


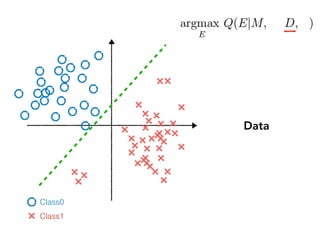




![Agenda
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]
1. Revisiting existing methods:
Saliency maps
2. Making explanations using the way humans think:
Testing with concept activation vectors (TCAV)
Post-training explanations](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-14-320.jpg)

![One of the most popular interpretability methods for images:
Saliency maps
!16
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
Integrated gradient [Sundararajan, Taly, Yan ’17]
picture credit: @sayres
Caaaaan do! We’ve got
saliency maps to measure
importance of each pixel!
a logit
pixel i,j](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-16-320.jpg)
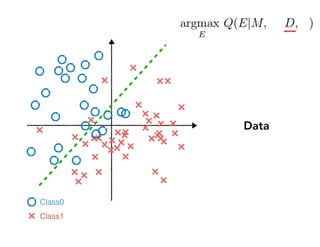
![One of the most popular interpretability methods for images:
Saliency maps
!17
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
Integrated gradient [Sundararajan, Taly, Yan ’17]
widely used
for images
local
undestandingNN
humans’
subjective
judgement
picture credit: @sayres](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-17-320.jpg)
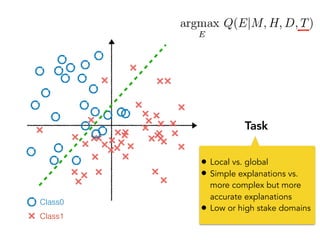
![One of the most popular interpretability methods for images:
Saliency maps
!18
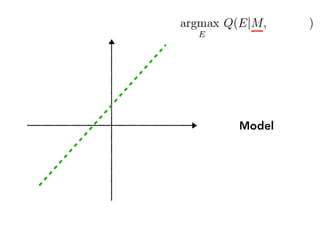
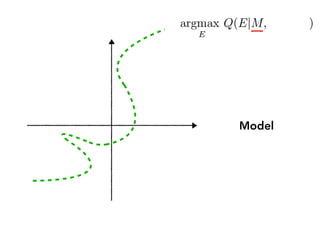
Sanity check:
If I change M a lot, will human
perceive that E has changed a lot?
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
Integrated gradient [Sundararajan, Taly, Yan ’17]
widely used
for images
local
undestandingNN
humans’
subjective
judgement
picture credit: @sayres](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-18-320.jpg)
![Some confusing behaviors of saliency maps.
Saliency map
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-19-320.jpg)
![Some confusing behaviors of saliency maps.
Randomized weights!
Network now makes garbage prediction.
Saliency map
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-20-320.jpg)
![Some confusing behaviors of saliency maps.
Saliency map
Randomized weights!
Network now makes garbage prediction.
!!!!!???!?
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-21-320.jpg)
![Some saliency maps look similar
when we randomize the network
(= making the network completely useless)
Before After
Guided
Backprop
Integrated
Gradient
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-22-320.jpg)
![• Potential human confirmation bias: Just because it
“makes sense” to humans, doesn’t mean they reflect
evidence for the prediction.
• Our discovery is consistent with other findings.
[Nie, Zhang, Patel ’18] [Ulyanov, Vedaldi, Lempitsky ’18]
• Some of these methods have been shown to be useful for
humans. Why? More studies needed.
What can we learn from this?
Sanity Checks for Saliency Maps
Joint work with Adebayo, Gilmer, Goodfellow, Hardt, [NIPS 18]](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-23-320.jpg)
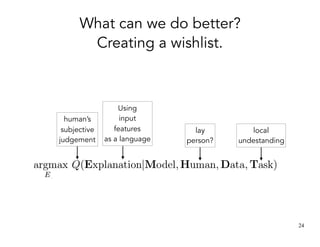

