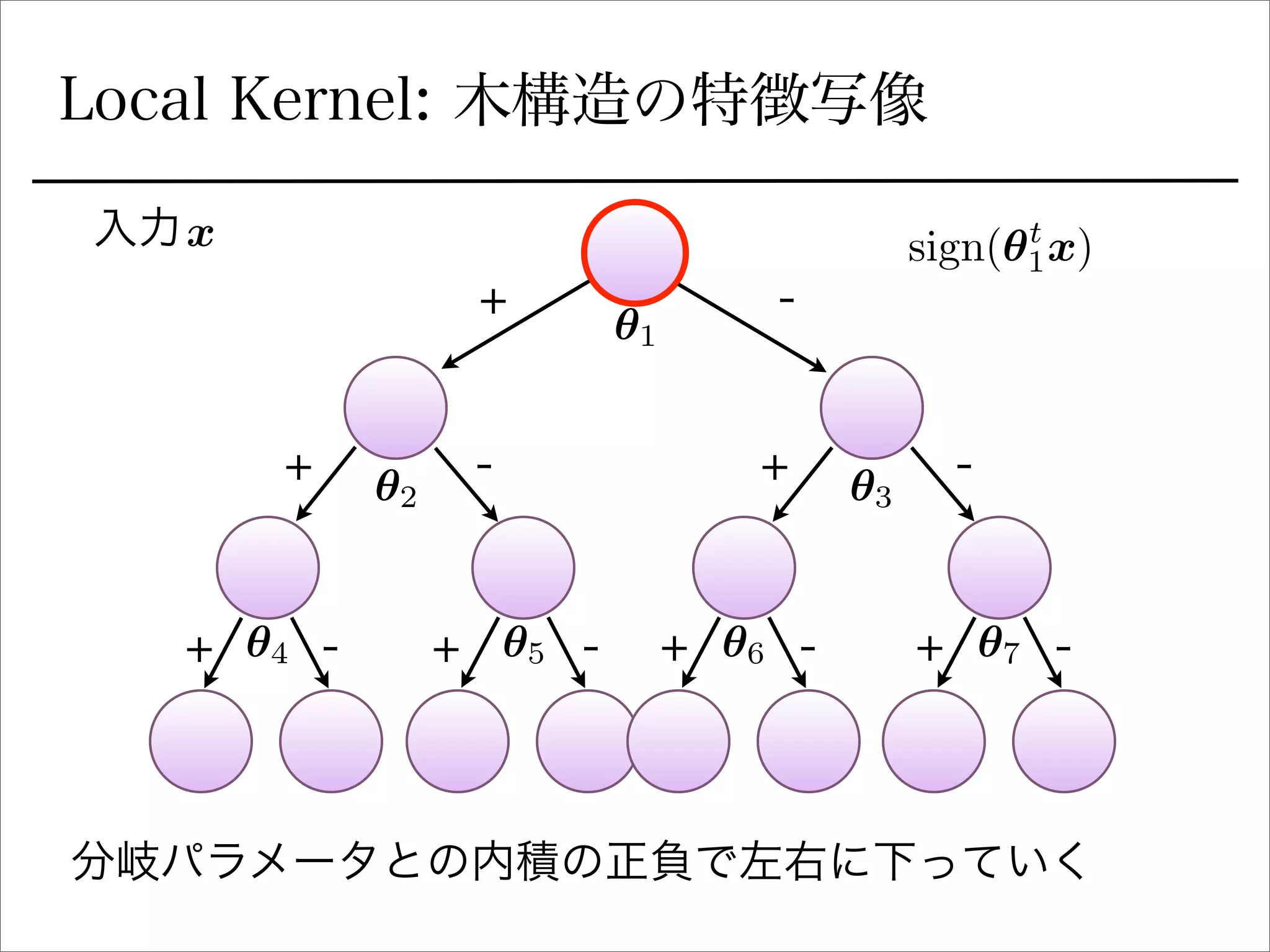
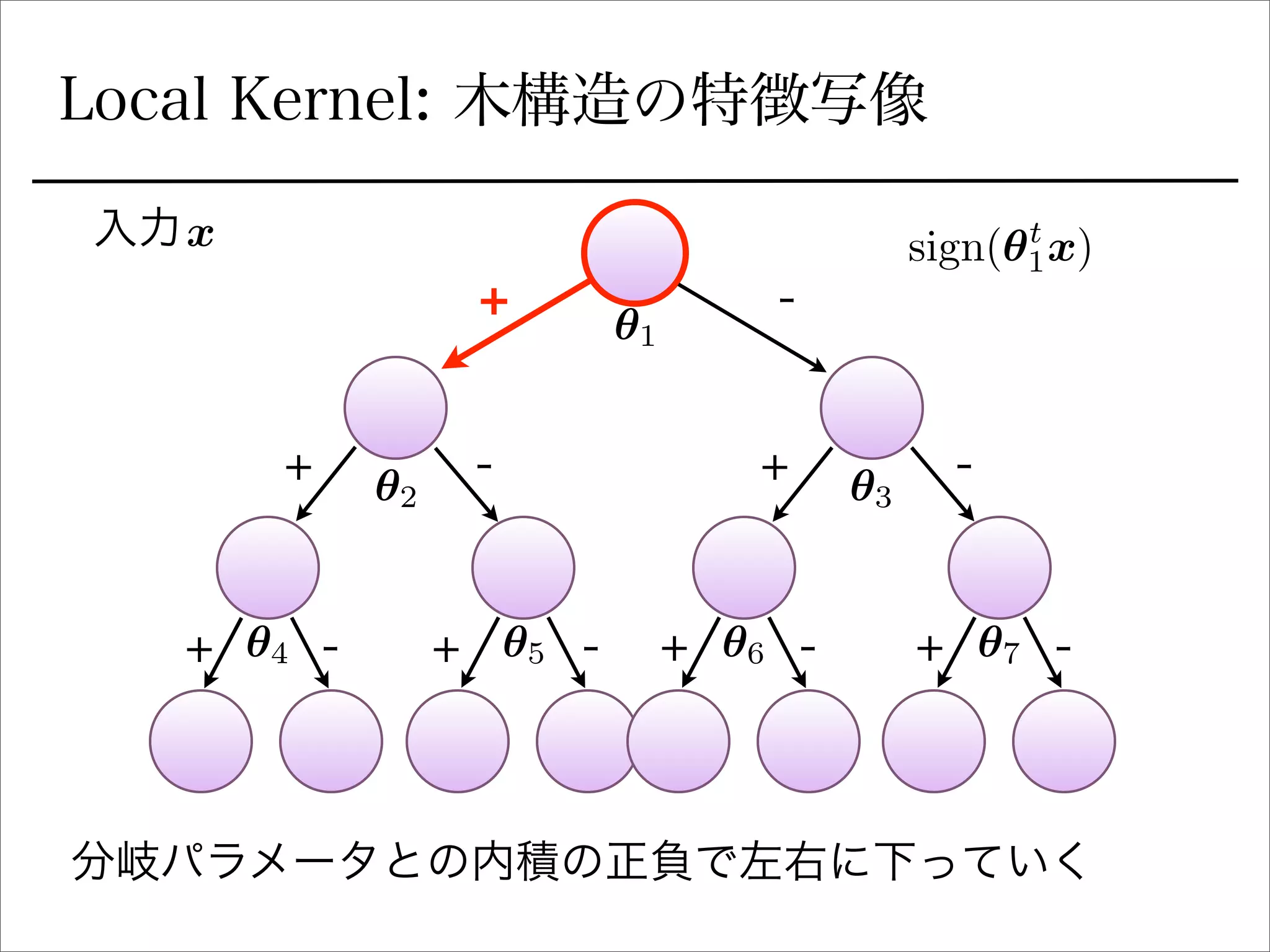
