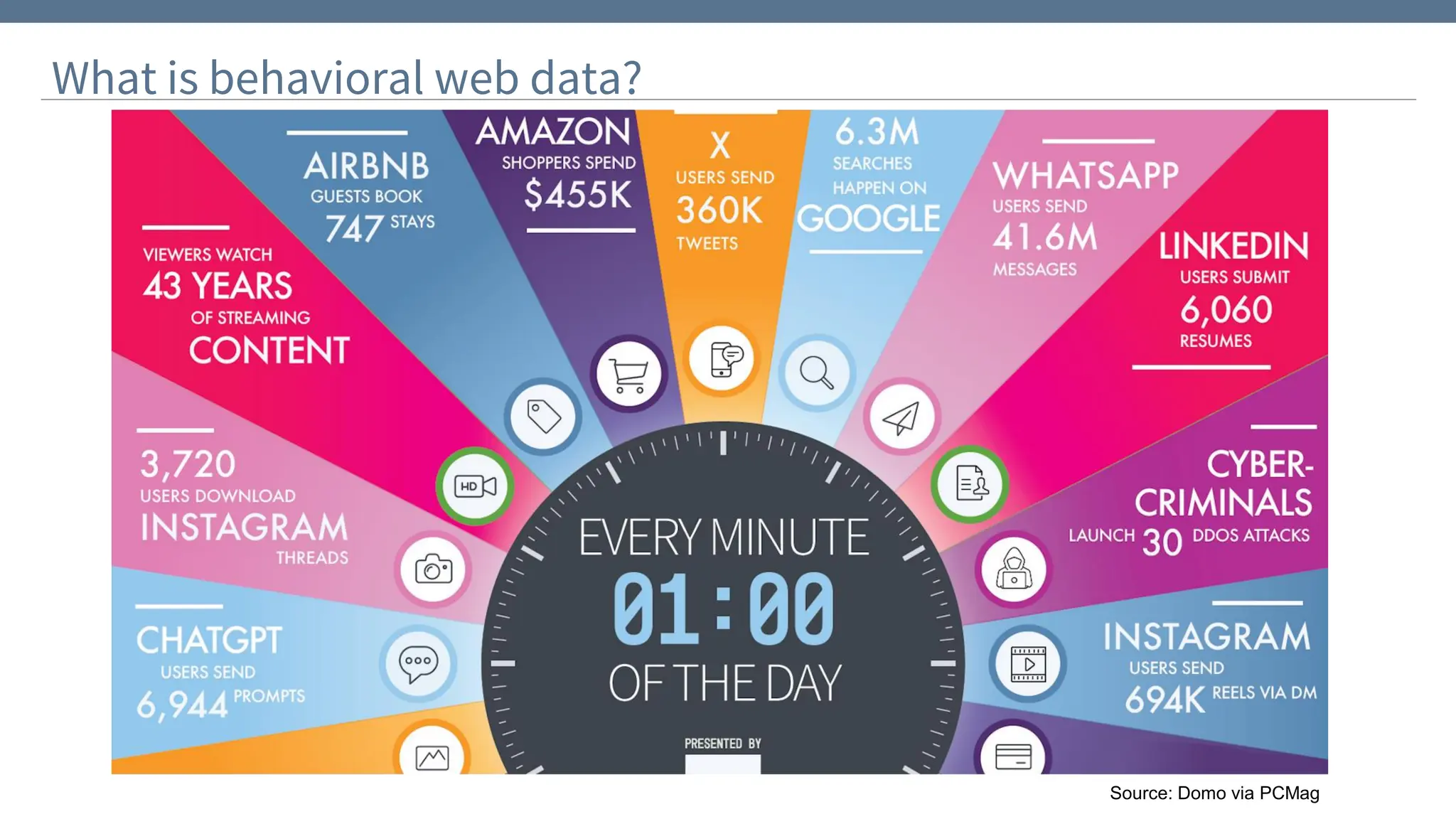
Download to read offline










![22
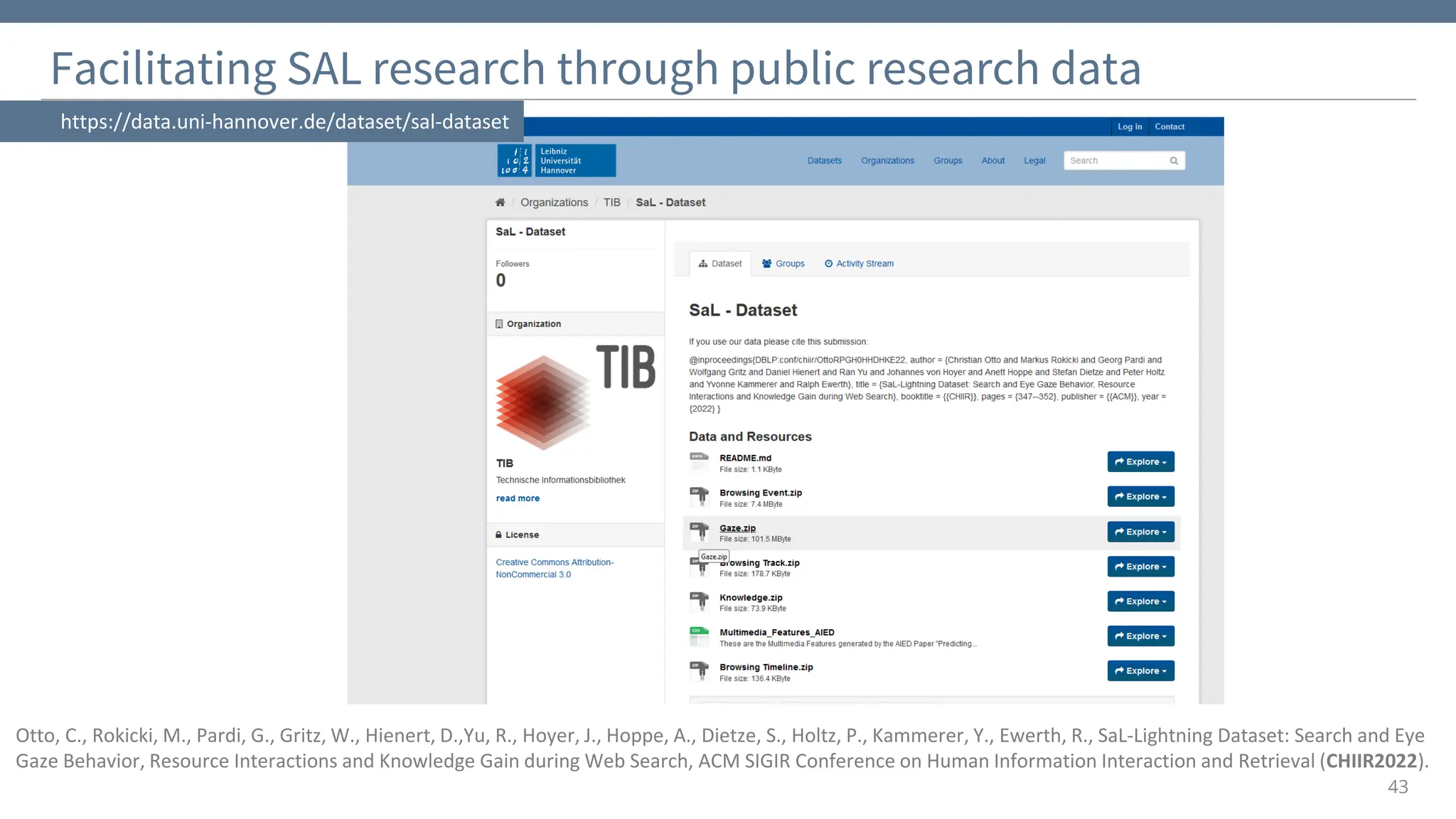
TweetsKB – a non-sensitive large-scale archive of societal discourse
▪ Subset of 3 billion prefiltered tweets
(English, spam detection through pretrained classifier)
▪ Sharing of tweet metadata (time stamps, retweet
