Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
1,146 views
【DL輪読会】Reward Design with Language Models
2023/4/21 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 14 times
1
/ 16
2
/ 16
3
/ 16
4
/ 16
5
/ 16
6
/ 16
7
/ 16
8
/ 16
9
/ 16
10
/ 16
11
/ 16
12
/ 16
13
/ 16
14
/ 16
15
/ 16
16
/ 16
More Related Content
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
【DL輪読会】StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-I...
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
Transformer メタサーベイ
by
cvpaper. challenge
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
【DL輪読会】StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-I...
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
What's hot
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
HiPPO/S4解説
by
Morpho, Inc.
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PDF
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
PDF
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PPTX
Triplet Loss 徹底解説
by
tancoro
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
Semantic segmentation
by
Takuya Minagawa
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
HiPPO/S4解説
by
Morpho, Inc.
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
Triplet Loss 徹底解説
by
tancoro
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
GAN(と強化学習との関係)
by
Masahiro Suzuki
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
Semantic segmentation
by
Takuya Minagawa
Similar to 【DL輪読会】Reward Design with Language Models
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
【DL輪読会】Is Conditional Generative Modeling All You Need For Decision-Making?
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PDF
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
Inverse Reward Design の紹介
by
Chihiro Kusunoki
PPTX
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
PPTX
1017 論文紹介第四回
by
Kohei Wakamatsu
PPTX
【輪読会】Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineeri...
by
Deep Learning JP
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PPTX
全脳関西編(松尾)
by
Yutaka Matsuo
PDF
Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning
by
TomoyasuOkada
PPTX
[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...
by
Kazutoshi Shinoda
PDF
Reliability and learnability of human bandit feedback for sequence to-seque...
by
ryoma yoshimura
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
強化学習における好奇心
by
Shota Imai
【DL輪読会】Is Conditional Generative Modeling All You Need For Decision-Making?
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
報酬設計と逆強化学習
by
Yusuke Nakata
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
Inverse Reward Design の紹介
by
Chihiro Kusunoki
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
1017 論文紹介第四回
by
Kohei Wakamatsu
【輪読会】Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineeri...
by
Deep Learning JP
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
全脳関西編(松尾)
by
Yutaka Matsuo
Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning
by
TomoyasuOkada
[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...
by
Kazutoshi Shinoda
Reliability and learnability of human bandit feedback for sequence to-seque...
by
ryoma yoshimura
More from Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
Recently uploaded
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PDF
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
PDF
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PDF
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PPTX
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PDF
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
PPTX
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
PDF
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
PDF
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
【DL輪読会】Reward Design with Language Models
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ DL輪読会:Reward Design with Language Models Ryoichi Takase
2.
書誌情報 2 ※注釈無しの図は本論文から抜粋 採録:ICLR2023 概要: 大規模言語モデルを報酬関数として使用する強化学習フレームワークを提案 ユーザの意図をプロンプトに入力して報酬関数を設計することで、意図に沿って振る舞う方策の学 習を可能とした
3.
