Choosing the Right FDO Deployment Model for Your Application _ Geoffrey at In...
L2 flash cards quantitative methods - SS3
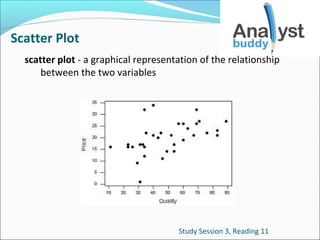
1. Scatter Plot
scatter plot - a graphical representation of the relationship
between the two variables
Study Session 3, Reading 11
2. Correlation and Covariance Analysis
Correlation analysis - expresses the relationship between two
variables with the help of a single number. It measures both
the extent and direction of the linear relationship between
two variables.
Formula: Sample covariance of X and Y for a sample size of ‘n’
can be calculated as:
Study Session 3, Reading 11
3. Correlation and Covariance
Analysis (cont.)
Formula: Sample Correlation Coefficient:
Where: SX - standard deviation of variable X
SY - standard deviation of variable Y
Formula: Sample Standard Deviation
Study Session 3, Reading 11
4. Limitations to Correlation Analysis
Outliners
Outliers are a small number of observations that are at either
extreme of a sample
Spurious Correlation
The correlation between two variables that shows a chance
relationship in a particular data set is called spurious
correlation.
The correlation between two variables that arises not from a
direct relationship between them but their relation to third
variable is also called spurious correlation.
Study Session 3, Reading 11
5. Hypothesis Testing For Population
Correlation Coefficient
Proposed Hypothesis:
null hypothesis - H0 , that the correlation is 0 (p=0)
alternative hypothesis - Ha that the correlation of population
is different from 0 (p≠0)
Formula: t-test
Study Session 3, Reading 11
6. Dependent and Independent
Variables in Linear Regression
independent variable (denoted as X) - the variable that is used
to explain changes
dependent variable (denoted as Y) - the variable that is to be
explained.
Linear regression involves the use of one variable to make a
prediction about other variable. It also involves testing
hypotheses about the relation between the two variables and
quantifying the strength of relationship between the two
variables.
Study Session 3, Reading 11
7. Dependent and Independent
Variables in Linear Regression (cont.)
Regression equation that defines the linear relation between the
dependant and independent variable:
Where: Y - dependent variable
b0 – intercept
b1 - slope coefficient
X - independent variable
- error term
Study Session 3, Reading 11
8. Dependent and Independent
Variables in Linear Regression (cont.)
In linear regression, estimated or fitted parameters b0 and b1 are
chosen in the given equation to minimize:
cross sectional data - uses many observations on the dependant
and independent variables for the same time period
time-series data - many observations from different time
periods are used
Study Session 3, Reading 11
9. Assumptions of a Classical Linear
Regression Model
1. There is a linear relationship between the independent and
2.
3.
4.
5.
6.
dependant variable.
The independent variable is not random.
The expected value of the error term is 0.
The error term is normally distributed.
The error term is uncorrelated across observations.
The variance of the error term is the same for all
observations (Homoskedasticity Assumption).
Study Session 3, Reading 11
10. Standard Error of Estimate
Standard Error of Estimate (also called the standard error of
regression) - used to measure how accurately a regression
model fits the data.
Formula:
Study Session 3, Reading 11
11. Coefficient of Determination
coefficient of determination - used in measuring the proportion
variance in the dependent variable that is explained by the
independent variable
Formula:
Study Session 3, Reading 11
12. Confidence Interval for Regression
Coefficient
regression coefficient - the average change in the dependant variable
for every one unit change in the value of the independent variable.
Things needed to estimate confidence interval for the regression coefficient:
estimated parameter value for a sample
standard error of estimate
Significance level for t-distribution
degree of freedom (n-2).