![Agenda
TCAV [ICML’18]
Joint work with Wattenberg, Gilmer, Cai, Wexler, Viegas, Sayres
1. Revisiting existing methods:
Saliency maps
2. Making explanations using the way humans think:
Testing with concept activation vectors (TCAV)
Post-training explanations](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-26-320.jpg)
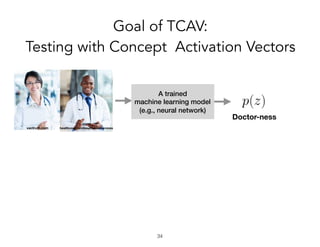
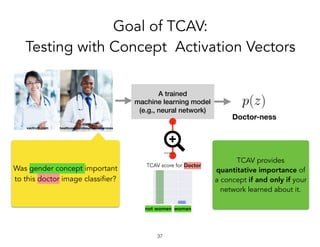
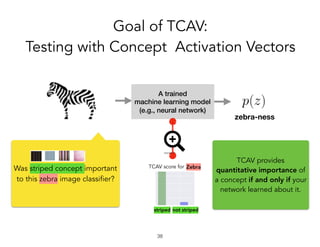
![Problem:
Post-training explanation
!27
cash-machine-ness
A trained
machine learning model
(e.g., neural network)
Why was this a
cash machine?
TCAV [ICML’18]
Joint work with Wattenberg, Gilmer, Cai, Wexler, Viegas, Sayres](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-27-320.jpg)
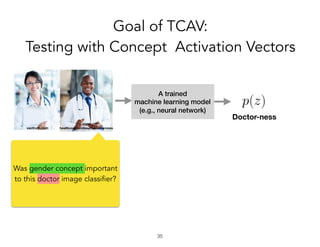
![prediction:
Cash machine
https://pair-code.github.io/saliency/
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
Common solution: Saliency map
!28
Let’s use this to help us
think about what what we
really want to ask.](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-28-320.jpg)
![prediction:
Cash machine
https://pair-code.github.io/saliency/
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
What we really want to ask…
!29
Were there more pixels on the cash
machine than on the person?
Did the ‘human’ concept matter?
Did the ‘wheels’ concept matter?](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-29-320.jpg)
![prediction:
Cash machine
https://pair-code.github.io/saliency/
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
What we really want to ask…
!30
Were there more pixels on the cash
machine than on the person?
Which concept mattered more?
Is this true for all other cash
machine predictions?
Did the ‘human’ concept matter?
Did the ‘wheels’ concept matter?](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-30-320.jpg)
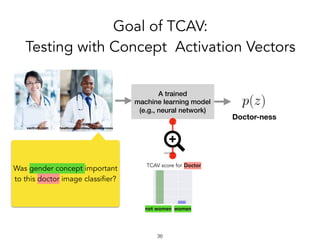
![prediction:
Cash machine
https://pair-code.github.io/saliency/
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
What we really want to ask…
!31
Oh no! I can’t express these concepts
as pixels!!
They weren’t my input features either!
Were there more pixels on the cash
machine than on the person?
Which concept mattered more?
Is this true for all other cash
machine predictions?
Did the ‘human’ concept matter?
Did the ‘wheels’ concept matter?](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-31-320.jpg)
![prediction:
Cash machine
https://pair-code.github.io/saliency/
SmoothGrad [Smilkov, Thorat, K., Viégas, Wattenberg ’17]
What we really want to ask…
!32
Were there more pixels on the cash
machine than on the person?
Which concept mattered more?
Is this true for all other cash
machine predictions?
Wouldn’t it be great if we can
quantitatively measure how
important any of these
user-chosen concepts are?
Did the ‘human’ concept matter?
Did the ‘wheels’ concept matter?](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-32-320.jpg)
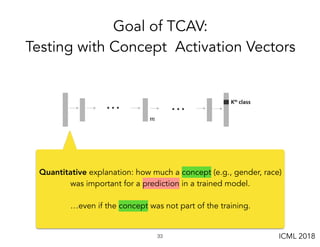
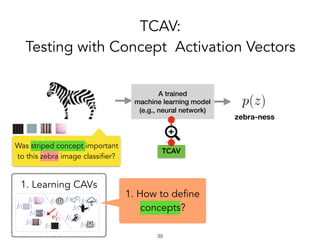
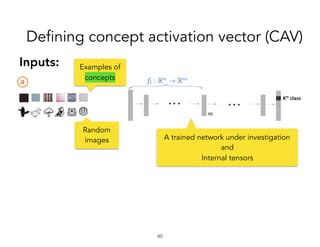
![!41
Inputs:
Train a linear classifier to
separate activations.
CAV ( ) is the vector
orthogonal to the decision
boundary.
[Smilkov ’17, Bolukbasi ’16 , Schmidt ’15]
Defining concept activation vector (CAV)](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-41-320.jpg)









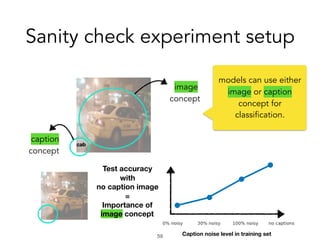
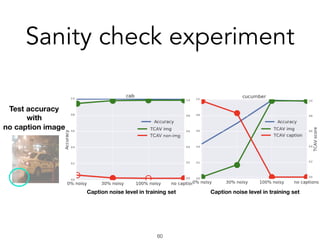