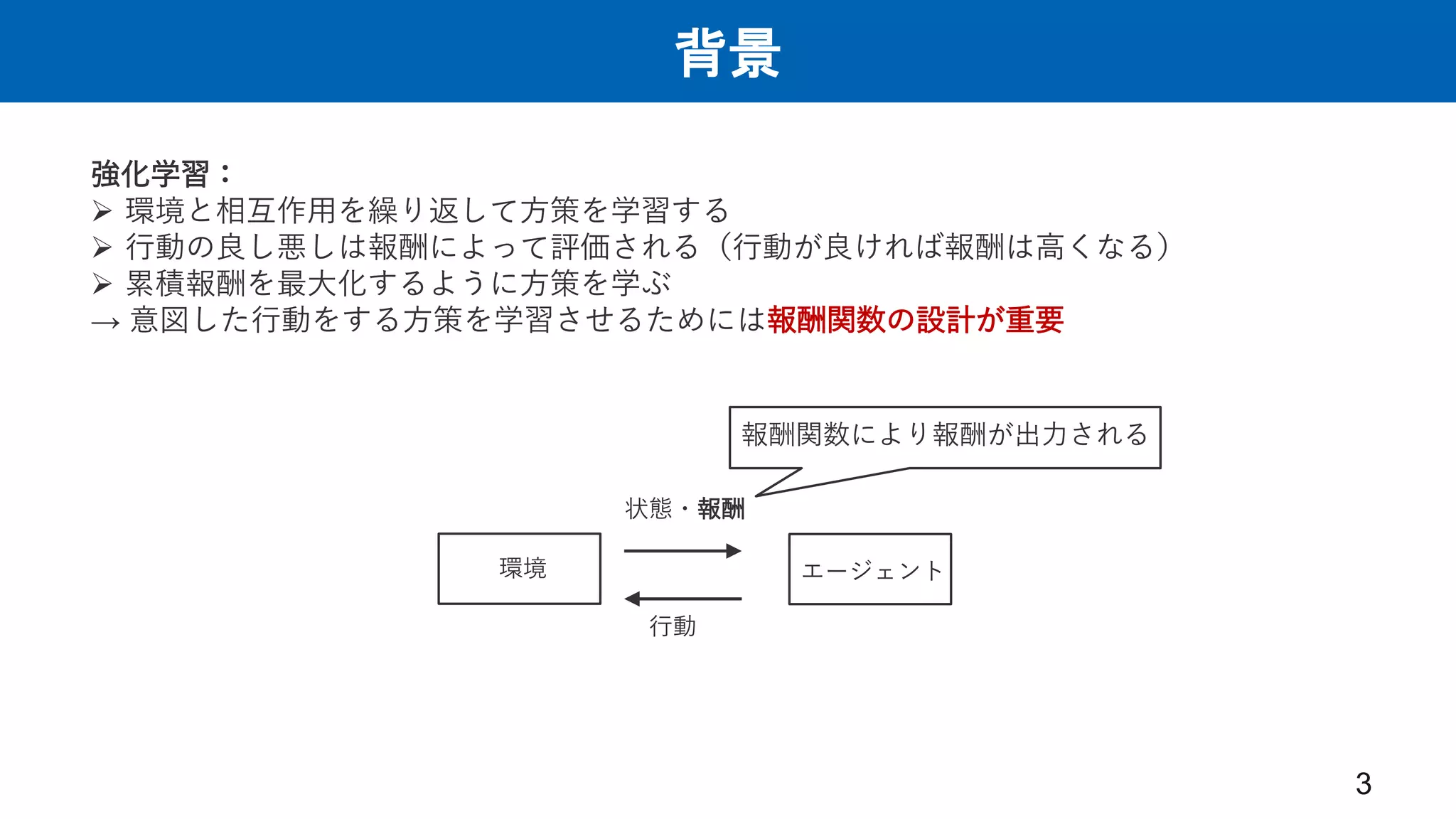
背景 3 強化学習: 環境と相互作用を繰り返して方策を学習する 行動の良し悪しは報酬によって評価される(行動が良ければ報酬は高くなる)
累積報酬を最大化するように方策を学ぶ → 意図した行動をする方策を学習させるためには報酬関数の設計が重要 エージェント 環境 状態・報酬 行動 報酬関数により報酬が出力される
4.
課題 4 意図した行動を学ぶための報酬関数をより簡単に得たい 課題: 意図した行動を学ぶための報酬関数の設計は難しい 報酬関数を学習する場合は、教師データが大量に必要となるため準備コストが高い
5.
研究目的 5 研究目的: プロンプトを用いて強化学習の報酬関数を設計することで、意図したようにエージェントを学習させたい 本研究では、強化学習の報酬関数の設計に自然言語処理の観点からアプローチする タスクの説明といくつかの例を入力の接頭辞として付加することで、 大規模言語モデルのパラメータを更新せずに新しいタスクに適応させる 関連研究:Learning from Human
Feedback [2] 人のフィードバックを活用した強化学習により人が受け入れやすい文章を生成 関連研究:プロンプト [1] ゼロ・少数ショット学習で新しいタスクに適応するために、 プロンプトを用いたフレームワークが提案されている [1] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. [2] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).
