Downloaded 2,481 times









![GBDT Hyper Parameter Tuning
Hyper Parameter Tuning Approach Range Note
# of Trees Fixed value 100-1000 Depending on datasize
Learning Rate Fixed => Fine Tune [2 - 10] / # of Trees Depending on # trees
Row Sampling Grid Search [.5, .75, 1.0]
Column Sampling Grid Search [.4, .6, .8, 1.0]
Min Leaf Weight Fixed => Fine Tune 3/(% of rare events) Rule of thumb
Max Tree Depth Grid Search [4, 6, 8, 10]
Min Split Gain Fixed 0 Keep it 0
Best GBDT implementation today: https://github.com/tqchen/xgboost
by Tianqi Chen (U of Washington)](https://image.slidesharecdn.com/datasciencecompetitionsv4-150716141308-lva1-app6892/85/Tips-for-data-science-competitions-14-320.jpg)

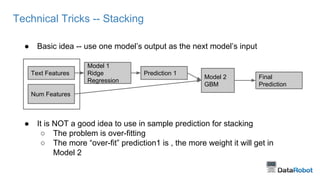









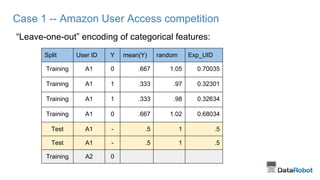




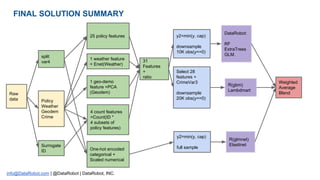


This document provides tips for winning data science competitions by summarizing a presentation about strategies and techniques. It discusses the structure of competitions, sources of competitive advantage like feature engineering and the right tools, and validation approaches. It also summarizes three case studies where the speaker applied these lessons, including encoding categorical variables and building diverse blended models. The key lessons are to focus on proper validation, leverage domain knowledge through features, and apply what is learned to real-world problems.












![[DL輪読会]Factorized Variational Autoencoders for Modeling Audience Reactions to...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180112-180115090630-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















































