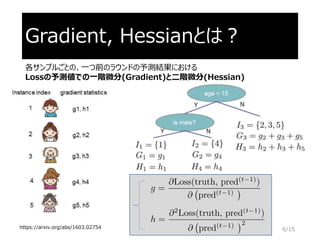
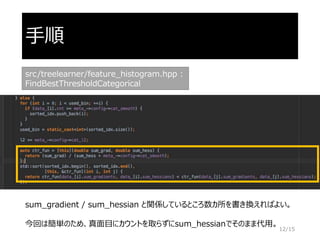
LightGBM独自のエンコード手法
LightGBM sorts thehistogram (for a categorical feature) according
to its accumulated values (sum_gradient / sum_hessian) and then
finds the best split on the sorted histogram.
https://arxiv.org/abs/1603.02754
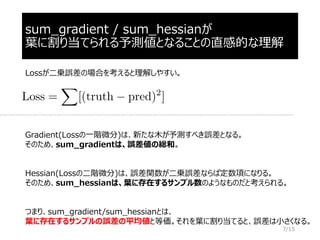
sum_gradient / sum_hessianと書かれると分かりにくいが、
結論を言うと、LightGBMは葉に割り当てられる予測値を用いてエンコードしている。
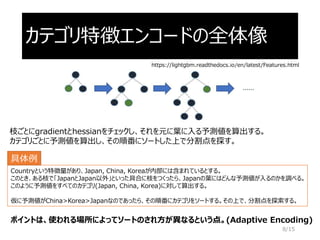
公式ドキュメント
5/15
https://lightgbm.readthedocs.io/en/latest/Features.html#optimal-split-for-categorical-features






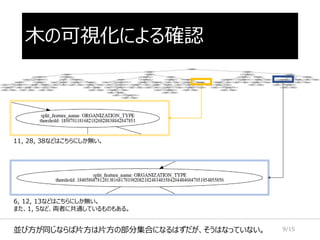

![手順
• GitHubからLightGBMのコード(C++)を持ってきて、
実装変更後に自分でビルドする。
# Download
> git clone --recursive https://github.com/Microsoft/LightGBM
> [コードを書き換える…]
# Compile
> cd LightGBM
> mkdir build
> cd build
> cmake ..
> make -j4
# Python API
> cd ../python_package
> python setup.py install
11/15](https://image.slidesharecdn.com/kagglemeetupltrk-181201023316/85/LightGBM-11-320.jpg)








![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)