6.
提案する強化学習フレームワーク 6 (1) 大規模言語モデル(Large Language
Model: LLM)にプロンプトを入力 (2) LLMがエージェントの行動の良し悪しを文字で出力 (3) 文字を0, 1の報酬に変換 (4) エージェントを強化学習、エピソードを実行 (5) エピソードの結果を文字に変換してプロンプトに含める プロンプトの例 意図を反映させた文→ エージェントの行動結果→ タスクの説明→ 行動の良し悪しを質問→
7.
数値実験の概要 7 提案手法の性能検証のために以下の実験を実施 ① Ultimatum Game: 少数の正解例でLLMはユーザの意図に沿った報酬を出力可能か検証 ②
Matrix Games: ゼロショットでできるかを検証 ③ Deal Or No Deal: ①②よりステップ数の長い複雑なタスクの場合の性能を検証 ① Labeling Accuracy: 強化学習中に真の報酬関数の出力を正解として、提案する報酬関数の正解率を算出 真の報酬関数(ユーザの意図を100%反映した理想的な報酬関数)を用いて、以下の評価指標を設定 ② RL Agent Accuracy: 学習後のエージェントの性能を真の報酬関数で評価
8.
実験1 Ultimatum Game 8 Ultimatum
Game(最後通牒ゲーム): 提案者と応答者の2人で資金を分割するゲーム 提案した分割金額を応答者が承諾するとその金額を獲得できるが、拒否するとどちらも獲得できない → ユーザが意図したように承諾/拒否する応答者(≒エージェント)を強化学習する ユーザの意図(3パターン): Low vs High Percentages:金額が全体の{30%, 60%}以下の場合は拒否 Low vs High Payoffs:金額が{$10, $100}以下の場合は拒否 Inequity Aversion:金額が提案者と等しくない場合は拒否 プロンプト設計(2パターン): 10個の正解例をプロンプトに含める タスクの説明と1個の正解例をプロンプトに含める プロンプト設計例 (タスクの説明文と1個の正解例を含めた場合)