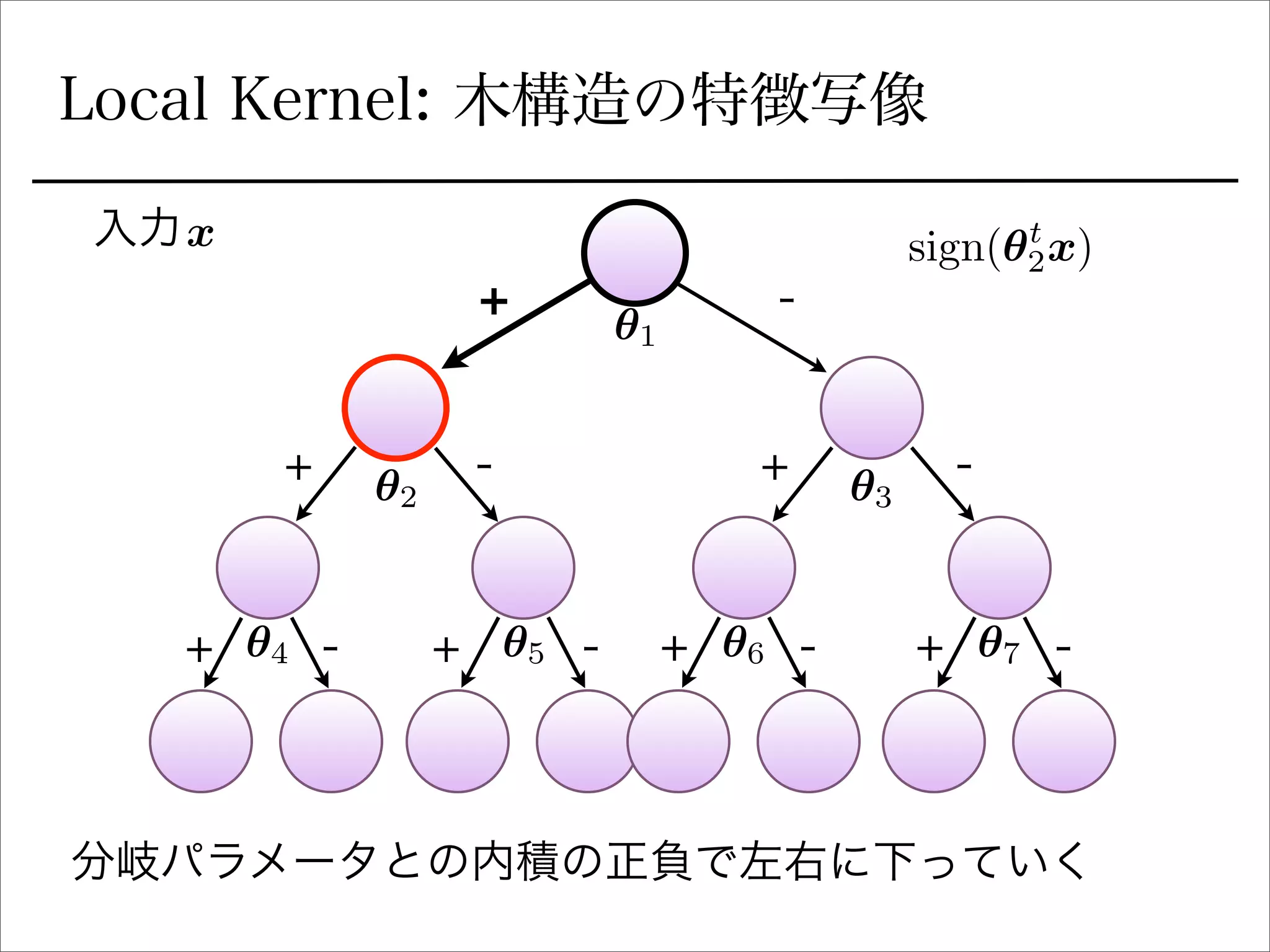