counts etc), hash tags, user mentions and dedicated
features that capture tweet semantics
(no actual user IDs and full texts)
▪ Features include [CIKM2020, CIKM2022]:
o Disambiguated mentions of entities, linked to
Wikipedia/Dbpedia
(“president”/“potus”/”trump” => dbp:DonaldTrump)
o Sentiment scores (positive/negative emotions)
o Geotags via pretrained DeepGeo model
o Science references/claims [CIKM2022]
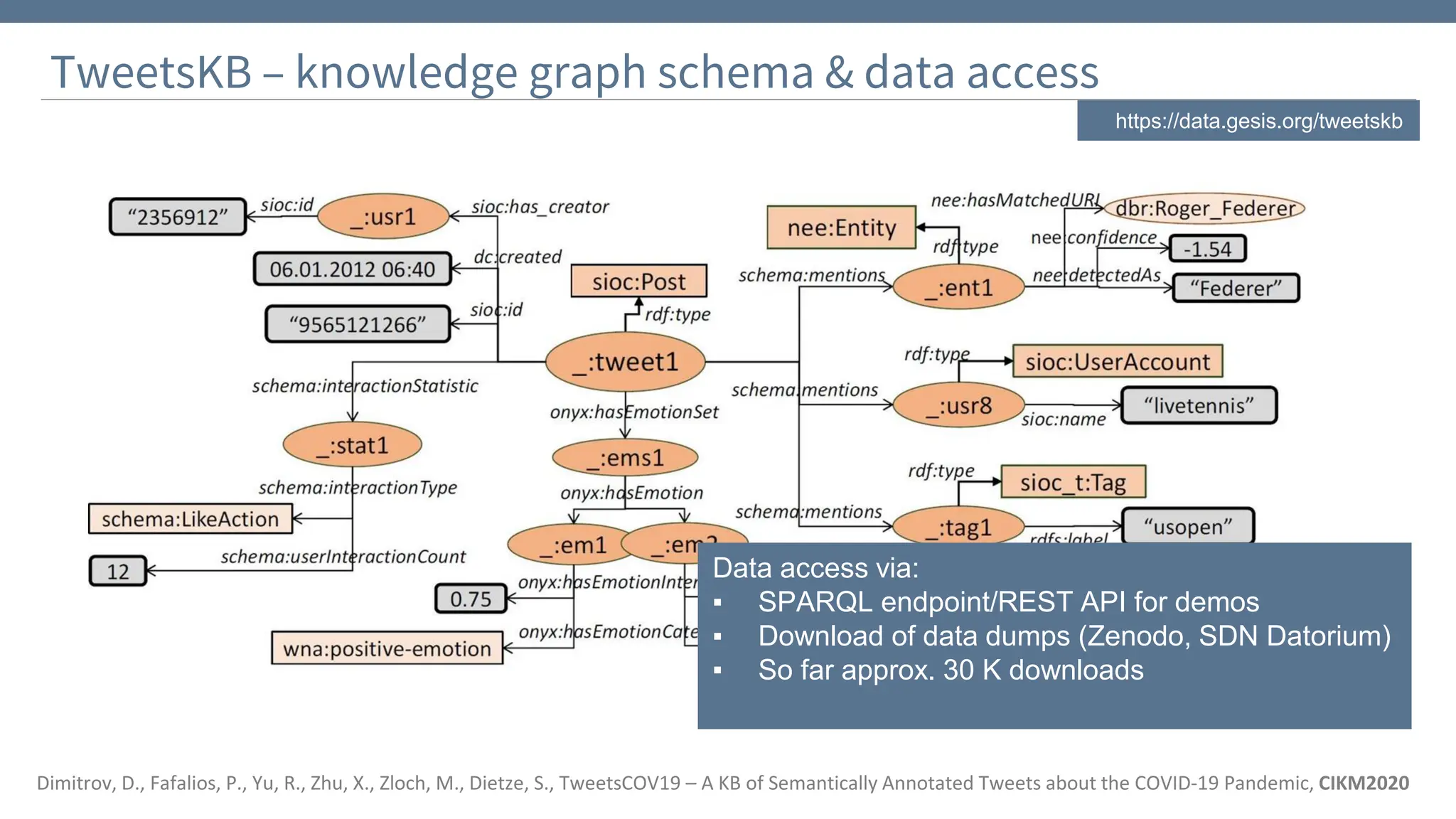
https://data.gesis.org/tweetskb
Feature Total Unique % with >= 1 feature
Hashtags: 1,161,839,471 68,832,205 0.19
Mentions: 1,840,456,543 149,277,474 0.38