9.
実験1 Ultimatum Game(結果) 9 Labeling
Accuracy: 10個の正解例 → SLとLLMは同程度 タスクの説明+1個の正解例 → 10個の正解例と比較してSLは性能を落としたが、LLMは性能を維持 → タスクの説明の重要性を示唆 RL Agent Accuracy: Labeling Accuracyと同様の傾向 → LLMはタスクの説明と少数の正解例でユーザの意図を反映させた報酬関数となる SL :正解例を用いて教師あり学習で報酬関数を学習 Ours:提案するLLMを報酬関数とする手法 True Reward:真の報酬関数を用いてエージェントを強化学習
10.
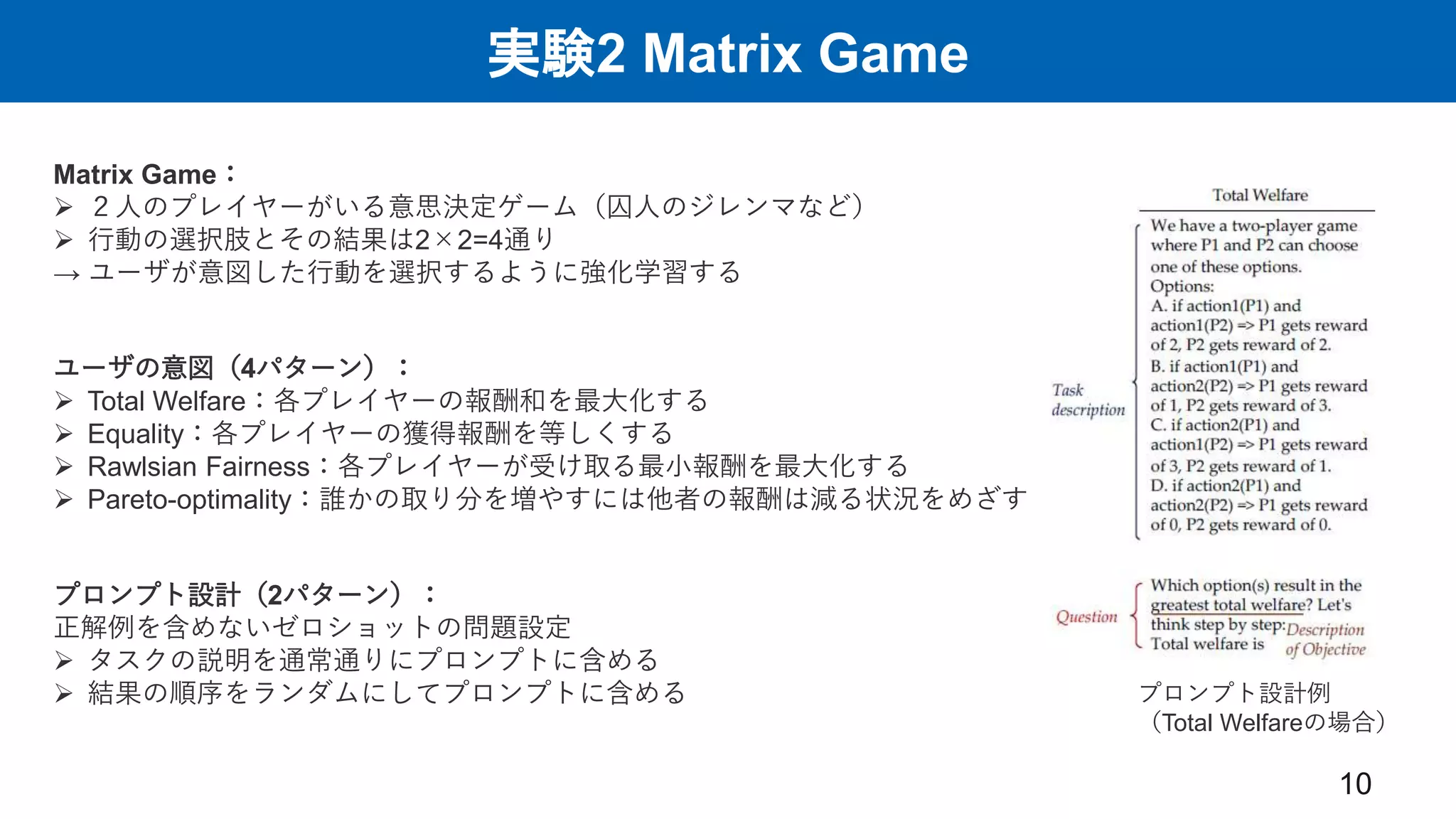
実験2 Matrix Game 10 Matrix
Game: 2人のプレイヤーがいる意思決定ゲーム(囚人のジレンマなど) 行動の選択肢とその結果は2×2=4通り → ユーザが意図した行動を選択するように強化学習する ユーザの意図(4パターン): Total Welfare:各プレイヤーの報酬和を最大化する Equality:各プレイヤーの獲得報酬を等しくする Rawlsian Fairness:各プレイヤーが受け取る最小報酬を最大化する Pareto-optimality:誰かの取り分を増やすには他者の報酬は減る状況をめざす プロンプト設計(2パターン): 正解例を含めないゼロショットの問題設定 タスクの説明を通常通りにプロンプトに含める 結果の順序をランダムにしてプロンプトに含める プロンプト設計例 (Total Welfareの場合)
11.
