





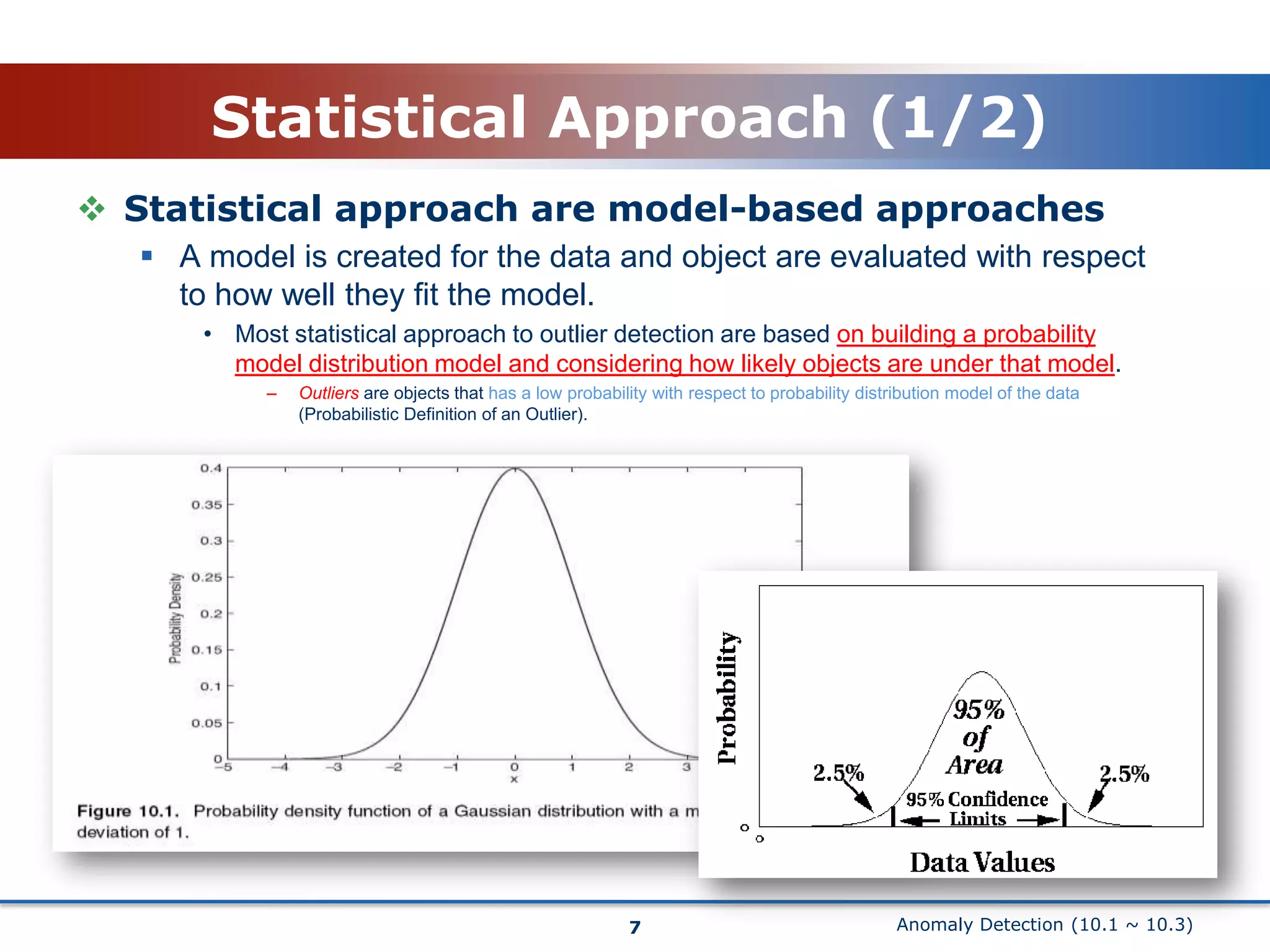







This document discusses anomaly detection techniques. It begins with an introduction that defines anomaly detection as finding objects that are different from most other objects in a dataset. Common applications are discussed such as fraud detection. Two main approaches are then described: statistical approaches that build a probabilistic model of the data and proximity-based approaches that measure how distant objects are from their neighbors. The statistical approach section explains how outliers are objects with a low probability based on the dataset's model. The proximity-based section defines outliers as objects distant from most other points and discusses measuring distance to the k-nearest neighbors.



































