Entities: 2,563,433,997 2,265,201 0.56
Sentiment: 1,265,974,641 - 0.5
Dimitrov, D., Fafalios, P., Yu, R., Zhu, X., Zloch, M., Dietze, S., TweetsCOV19 – A KB of Semantically Annotated Tweets about the COVID-19 Pandemic, CIKM2020
Hafid, S., Schellhammer, S., Bringay, S., Todorov, K., Dietze, S., SciTweets - A Dataset and Annotation Framework for Detecting Scientific Online Discourse, CIKM2022](https://image.slidesharecdn.com/tempweb2024-keynote-dietze-240515100243-9c966a39/75/Collecting-Temporal-Analysis-of-Behavioral-Web-Data-Tales-From-The-Inside-19-2048.jpg)

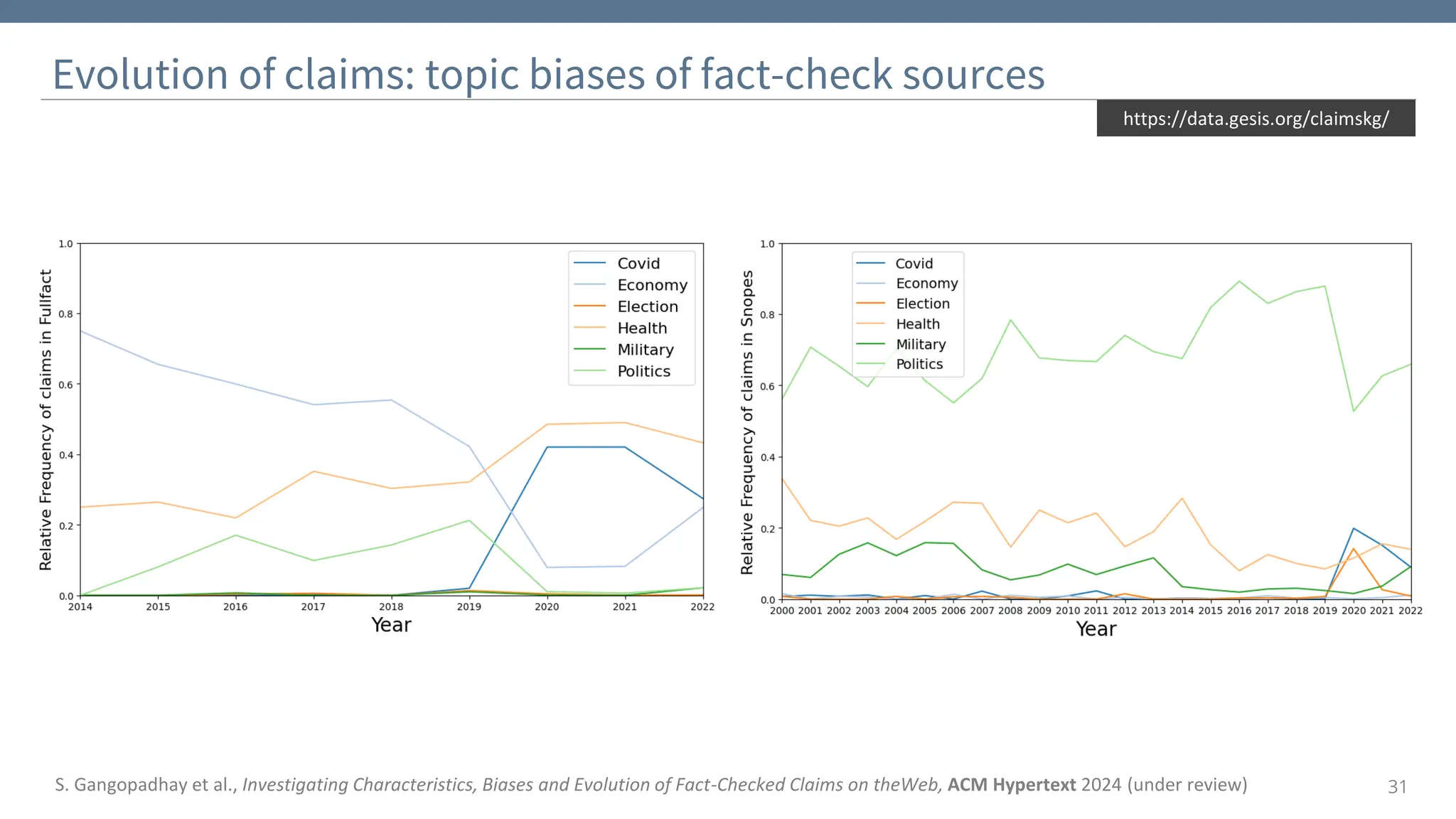



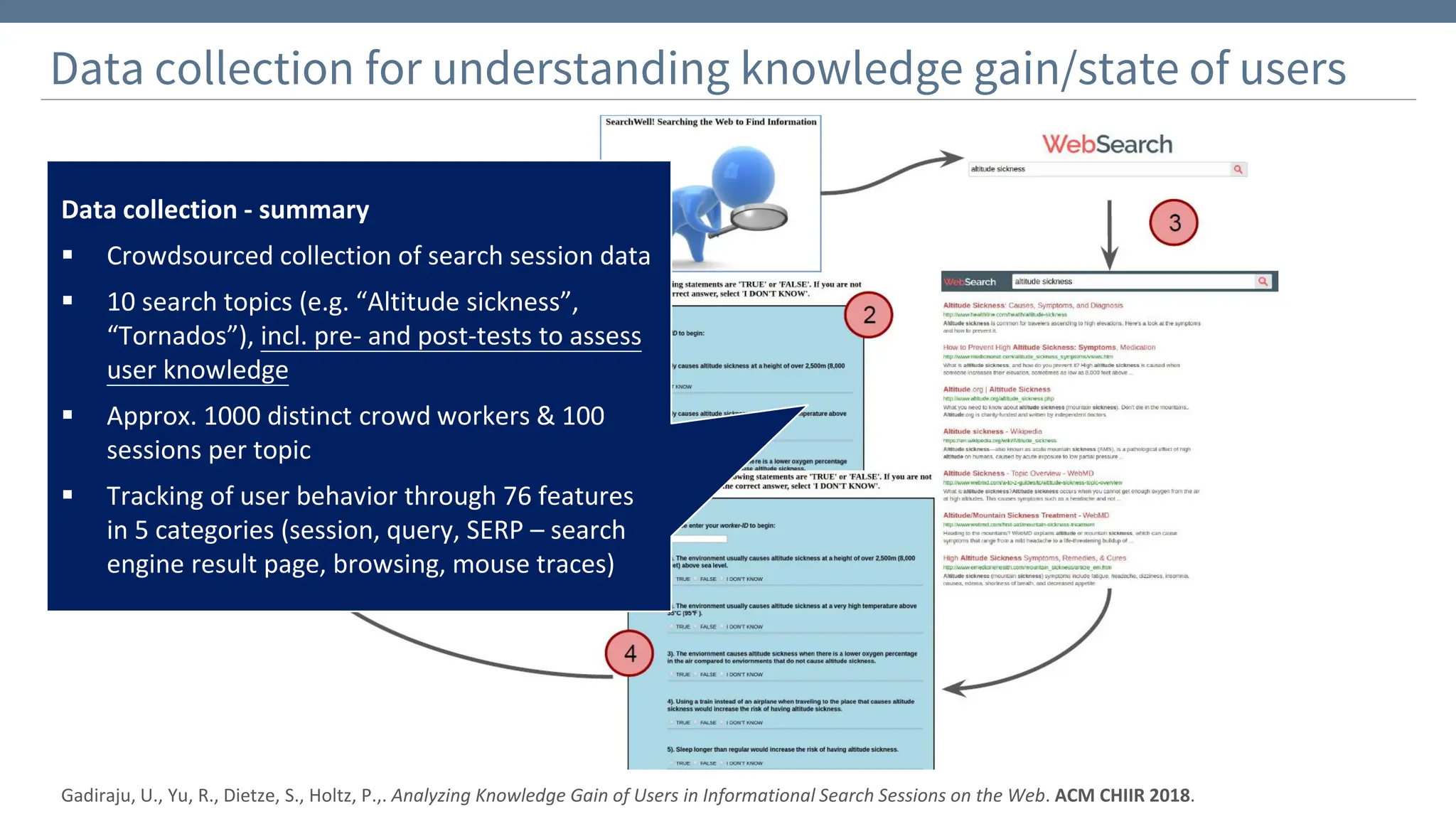