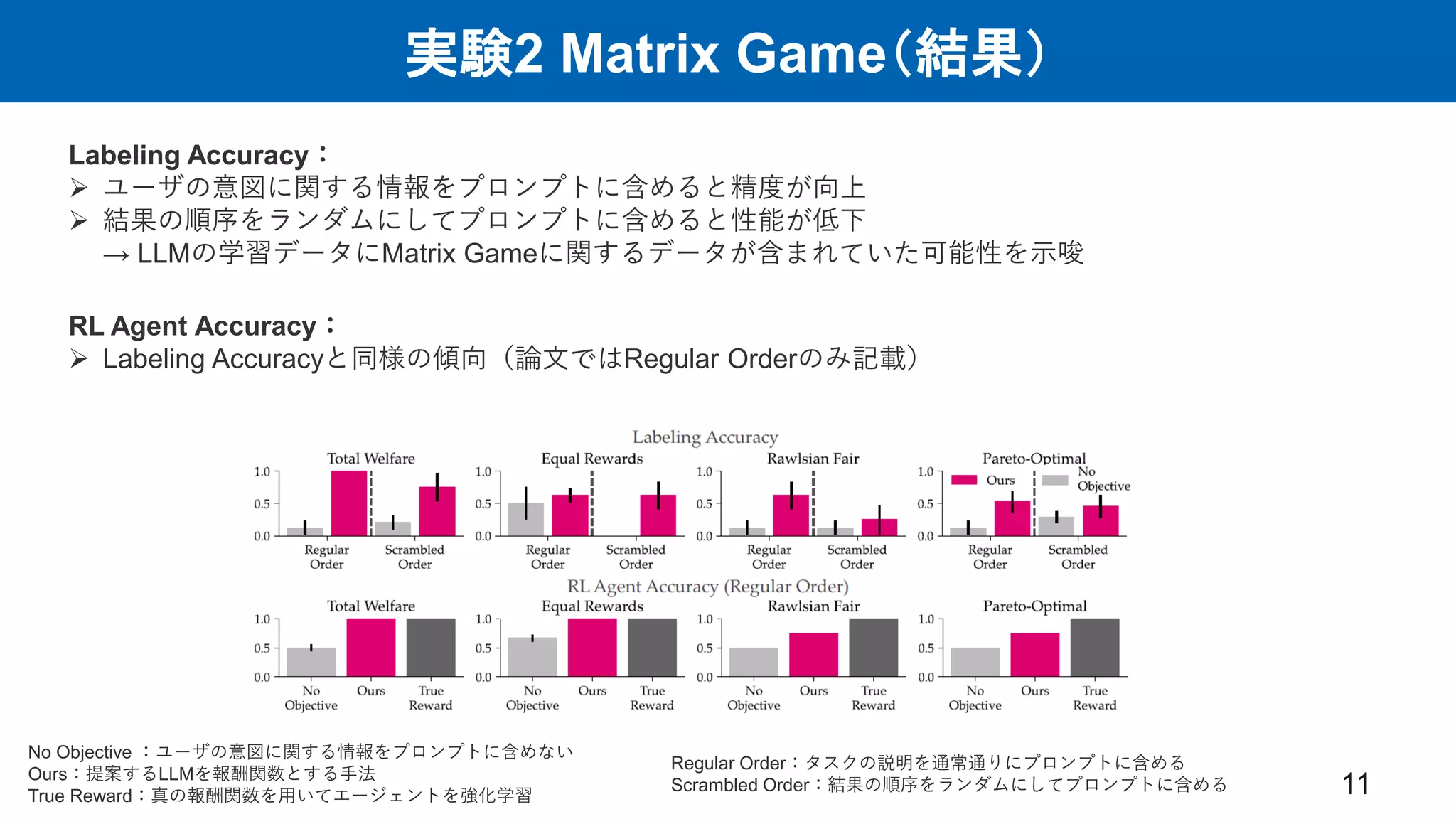
実験2 Matrix Game(結果) 11 Labeling
Accuracy: ユーザの意図に関する情報をプロンプトに含めると精度が向上 結果の順序をランダムにしてプロンプトに含めると性能が低下 → LLMの学習データにMatrix Gameに関するデータが含まれていた可能性を示唆 RL Agent Accuracy: Labeling Accuracyと同様の傾向(論文ではRegular Orderのみ記載) No Objective :ユーザの意図に関する情報をプロンプトに含めない Ours:提案するLLMを報酬関数とする手法 True Reward:真の報酬関数を用いてエージェントを強化学習 Regular Order:タスクの説明を通常通りにプロンプトに含める Scrambled Order:結果の順序をランダムにしてプロンプトに含める
12.