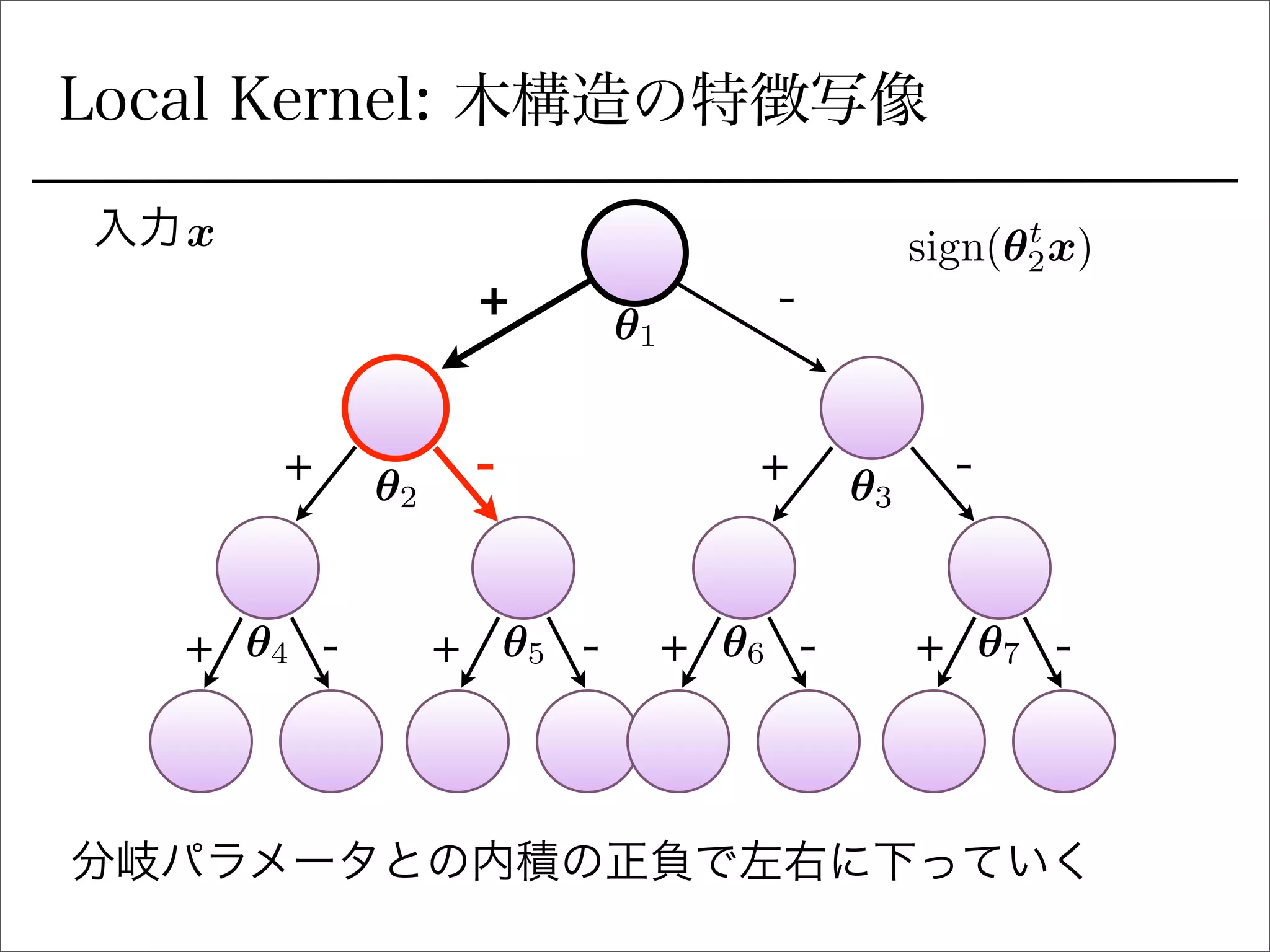
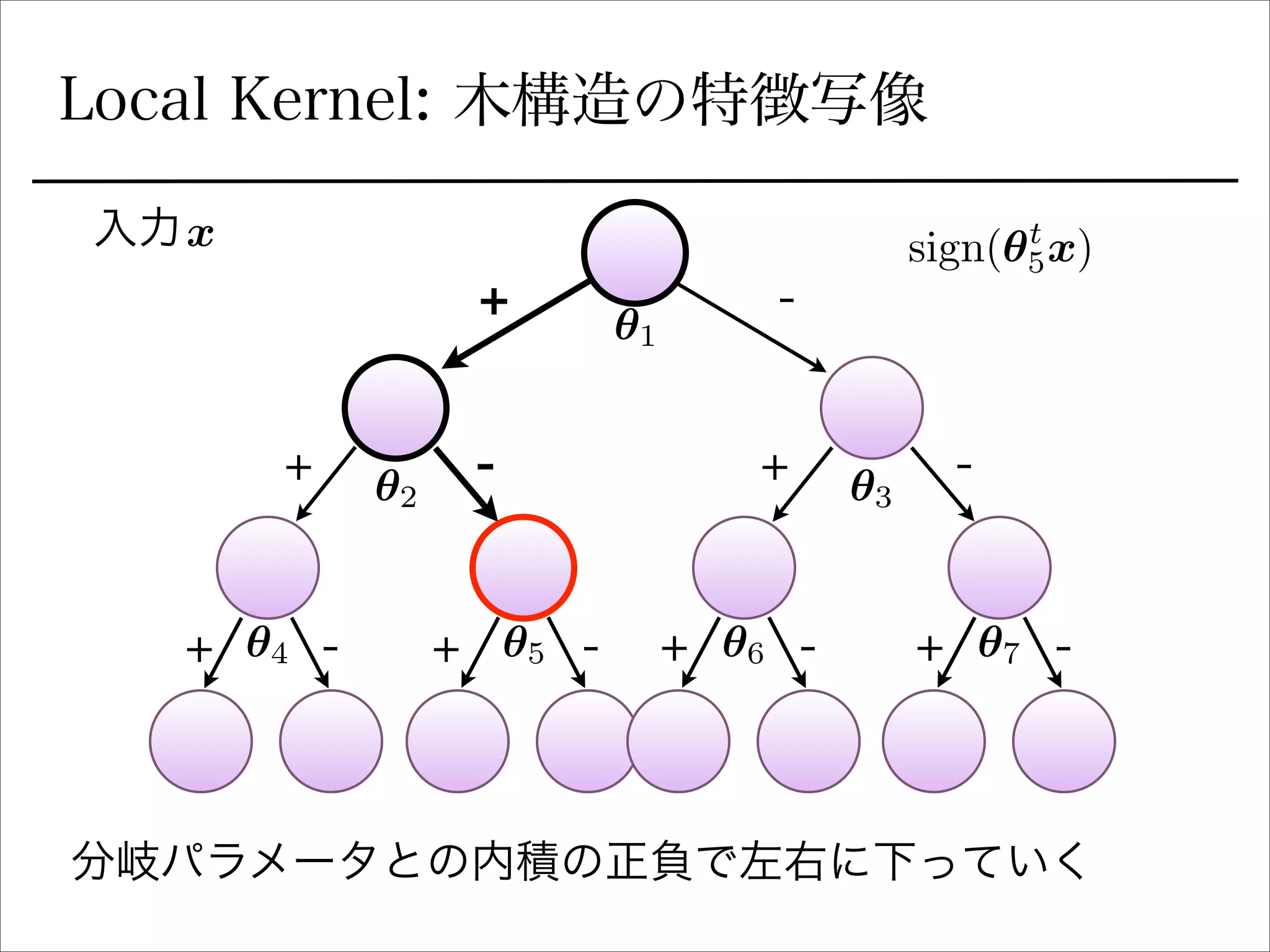