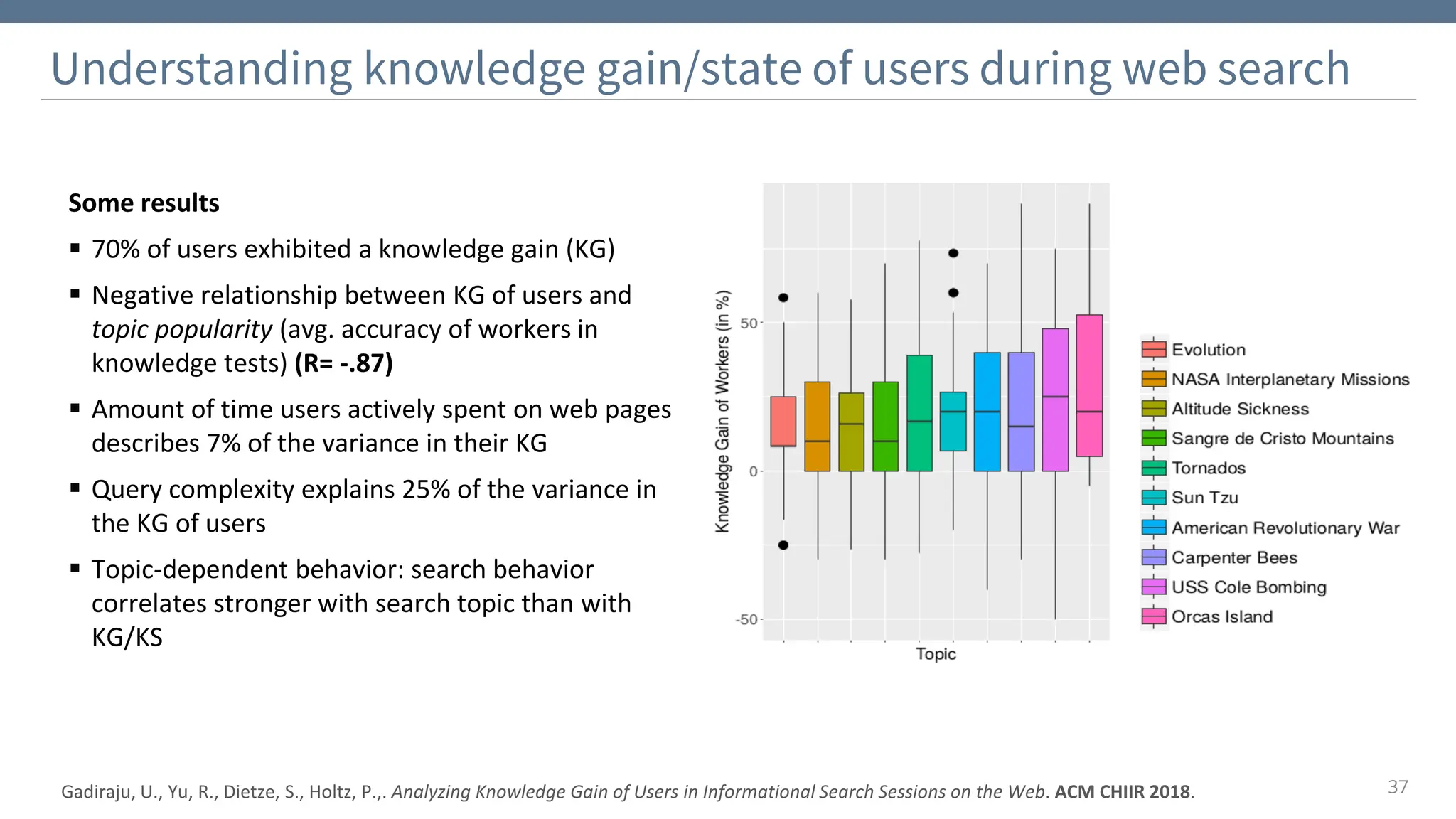
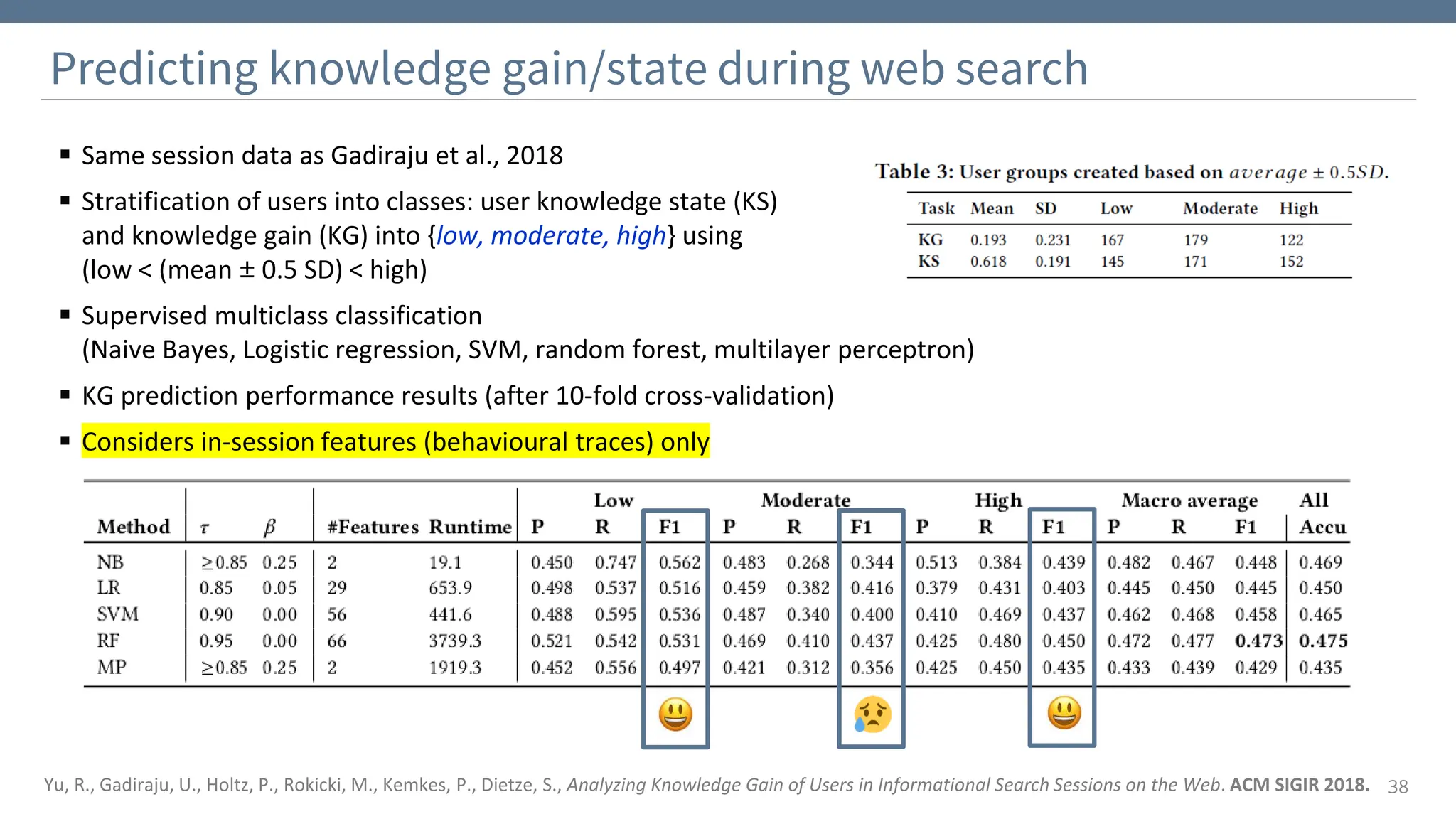
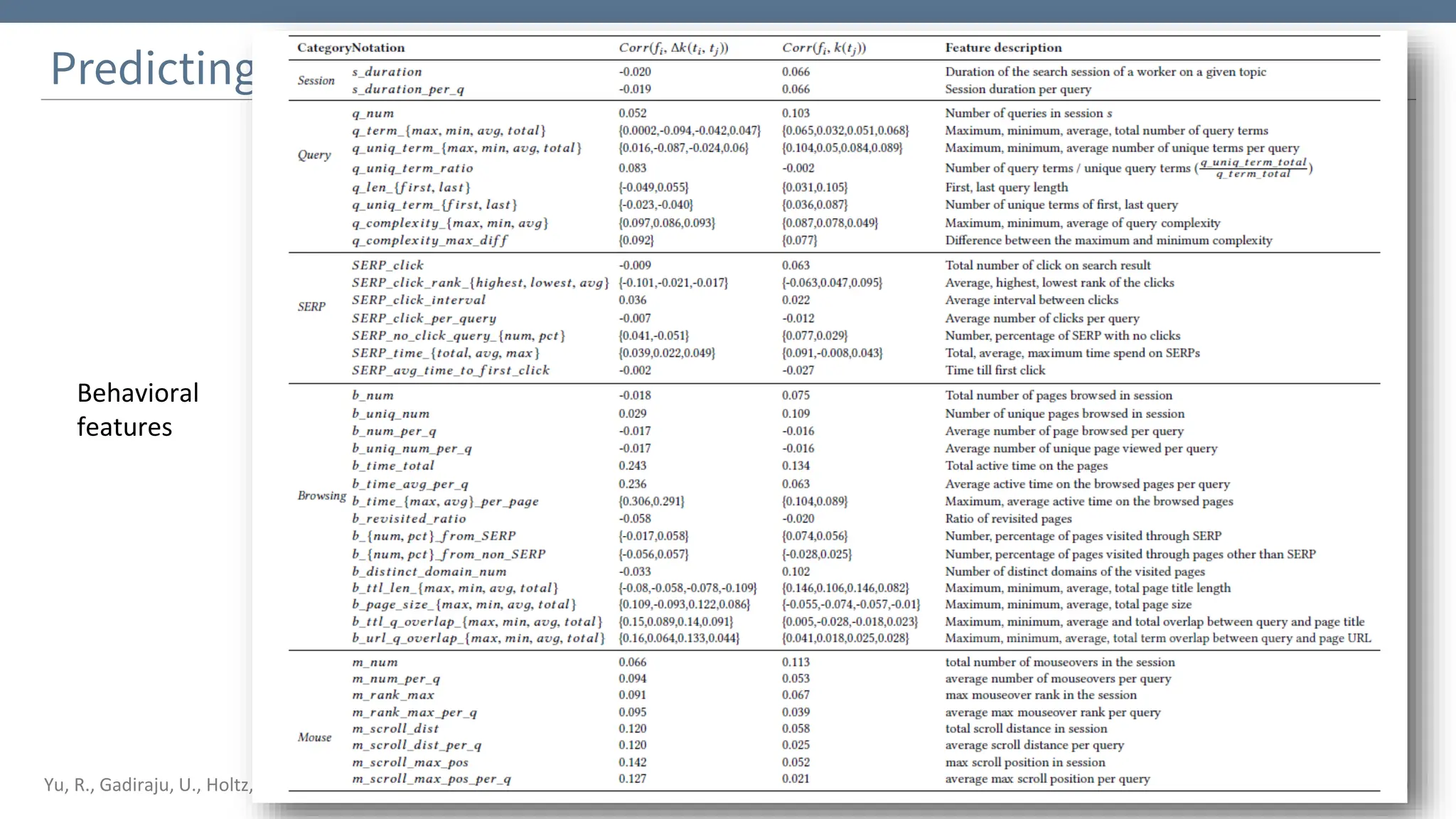
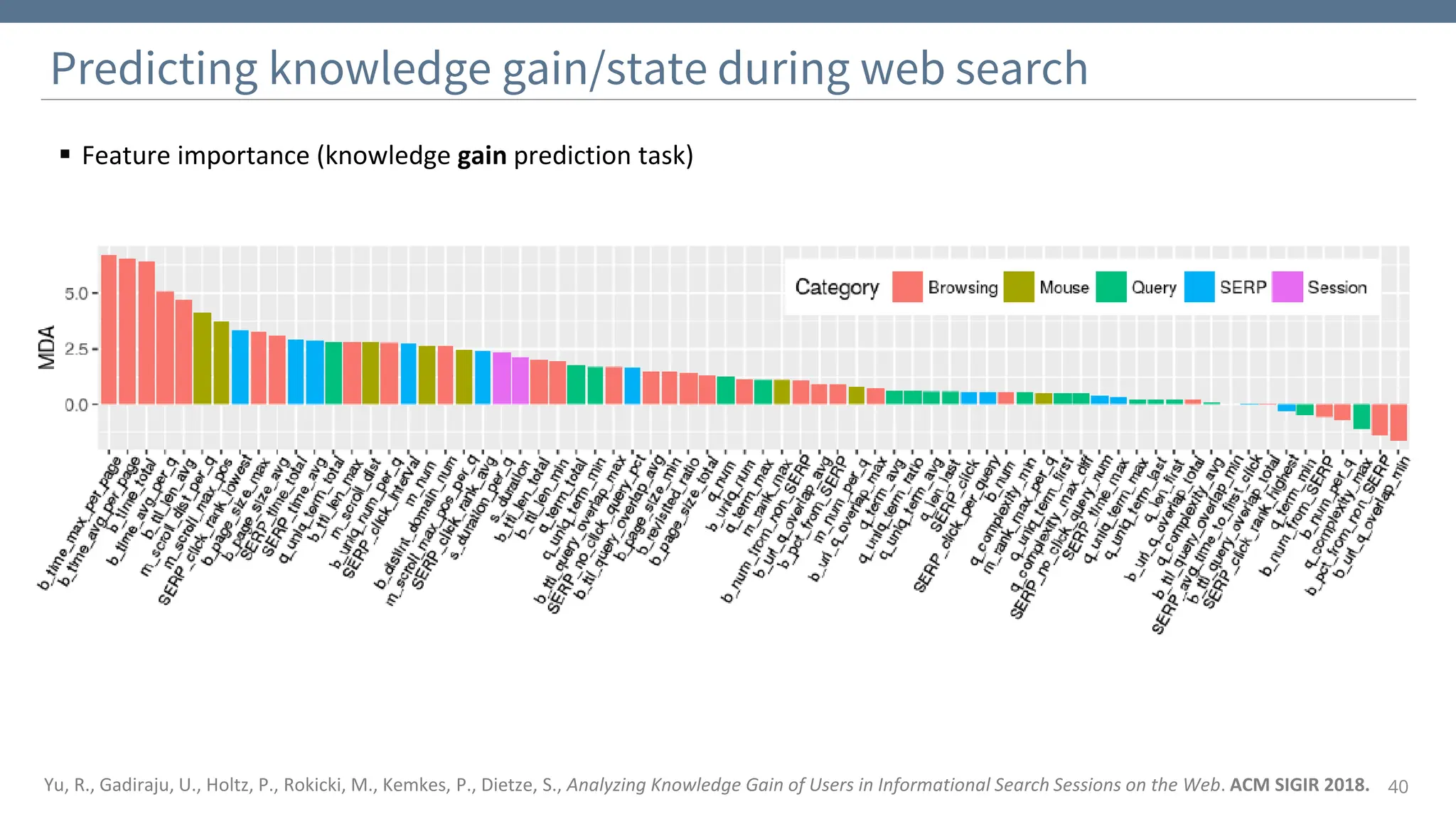
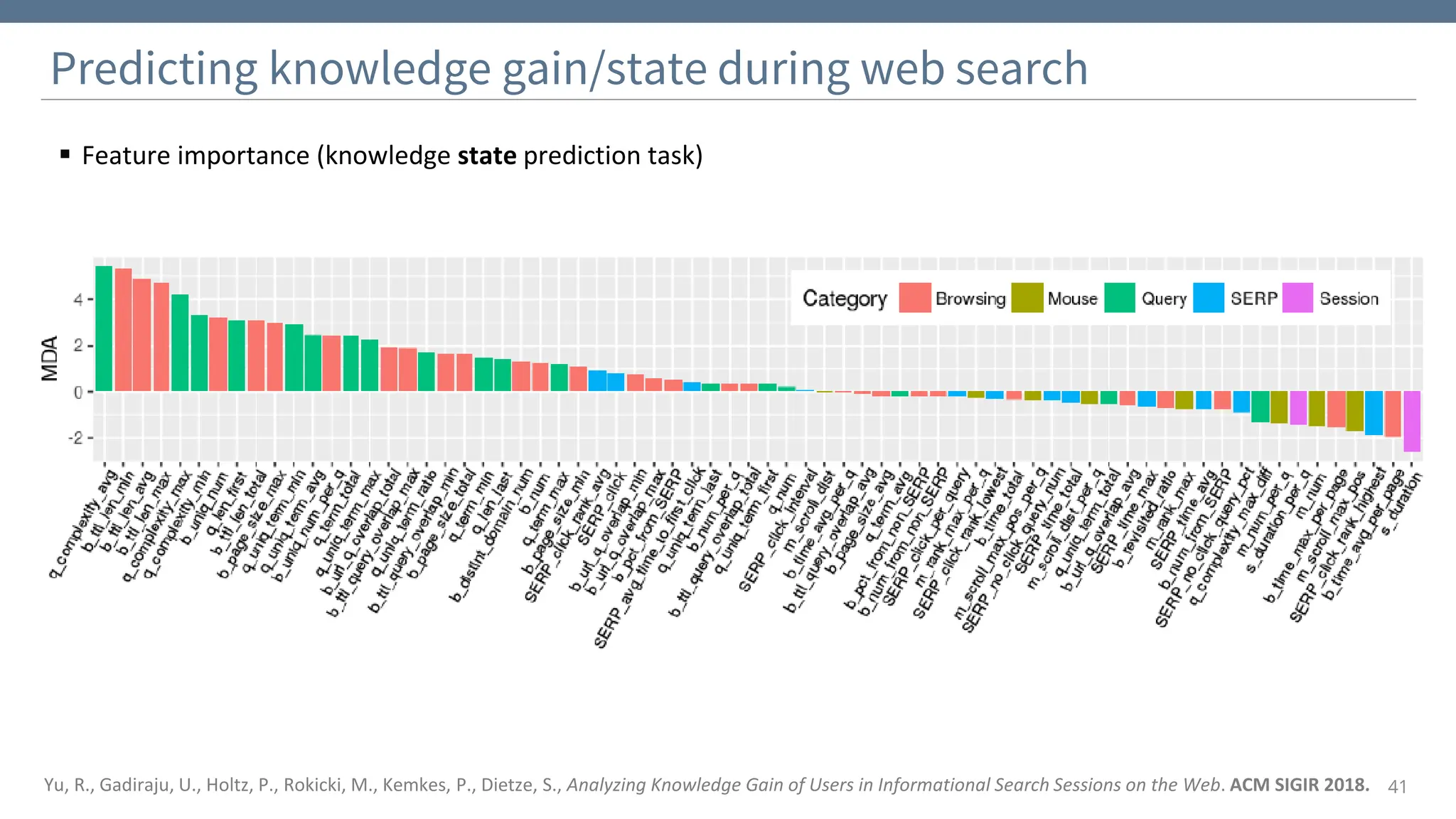

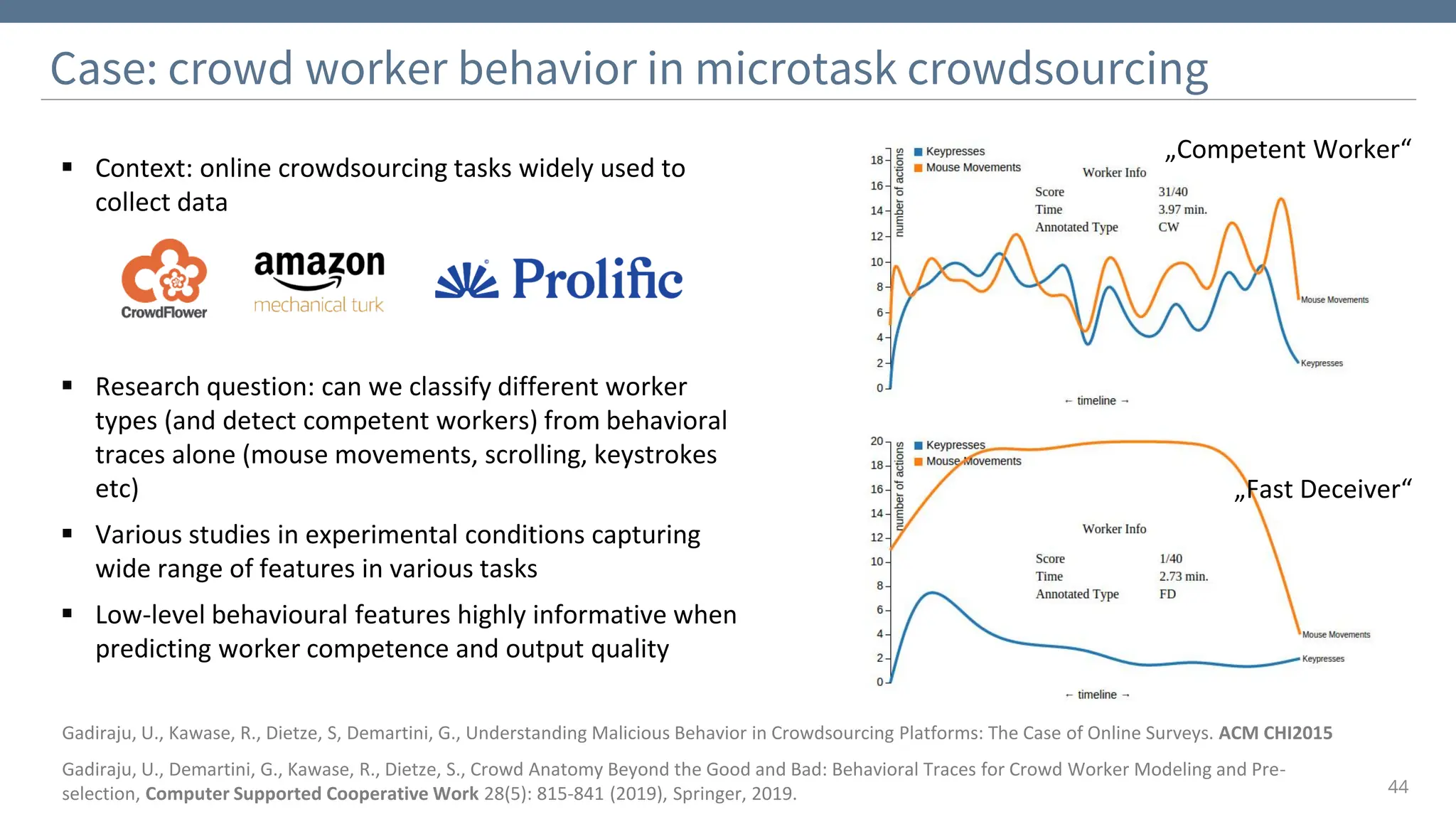
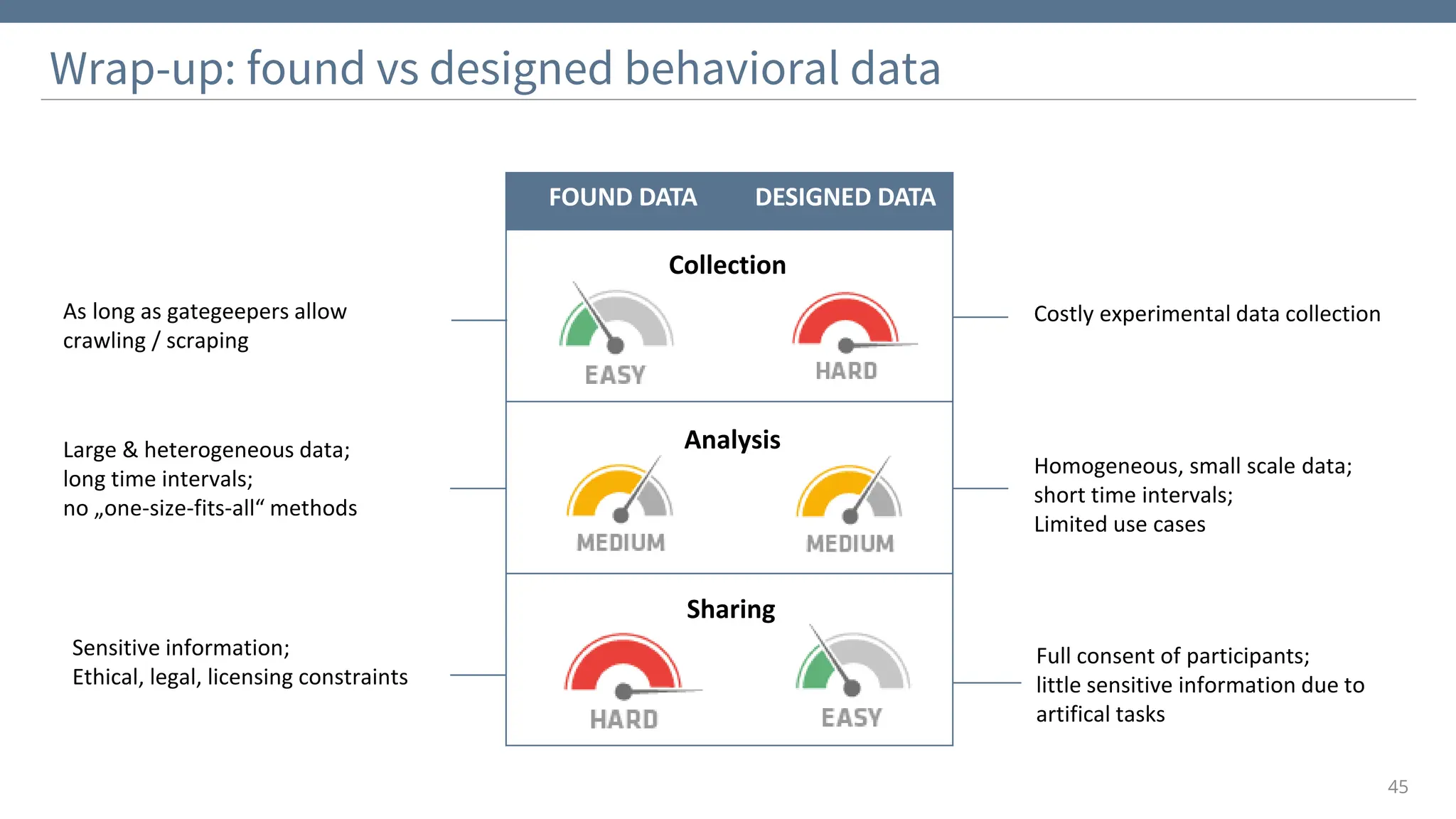




The document discusses the significance and challenges of behavioral web data, which includes social media interactions, browsing behaviors, and more. It highlights the importance of this data for understanding user attitudes and informs various research fields, while also addressing ethical and legal concerns related to its collection and use. Furthermore, the document outlines methods and case studies from existing research efforts to collect and analyze this data, emphasizing the need for real-time collection and responsible sharing practices.


























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