実験3 Deal or
No Deal 12 Deal or No Deal: アリスとボブで物の配分を合意形成するゲーム 配分に従いポイントを獲得できるが、合意に至らない場合はポイントを得られない → ユーザが意図したように交渉するアリス(≒エージェント)を強化学習する(ボブは固定) ユーザの意図(4パターン): Versatile:同じ提案をしない Push-Over:ポイントをボブより少なくする Competitive:ポイントをボブより多くする Stubborn:同じ提案を繰り返す プロンプト設計: 3個の正解例をプロンプトに含める
13.
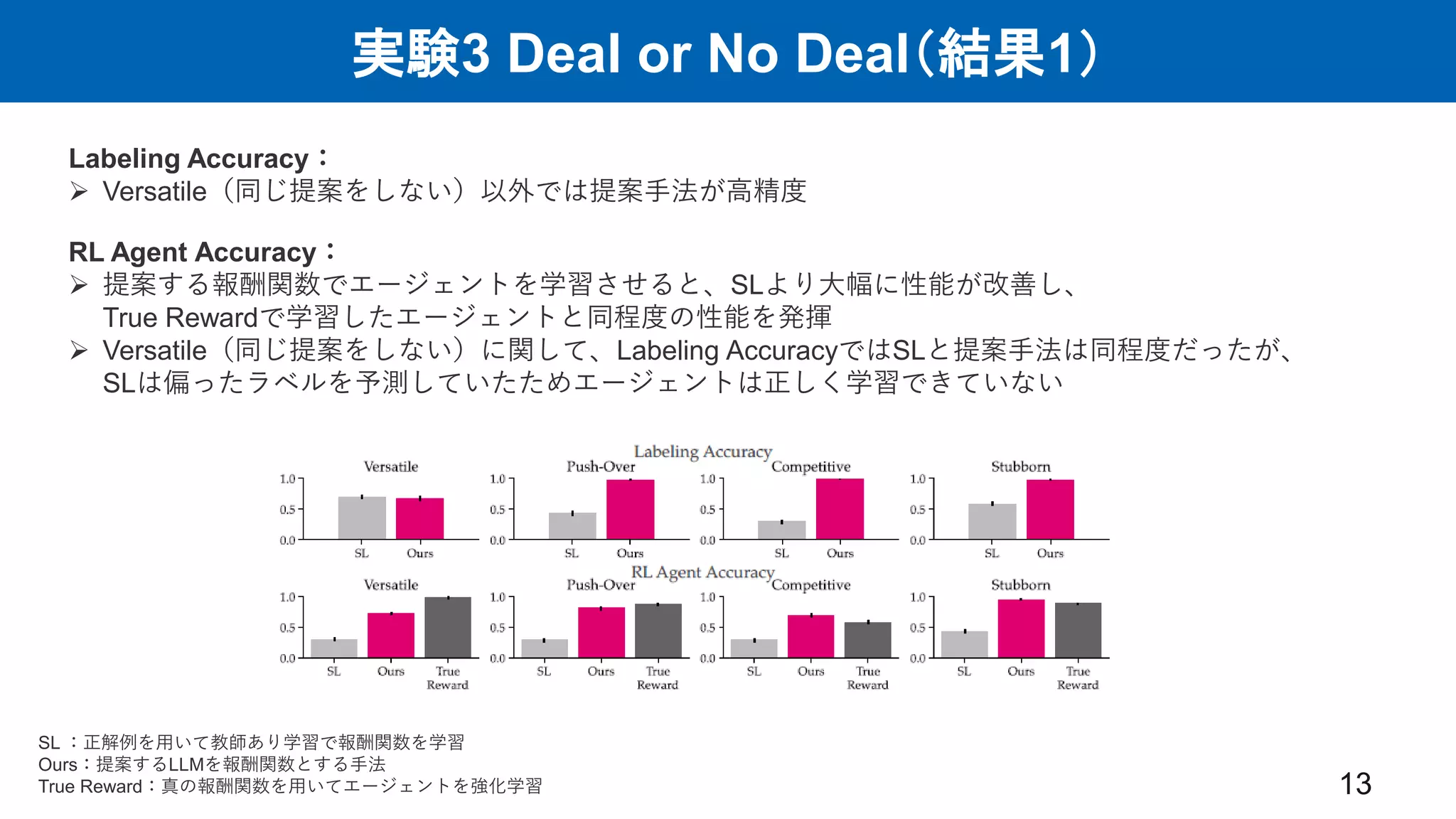
実験3 Deal or
No Deal(結果1) 13 Labeling Accuracy: Versatile(同じ提案をしない)以外では提案手法が高精度 RL Agent Accuracy: 提案する報酬関数でエージェントを学習させると、SLより大幅に性能が改善し、 True Rewardで学習したエージェントと同程度の性能を発揮 Versatile(同じ提案をしない)に関して、Labeling AccuracyではSLと提案手法は同程度だったが、 SLは偏ったラベルを予測していたためエージェントは正しく学習できていない SL :正解例を用いて教師あり学習で報酬関数を学習 Ours:提案するLLMを報酬関数とする手法 True Reward:真の報酬関数を用いてエージェントを強化学習
14.