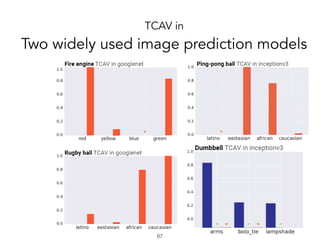
![TCAV in
Two widely used image prediction models
!69
Quantitative
confirmation to
previously
qualitative
findings
[Stock & Cisse,
2017]
Geographical
bias?](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-69-320.jpg)
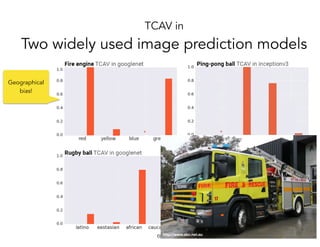
![TCAV in
Two widely used image prediction models
!70
Quantitative
confirmation to
previously
qualitative
findings
[Stock & Cisse,
2017]
Geographical
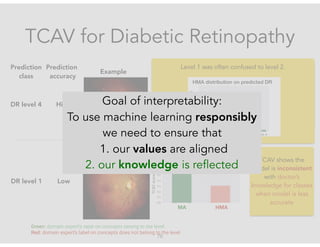
bias?
Goal of interpretability:
To use machine learning responsibly
we need to ensure that
1. our values are aligned
2. our knowledge is reflected](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-70-320.jpg)

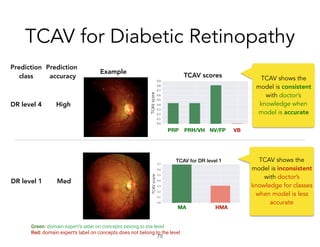
![Diabetic Retinopathy
• Treatable but sight-threatening conditions
• Have model to with accurate prediction of DR (85%)
[Krause et al., 2017]
!72
Concepts the ML model uses
Vs
Diagnostic Concepts human doctors use](https://image.slidesharecdn.com/interpretabilitybeyondfeatureattribution-quantitativetestingwithconceptactivationvectorstcav-181114162904/85/Interpretability-beyond-feature-attribution-quantitative-testing-with-concept-activation-vectors-tcav-72-320.jpg)

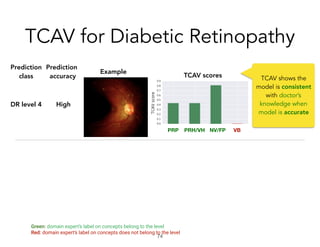
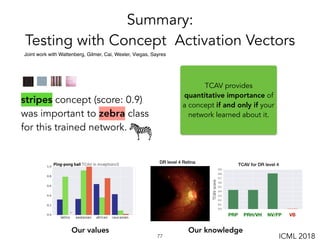

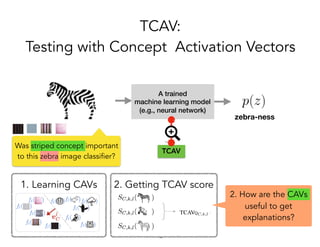
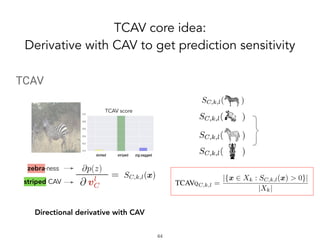
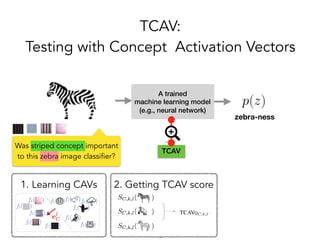
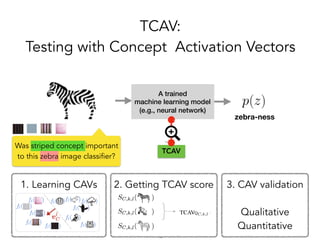
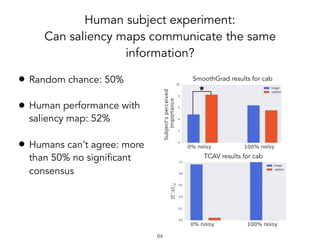
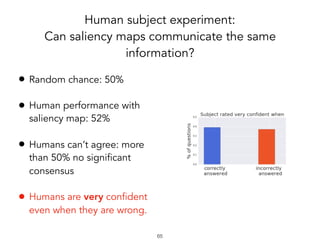
TCAV is a method for interpreting machine learning models by quantitatively measuring the importance of user-chosen concepts for a model's predictions, even if those concepts were not part of the model's training data or input features. It does this by learning concept activation vectors (CAVs) that represent concepts and using the CAVs to calculate a model's sensitivity or importance to each concept via directional derivatives. TCAV was shown to validate ground truths from sanity check experiments, uncover geographical biases in widely used models, and match domain expert concepts for diabetic retinopathy versus those a model may use, helping ensure models' values and knowledge are properly aligned and reflected.
![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)


























