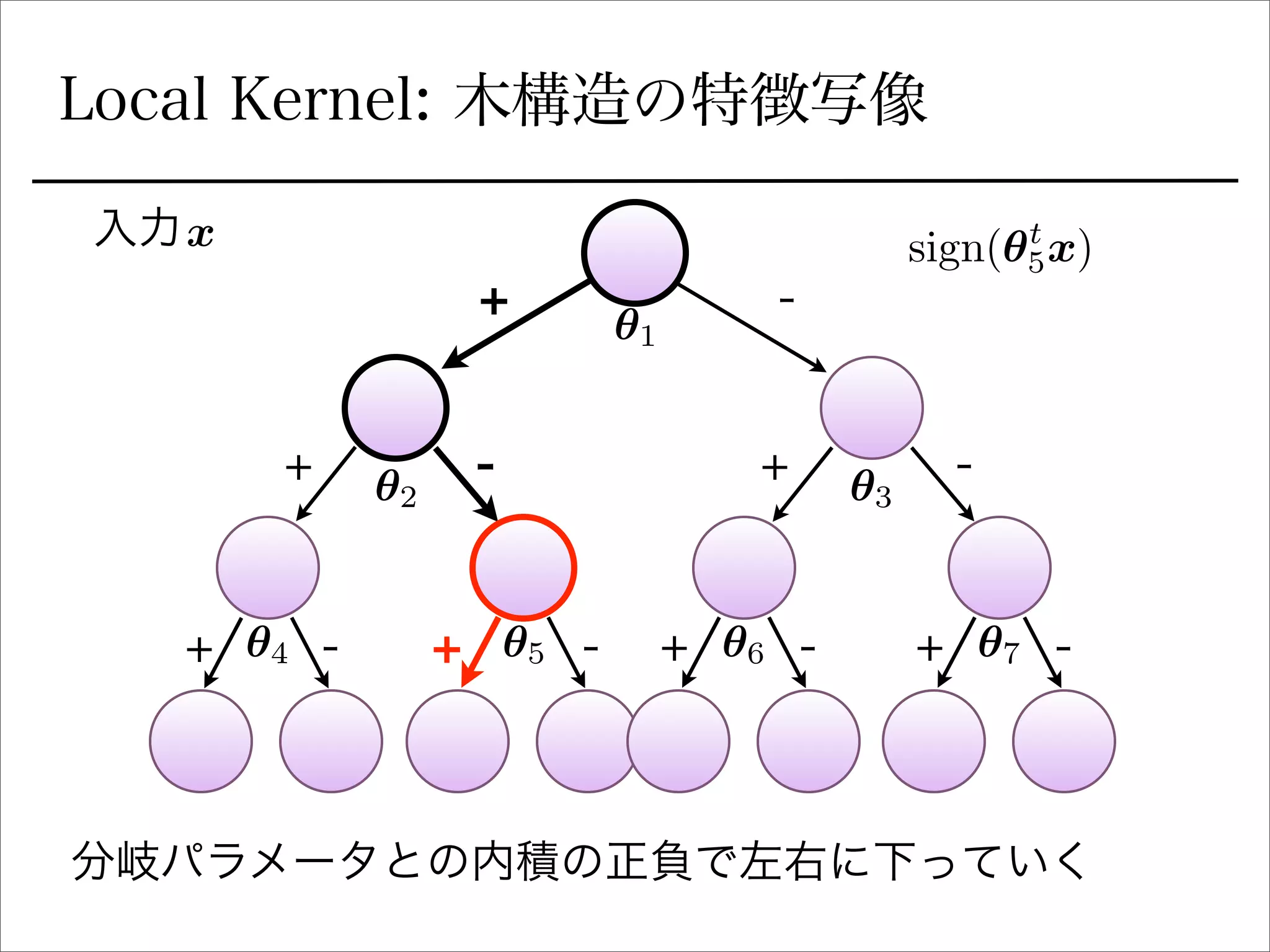
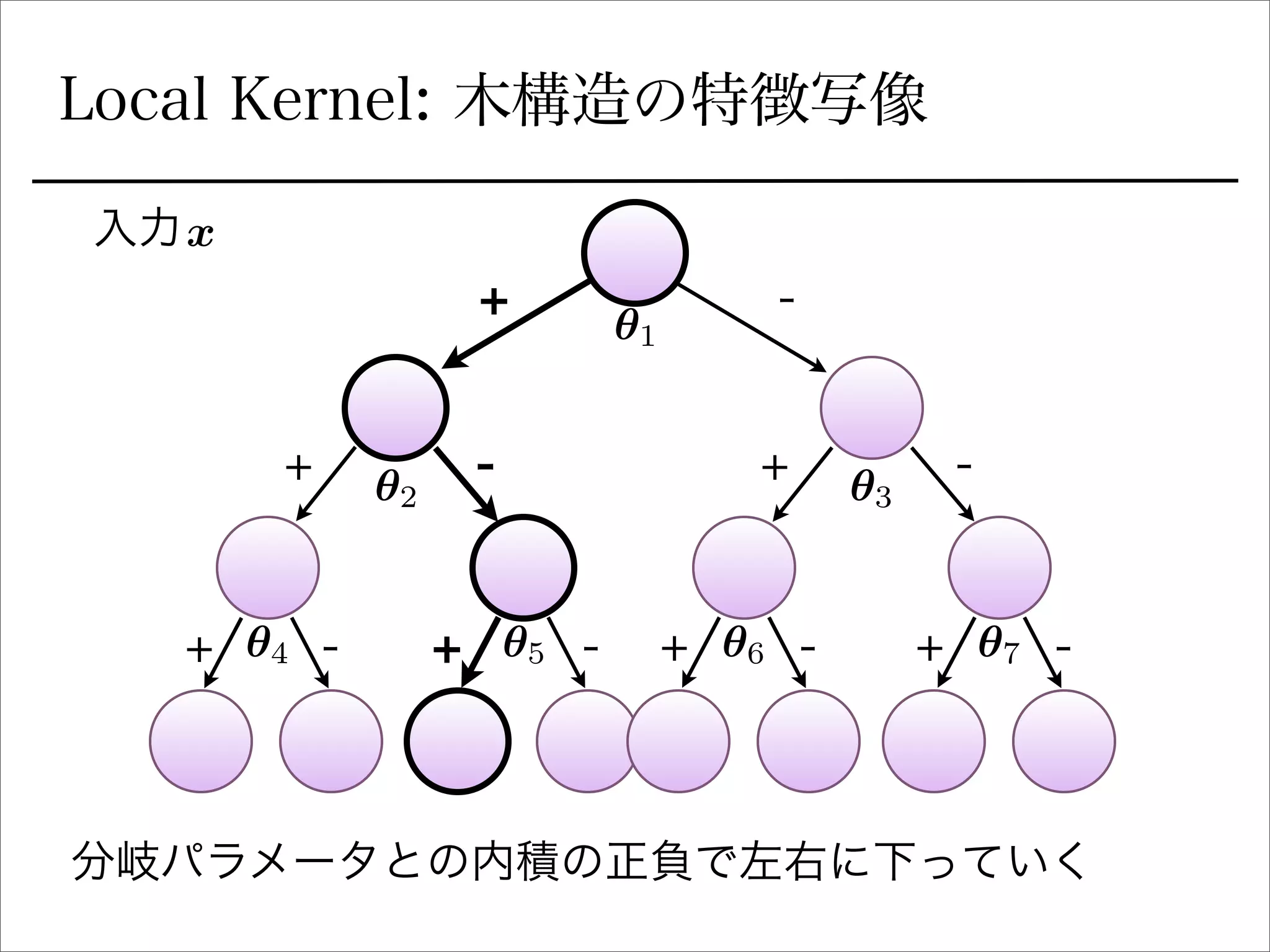