Formula:
Where: tc - critical t value at a chosen significant level
Study Session 3, Reading 11
13. Hypothesis Testing for a Population
Value of the Regression Coefficient
Formula: When testing a hypothesis using a regression model
with t-test of significance, the t statistic is computed as:
Formula: The confidence interval for the test is given as:
Study Session 3, Reading 11
14. Calculating a Predicted Value for the
Dependent Variable
Two sources of uncertainty in using regression model:
1. the error term
2. estimated parameters ( bˆ0 and bˆ1 )
Given the regression model Yi =bo +b1 Xi +Ei , if estimated
parameters bˆ0 and bˆ1 are known, the predicted value of
dependent variable ,Y, can be calculated as:
Study Session 3, Reading 11
15. Calculating a Predicted Value for the
Dependent Variable (cont.)
The prediction interval for a regression equation for a particular
predicted value of the dependent variable is computed as:
Where: Sf - square root of estimated variance of prediction error
tc - critical level for t-statistic at chosen significance level
The confidence level is taken as
Study Session 3, Reading 11
16. Calculating a Predicted Value for the
Dependent Variable (cont.)
The estimated variance of the prediction error (
calculated as:
of Y) is
Where: S2 - squared standard error of estimate
-variance of independent variable
Study Session 3, Reading 11
17. Calculating ANOVA
in Regression Analysis
Analysis of Variance (ANOVA) - a statistical procedure that is
used to determine how well the independent variable or
variables explain the variation in the dependant variable.
F-test - the statistical test that is used in the analysis of the
variance
Study Session 3, Reading 11
18. F-test
A F-statistic is used to test whether the slope coefficients in a
linear regression are equal to 0 or not.
In a regression equation with one independent variable:
Null Hypothesis H0 : b1= 0
Alternative Hypothesis Ha : b1≠ 0
Things required to undertake an F-test
1. the total number of observations
2. the total number of parameters to be estimated
3. the sum of squared errors(SSE)
4. regression sum of squares (RSS)
Study Session 3, Reading 11
19. F-test (cont.)
Formula: SSE
Formula: RSS
Formula: Total Variation
(TSS) = SSE + RSS
Formula: F-statistic in a regression with one independent variable
Study Session 3, Reading 11
20. Limitations to Regression Analysis
Parameter instability
In investment analysis, regression models can have limited use
because public knowledge of regression relationships can
negate their use for future purpose
Violations of assumptions can make hypothesis tests and
predictions invalid
Study Session 3, Reading 11
21. Multiple Regression Equation
multiple regression equation - used to determine how a dependent
variable is affected by more than one independent variables
log-log regression model - used when the proportional changes in the
dependent variable bear a constant relationship to a proportional
changes in independent variables
General Form of the Multiple Regression Model
Where: Yi - the ith observation of the dependent variable Y
Xji - the ith observation of the independent variable Xj, j=1,2,…,k
b0 - the intercept of the equation
b1 ,…., bk - the slope coefficients for each of the independent variables
Ei - the error term
n - the number of observations Study Session 3, Reading 112
22. Hypothesis Testing for a Population
Value of a Regression Coefficient
Under the null hypothesis, the hypothesis population value of a
regression coefficient is taken as 0.
The degrees of freedom in the test are the number of observations
minus the number of independent variables + 1 (i.e. n – (k+1).)
Formula: Hypothesis testing using t-test:
Where: b^j - regression estimate of hypothesized value of coefficient
-estimated standard error of b^j
Study Session 3, Reading 12
23. Hypothesis Testing for a Population
Value of a Regression Coefficient (cont.)
p-value
The p-value for a regression coefficient is the smallest level of
significance at which the null hypothesis of that population
value of the coefficient is 0 can be rejected in a two-sided test.
The lower the p-level, the more accurate the result of the test.
Study Session 3, Reading 12
24. Confidence Interval for the Population
Value and Predicted Value for the
Dependent Variable
Two types of uncertainty in predicting the dependent variable
using linear regression model:
the regression model itself because of standard error of estimate
uncertainty about estimates of regression model parameters
The computation of the prediction interval to accommodate
the uncertainties is done with the help of matrix algebra.
Study Session 3, Reading 12
25. Points to be considered for predicting
a dependent variable
Assumptions required for using a regression model must be
met.