実験3 Deal or
No Deal(結果2) 14 エージェントの交渉スタイルの差を検証: 学習後の各エージェントの交渉スタイルがどの程度異なるかを評価 3つの指標を計算 Advantage:アリスのスコア-ボブのスコア Diversity:アリスが異なる提案をする割合 Agreement Rate:合意に至った割合 検証結果: 4つの交渉スタイルで指標の値が明確に異なる → ユーザの意図に合うように交渉スタイルを変えている
15.
実験3 Deal or
No Deal(Pilot Study) 15 Pilot Studyの概要: 前述した結果は真の報酬関数(ユーザの意図を100%反映した理想的な報酬関数)を正解として 性能評価を実施していた Pilot Studyでは、個々のユーザだけが意図を評価できる場合を実験 実験手順: ① 10人のユーザに特定の交渉スタイルを選択してもらう ② 選択したスタイルに適する/適さない交渉例を3つ選んでもらう ③ ②で選んだ交渉例が特定の交渉スタイルに合っているかをyes/noで質問する ④ 2パターンのプロンプトを設計 ・ユーザの意図をそのままプロンプトに含めたもの ・ユーザの意図を反対にしてプロンプトに含めたもの ⑤ 学習後の交渉結果をユーザに提示して評価してもらう (スコアは1~5の範囲、5は最もスタイルに適すると判断したもの) 結果: ユーザの意図通りプロンプトを設計するとスコアが高く、 意図を反対にするとスコアが低い → ユーザは明確に違いを判断することができた
16.
まとめ 16 提案手法: 大規模言語モデルを報酬関数として使用する強化学習フレームワークを提案 ユーザの意図をプロンプトに入力して報酬関数を設計 数値実験:
3パターンの数値実験を実施 ・Ultimatum Game(最後通牒ゲーム) ・Matrix Game ・Deal or No Deal 従来の教師あり学習などと比較して報酬関数の精度が向上 → ユーザの意図に沿ったエージェントの強化学習が可能
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
DL輪読会:Reward Design with Language Models
Ryoichi Takase](https://image.slidesharecdn.com/20230421rewarddesignllm-230421025723-40b9d01c/75/DL-Reward-Design-with-Language-Models-1-2048.jpg)


![研究目的
5
研究目的:
プロンプトを用いて強化学習の報酬関数を設計することで、意図したようにエージェントを学習させたい
本研究では、強化学習の報酬関数の設計に自然言語処理の観点からアプローチする
タスクの説明といくつかの例を入力の接頭辞として付加することで、
大規模言語モデルのパラメータを更新せずに新しいタスクに適応させる
関連研究:Learning from Human Feedback [2]
人のフィードバックを活用した強化学習により人が受け入れやすい文章を生成
関連研究:プロンプト [1]
ゼロ・少数ショット学習で新しいタスクに適応するために、
プロンプトを用いたフレームワークが提案されている
[1] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
[2] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).](https://image.slidesharecdn.com/20230421rewarddesignllm-230421025723-40b9d01c/75/DL-Reward-Design-with-Language-Models-5-2048.jpg)











![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)



































