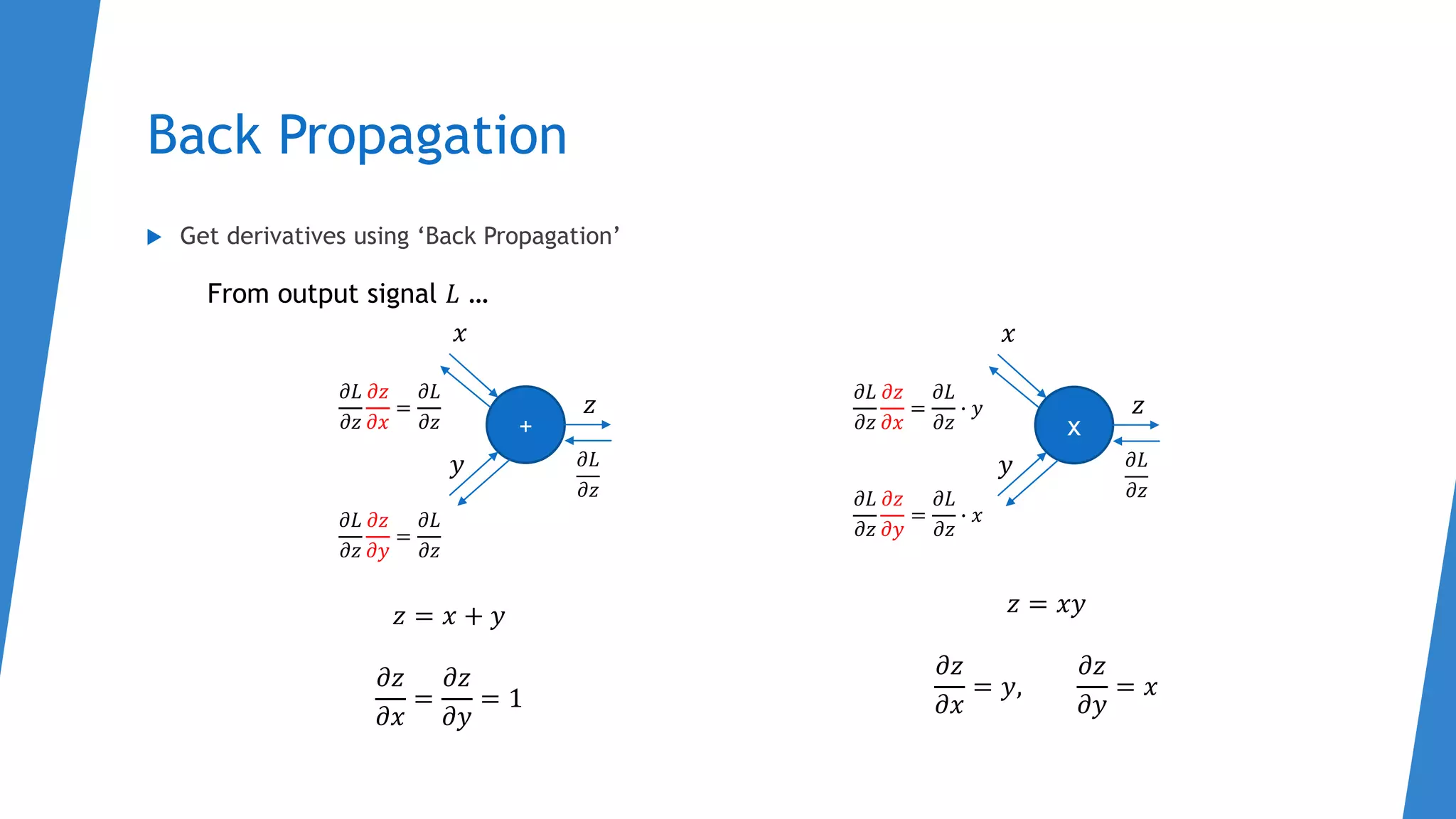
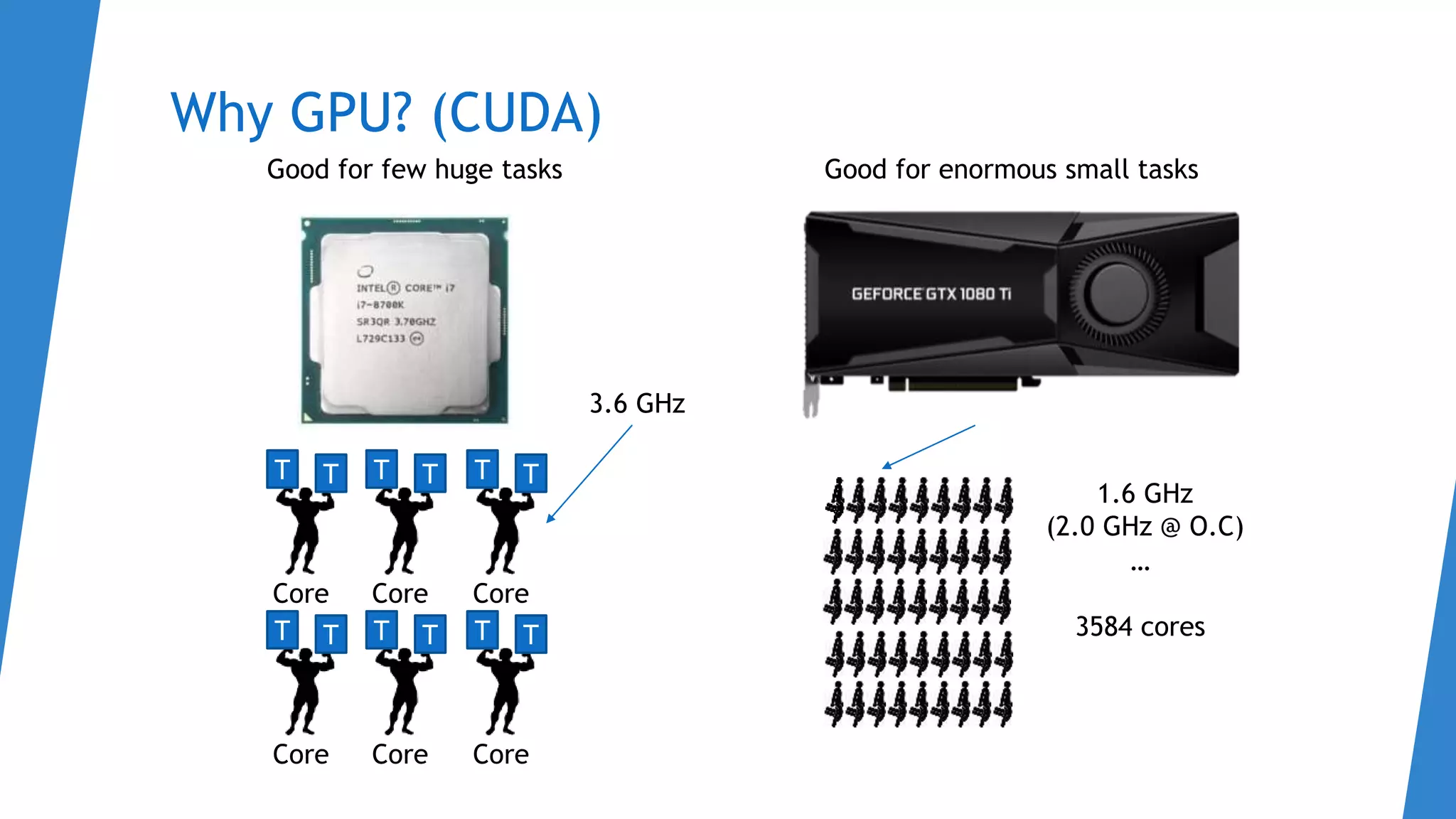
The document discusses an introduction to PyTorch, focusing on topics such as autograd, logistic classifiers, loss functions, backpropagation, and data parallelism, particularly on how to efficiently utilize GPUs. It includes detailed explanations of concepts like chain rule, gradient descent, and practical examples of finding gradients using matrices. Additionally, it highlights the implementation of data parallelism in PyTorch to improve training performance by using multiple GPUs.



































































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)