Caution should be exercised on predictions that are based on
the value of independent variables that are outside the range
of data used for estimating the model.
Study Session 3, Reading 12
26. Steps in predicting the value of the
dependent variable
Obtaining estimates
of regression
parameters (
).
Determining assumed values of independent variables
Computing predicted value of dependent variable
using the equation:
Study Session 3, Reading 12
27. Assumptions of a Multiple
Regression Model
1. There exists a linear relationship between the dependent variable
2.
3.
4.
5.
6.
and the independent variables.
There is no exact linear relationship between two or more of the
independent variables and the independent variables are not
random.
The error term is normally distributed.
The error term is uncorrelated across observations.
The variance of the error term is the same for all of the
observations.
The expected value of error term, conditioned upon the
independent variable, is 0.
Study Session 3, Reading 12
28. F-statistic in Regression Analysis
F-statistic - used to test whether at least one of the slope
coefficients of the independent variables is not equal to 0
null hypothesis - all the slope coefficients in the multiple
regression model are equal to 0 is presented as :
alternative hypothesis - at least one slope coefficient is not
equal to 0.
Study Session 3, Reading 12
29. F-statistic in Regression Analysis (cont.)
Things required for F-test
Total number of observations (n).
Total number of regression coefficients to be estimated (k+1)
where k is number of slope coefficients.
Sum of squared errors (SSE) (Unexplained Variation)
Regression sum of squares (RSS) (Explained Variation)
Study Session 3, Reading 12
30. F-statistic in Regression Analysis (cont.)
Calculating the F-statistic
Degrees of freedom in the test
1) k (numerator degrees of freedom)
2) n-(k+1) (denominator degrees of freedom)
Study Session 3, Reading 12
31. R2 and Adjusted R2
in Multiple Regression
R2 measures how appropriately the regression model fits with one
independent variable.
Adjusted R2 (
) is used in place of R2 when there is more than
independent variable.
Relationship:
Where: n - the number of observations
k - number of independent variables
Study Session 3, Reading 12
32. Dummy Variables
Dummy variables - used in regression models to determine
whether a qualitative independent variable explains the
dependent variable
A dummy variable has a value of 1 if a particular qualitative
condition is true and 0 if that condition is false.
In order to distinguish between n categories, n – 1 dummy
variables are required.
Study Session 3, Reading 12
33. Heteroskedasticity and its Effect on
Statistical Inference
Heteroskedasticity - a violation of the regression assumption
that the variance of the errors in a regression is constant
across observations.
Two types of heteroskedasticity :
1. unconditional heteroskedasticity
2. conditional heteroskedasticity
Breusch-Pagan test - widely used when testing for conditional
heteroskedasticity.
Two methods used for correcting conditional heteroskedasticity:
1. Robust Standard Errors
2. Generalized Least Squares
Study Session 3, Reading 12
34. Heteroskedasticity and its Effect on
Statistical Inference (cont.)
Durbin-Waston test – test conducted when serial correlation
generally arises in time-series regressions
Consequences of Heteroskedasticity
F-test does not provide reliable results.
T-tests for the significance of individual regression coefficients
does not provide reliable results.
Standard errors and test statistics will have to be adjusted in
order to derive reliable results.
Study Session 3, Reading 12
35. Unconditional Heteroskedasticity
and Conditional Heteroskedasticity
Unconditional heteroskedasticity arises when the
heteroskedasticity of an error variance does not correlate with
the independent variables. This heteroskedasticity is not a
major problem for statistical inference.
Conditional heteroskedasticity arises when heteroskedasticity
in the error variance is correlated with the independent
variables. This heteroskedasticity is a major problem for
statistical inference.
Study Session 3, Reading 12
36. Methods for Correcting for
Heteroskedasticity
1. Under the robust standard error method, the standard
errors of a linear regression model’s estimated coefficients
are corrected.
2. Under the generalized least square method, original
equation is modified and a new modified regression
equation is estimated.
