
Download to read offline




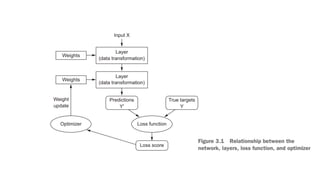
![1) Layers
— A layer is a data-processing module that takes as input one or more tensors and outputs one
or more tensors.
— Different layers are appropriate for different tensor formats and different types of data
processing.
▪ For example, simple vector data, stored in 2D tensors (samples, features)
✓ often processed by densely connected (aka fully connected or dense) layers.
✓ For Example, (samples=1000 houses, features=[size, no. rooms, location]).
▪ Sequence data (text, audio, etc.), stored in 3D tensors (samples, timesteps, features)
✓ typically processed by recurrent layers.
✓ For Example, (samples=500 text documents, timesteps=100 words, features=dimensionality of the
word embeddings (e.g., 300-dimensional word embeddings)).
▪ Image data, stored in 4D tensors (samples, height, width, channels)
✓ usually processed by 2D convolution layers (Conv2D) to extract features.
✓ For Example, (samples=10,000 images, height=28 pixels, width=28 pixels, channel=1).](https://image.slidesharecdn.com/gettingstartedwithneuralnetworks-241124094100-735fdf59/85/Getting-started-with-neural-networks-NNs-5-320.jpg)




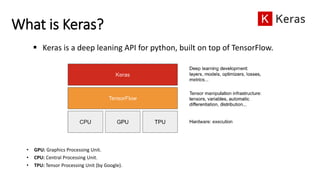







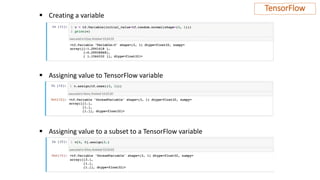




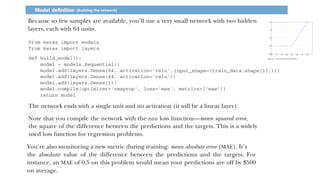
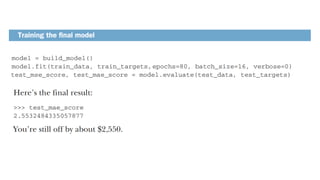
The document provides an overview of neural networks, specifically using Keras and TensorFlow, detailing the anatomy of neural networks, including layers, models, loss functions, and optimizers. It explains the setup for a deep learning workspace, emphasizing the advantages of using GPUs and Jupyter notebooks. Additionally, it outlines introductory steps for using TensorFlow, including tensor manipulation and a regression example using the Boston housing price dataset.
























![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)









