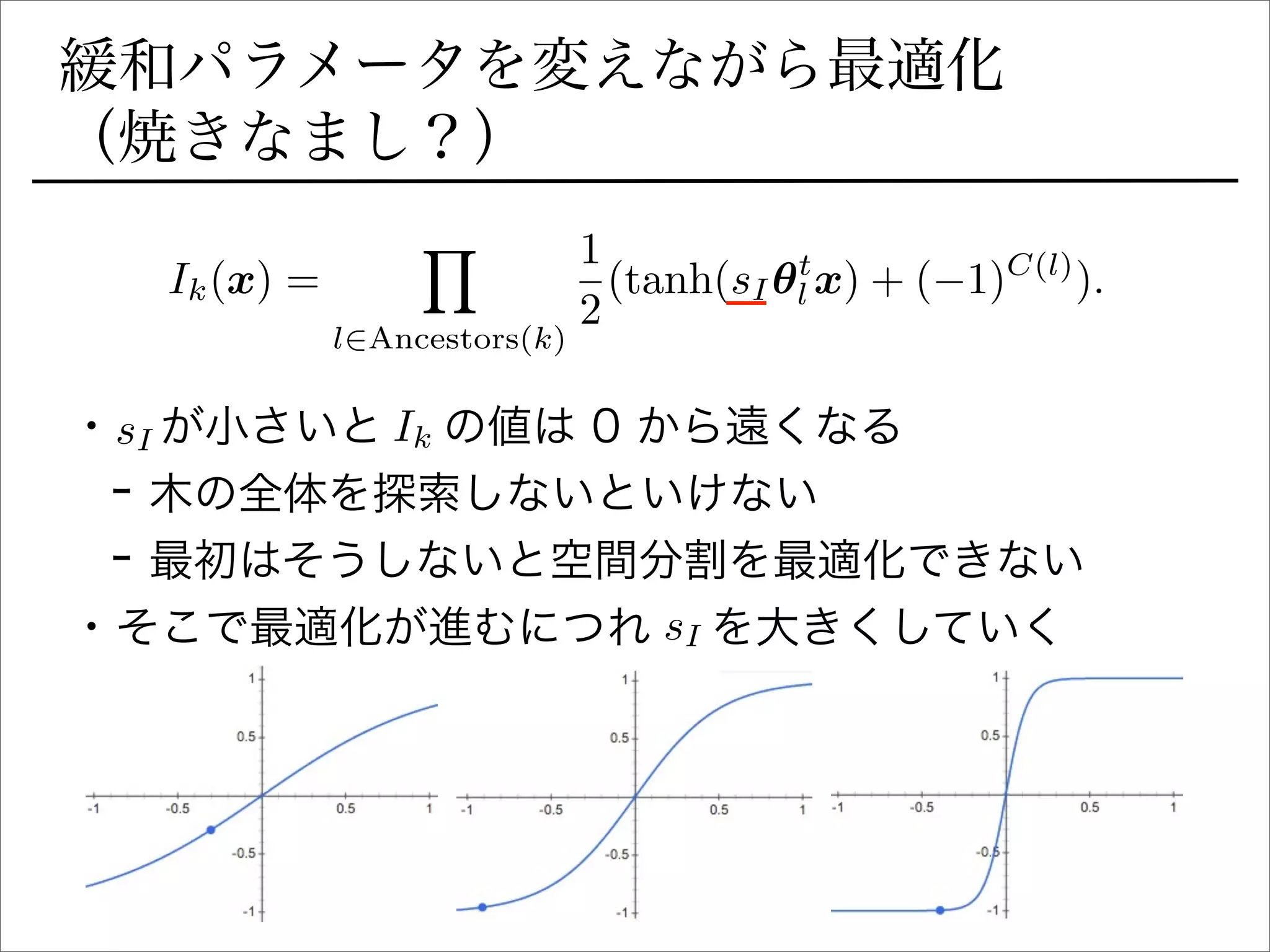
空間分割の最適化
sign関数を緩和
Ik(x) =
Y
l2Ancestors(k)
1
2
(sign(✓t
l x)+ ( 1)C(l)
).