Study Session 3, Reading 12
37. Consequences of Serial Correlation
Incorrect estimates of the regression coefficient standard
errors.
If the independent variable is a lagged value of the dependent
variable, it will make the parameter estimates invalid.
In positive serial correlation, a positive (negative) error for
one observation increases the positive (negative) error for
another observation.
Positive serial correlation has no effect on the consistency of
estimated regression coefficients, but affects validity of
statistical tests.
Study Session 3, Reading 12
39. Methods to correct
for Serial Correlation
1. The coefficient standard errors for the linear regression
parameter estimates can be adjusted.
2. Regression equation can be modified to eliminate serial
correlation.
Study Session 3, Reading 12
40. Multicollinearity
in Regression Analysis
Multicollinearity - a violation of the regression assumption that
there is no exact linear relationship between two or more
independent variables
Consequences of Multicollinearity
Estimates of regression coefficients become unreliable.
It is not possible to ascertain how individual independent
variables affect dependent variables.
Study Session 3, Reading 12
41. Model Misspecification
in Regression Analysis
Model specification - the set of variables that are included in the
regression and the regression equation’s functional form
Misspecified Functional Form
It omits one or more important variables from regression.
One or more regression variables are required to be transformed
before estimating the regression.
Data has been pooled from different samples that are not to be
pooled.
Study Session 3, Reading 12
42. Model Misspecification
in Regression Analysis (cont.)
Reasons for time-series misspecification
Inclusion of lagged dependent variables as independent variables in
regressions which have serially correlated errors.
The dependent variable being included as an independent variable.
If there are independent variables that are measured with errors.
Study Session 3, Reading 12
43. Models With Qualitative Dependent
Variables
Qualitative dependent variables are dummy variables that are used as
dependent variables.
1. Probit model - used to estimate the probability of a discrete
outcome when values of independent variables used to explain the
outcomes given based on normal distribution
2. Logic model - used to estimate the probability of a discrete outcome
when values of independent variables used to explain the outcomes
given based on logical distribution
Study Session 3, Reading 12
44. Calculating the Predicted Trend Value
for a Time Series
Linear Trend Models - the dependent variable changes at a
constant rate with time
Formula:
Where: yt - value of the time series at time t
b0 - the y-intercept term
b1 - the slope coefficient (trend coefficient)
t - time (independent variable)
Et - a random error term
Study Session 3, Reading 13
45. Calculating the Predicted Trend Value
for a Time Series (cont.)
Log-Linear Trend Models - used when the time series tends to
grow at a constant rate
Formula:
Predicted trend value of
Study Session 3, Reading 13
46. Limitations of the Use of Trend Models
for a Given Time Series
Trend models can suffer from the limitation of serially
correlated errors.
If trend models have errors that are serially correlated, better
forecast models for such time series are required than trend
models.
Study Session 3, Reading 13
47. Covariance Stationary
Following things should be finite and constant in all periods:
Expected value of time series.
Variance of time series.
Covariance of time series with itself for a fixed number of periods in
the past or future.
Implications if the Time Series is not Covariance Stationary
Estimate of autoregressive time series by using linear regression will
not be valid
The hypothesis test will provide invalid results.
Study Session 3, Reading 13
48. Structure of an Autoregressive
Model of Order p
In an autoregressive model, a time series is regressed on its past
values and shows the relationship between current period-values
and past-period values.
pth-order Autoregressive Model:
First Order Autoregression
Study Session 3, Reading 13
49. Autocorrelation for Time Series
Autocorrelation of a time series - the correlation of the time
series with its past values
Formula:
Study Session 3, Reading 13
50. Autocorrelation for Error Term
Error autocorrelation is estimated by using sample
autocorrelations of the residuals called residual
autocorrelations and their sample variance.
Formula:
Study Session 3, Reading 13
51. Mean Reversion
A time series shows mean reversion if it tends to rise when its level
is below its mean and falls when its level is above its mean.