を陽に書き下すとIk 右に行くか左に行くか (1 or 0)
signの部分を最適化できるように緩和:
Ik(x) =
Y
l2Ancestors(k)
1
2
(tanh(sI✓t
l x) + ( 1)C(l)
).
r✓l
Ik(x) = Ik(x)(tanh(sI✓t
l x) + ( 1)C(l)
) l2Ancestors(k)sIx.


![既存手法
局所的な分類器: 既存研究あり
• Locally Linear SVM [Ladicky+, ICML 11]
• 複数の線形分類器を, 場所ごとに異なる重み付けで
足し合わせる
• 重み付けはLocal Coordinate Codingなど
(unsupervised)
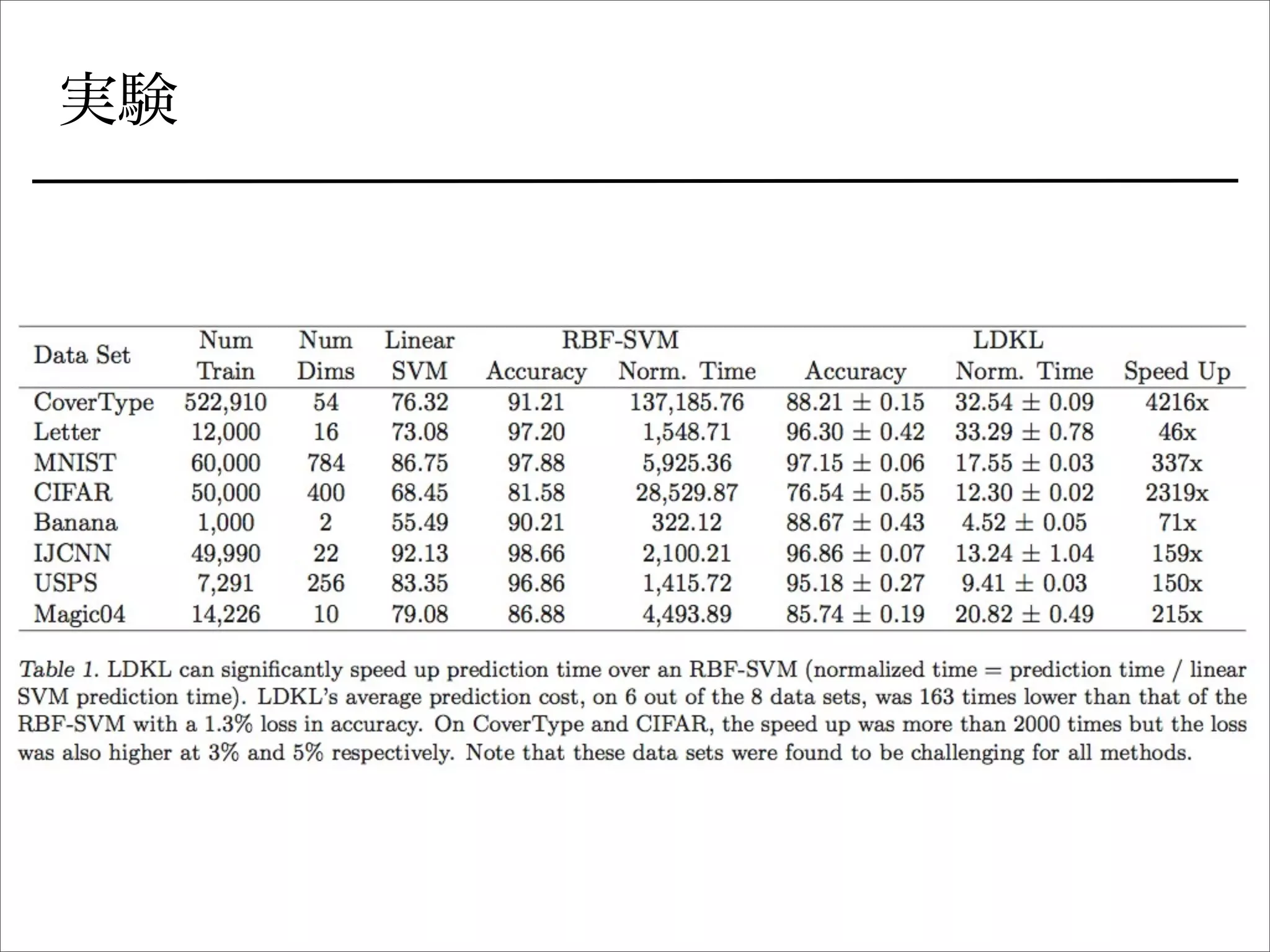
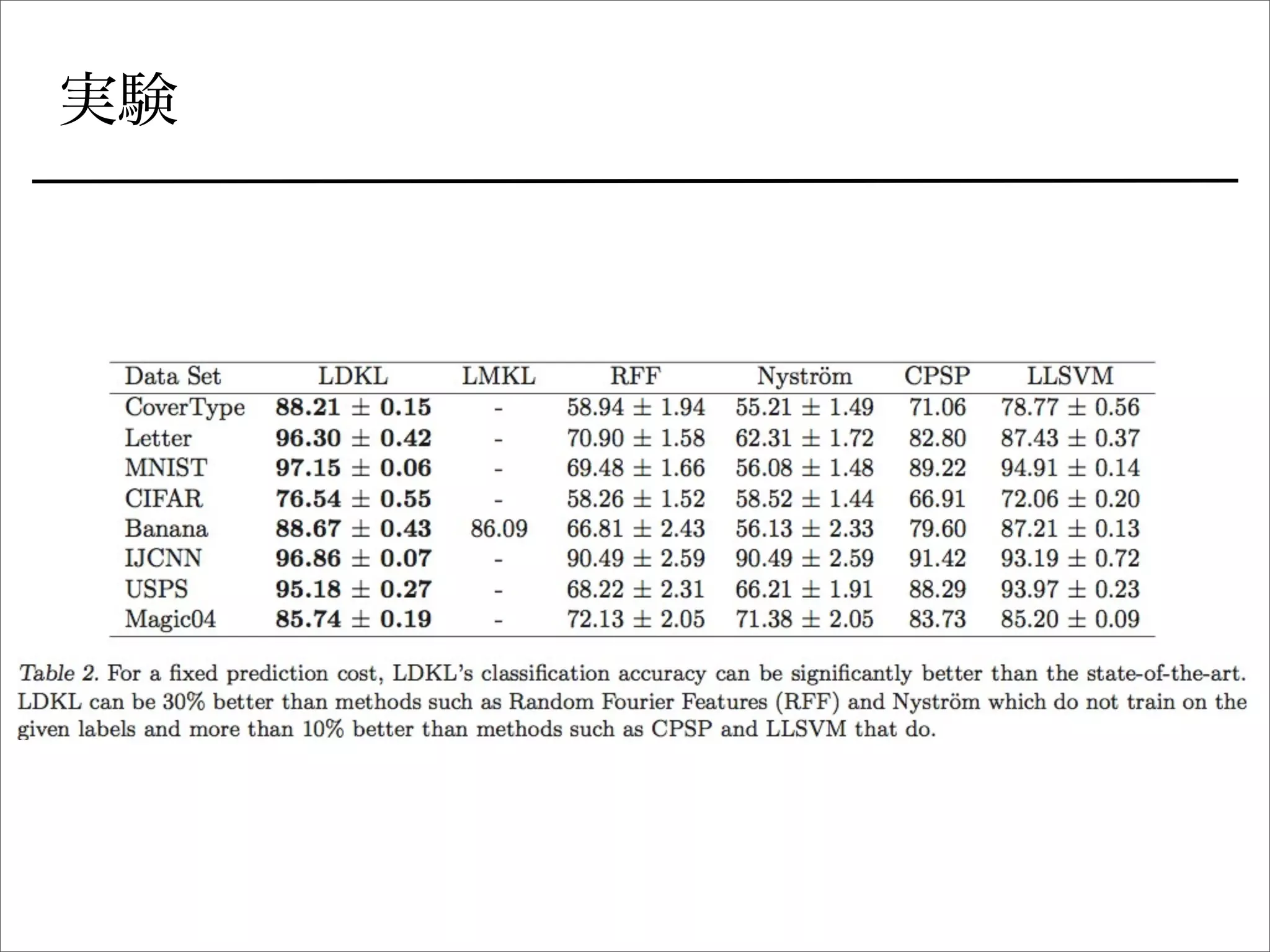
非線形SVMの分類を速くする話は他にもいろいろ
• サポートベクトルを少なくする
• ランダム埋め込み](https://image.slidesharecdn.com/icml2013-tokui-ldkl-130709213603-phpapp01/75/ICML2013-Local-Deep-Kernel-Learning-for-Efficient-Non-linear-SVM-Prediction-3-2048.jpg)
![Locally Linear SVM [Ladicky+, ICML 11]
min
W 2
kW k2
+
1
|S|
X
k2S
⇠k
s.t. 8k 2 S, ⇠k max(0, 1 yk (xk)t
W xk).](https://image.slidesharecdn.com/icml2013-tokui-ldkl-130709213603-phpapp01/75/ICML2013-Local-Deep-Kernel-Learning-for-Efficient-Non-linear-SVM-Prediction-4-2048.jpg)






![その他
• Fastfood [Le+, ICML 13]とは(当然)比較なし
- 乱択埋め込みによるカーネル近似の新しいやつ
- アダマール行列をうまく使う](https://image.slidesharecdn.com/icml2013-tokui-ldkl-130709213603-phpapp01/75/ICML2013-Local-Deep-Kernel-Learning-for-Efficient-Non-linear-SVM-Prediction-24-2048.jpg)

































![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=640&height=640&fit=bounds)





