Formula: Mean Reverting Level
Study Session 3, Reading 13
52. Mean Reversion (cont.)
Interpretation of Mean Reversion Level
If the current value of time series is b0 /(1 – b1 ) , it will neither
increase nor decrease.
If the current value is below b0 /(1 – b1 ) , the time series will
increase.
If the current value is above b0 /(1 – b1 ), the time series will
decrease.
Study Session 3, Reading 13
53. Mean Reversion (cont.)
Multiple Periods of Forecasting and the Chain Rule of Forecasting
Formula: AR Model
Formula: Two-period ahead forecast
Study Session 3, Reading 13
54. In-Sample and Out-of-Sample Forecasts
In-sample forecasts can be defined as the in-sample predicted
values from the estimated time series model.
Out-of-sample forecasts are made from estimated time-series
models for a period that is different from the period from
which the model was estimated.
Root Mean Squared Error (RMSE) (calculated as square root of
average squared error) - used for comparing the out-ofsample forecasting accuracy of different time series models.
Study Session 3, Reading 13
55. Instability of Coefficients
in Time-Series Models
Generally unstable across different sample periods
Different between models that are estimated based on longer
or shorter sample periods
Depends upon the sample period
Study Session 3, Reading 13
56. Random Walk
random walk - a time series model in which the value of a series
in one period is calculated as the value of the series in the
previous period plus an unpredictable random error
Formula:
Random walk with a drift increases or decreases by a constant
amount in each period
Formula:
Study Session 3, Reading 13
57. Random Walk (cont.)
First-differencing - differencing a time series by creating a new
time series that in each period is equal to the difference
between xt and xt-1.
Formula:
Study Session 3, Reading 13
58. Dickey Fuller Unit Root Test
Formula:
Where: g1 = (b1 – 1)
Null Hypothesis is H0 : g1 = 0
Alternative Hypothesis is Ha : g1 < 0
Study Session 3, Reading 13
59. Seasonality in a Time-Series Model
Seasonality of time series occurs when regular patterns of
movement within the year are observed.
Formula: Seasonal lag in autoregressive model
Formula: Forecasted Value
Study Session 3, Reading 13
60. ARCH Models
Autoregressive Conditional Heteroskedasticity (ARCH) - if the
variance of errors in a time series model depends on the
variance of previous
Formula: Linear regression error
Where: u1 = error term
Study Session 3, Reading 13
61. ARCH Models (cont.)
Predicting Variance of Errors
Formula:
Formula: Calculate the variance of the error term in the current period
Study Session 3, Reading 13
62. Analysis of Time-Series Variables
Prior To Linear Regression
Two time series - said to be cointegrated if there is such a longterm financial or economic relationship between the two
variables that they do not diverge from each other without
being bound in the long run.
The (Engle Granger) Dickey Fuller test is used to determine
whether time series are cointegrated.
Study Session 3, Reading 13
63. Analysis of the Appropriate
Time-Series Model Given an
Investment Problem
Regression models or time series models can be used in the
analysis of investment problems.
In a regression model, predicting the future value of a variable
is undertaken on the basis of a hypothesized casual
relationship with other variables.
In time series mode, the future behavior of the variable is
made on the basis of past behavior of that variable.
Study Session 3, Reading 13
64. Explanation of the Dependent Variable
by Analysing the Regression Equation
and ANOVA Table Key
analysis of variance (ANOVA) - used to provide information
about a regression model’s explanatory power
F-statics are used to test the explanatory power of the dependent
variable
If independent variables do not explain the dependent variables, the
value of the F-statistic is 0.
Variability in values of the dependent variable can be divided into
two parts:
Total Sum of Squares = Regression Sum of Squares + Residual Sum of
Squares
Study Session 3, Reading 13
65. Uses of Multiple Regression Analysis
in Financial Analysis
Used in various finance and investment decisions
The effect of various parameters on investment decisions can be
measured
To predict the expected return of a fund or portfolio
Dummy variable can be used in various financial analysis models
If there are any violations of assumptions, they should be
adjusted by analysts before making any decisions
Study Session 3, Reading 13