Downloaded 37 times




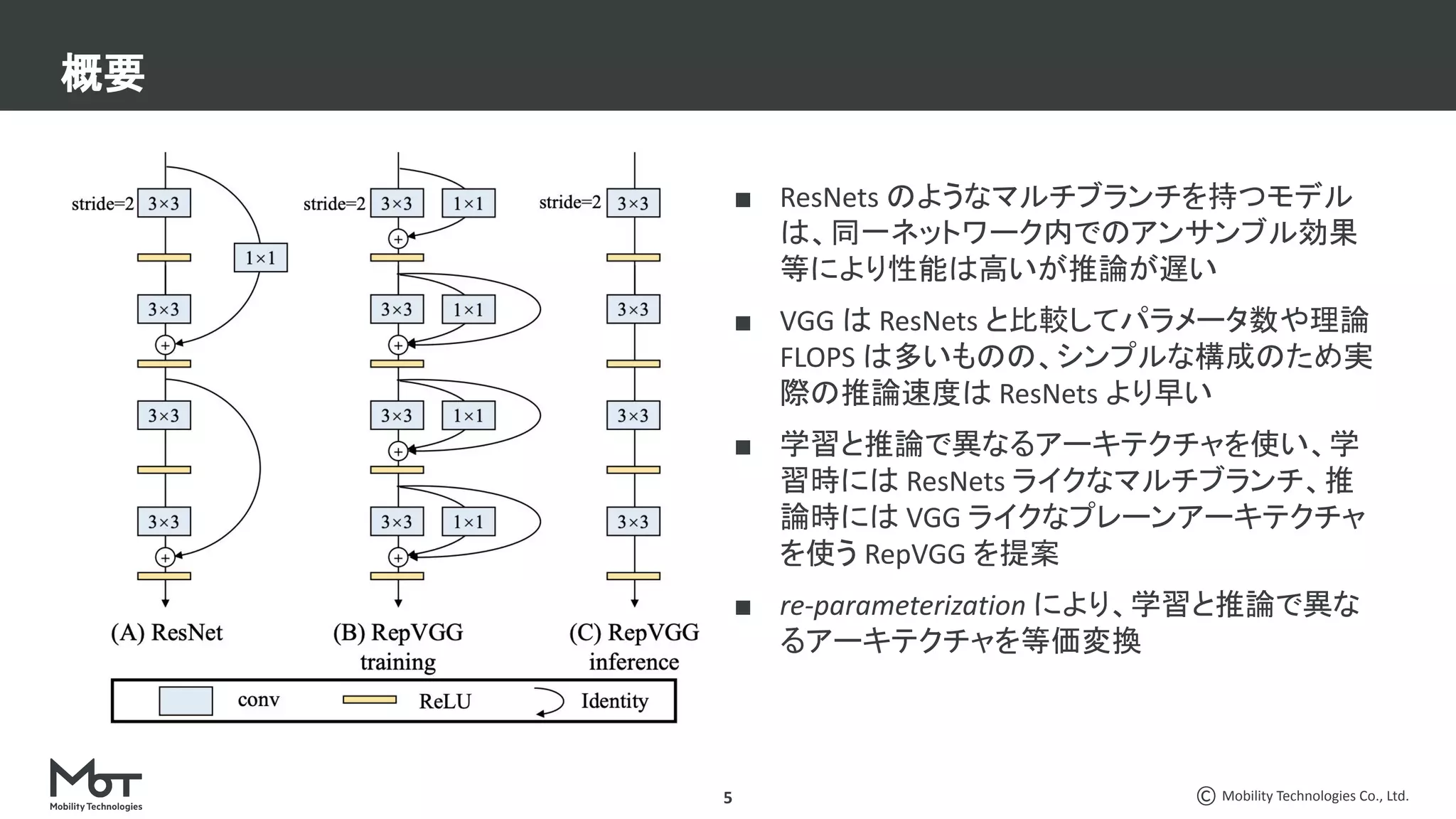
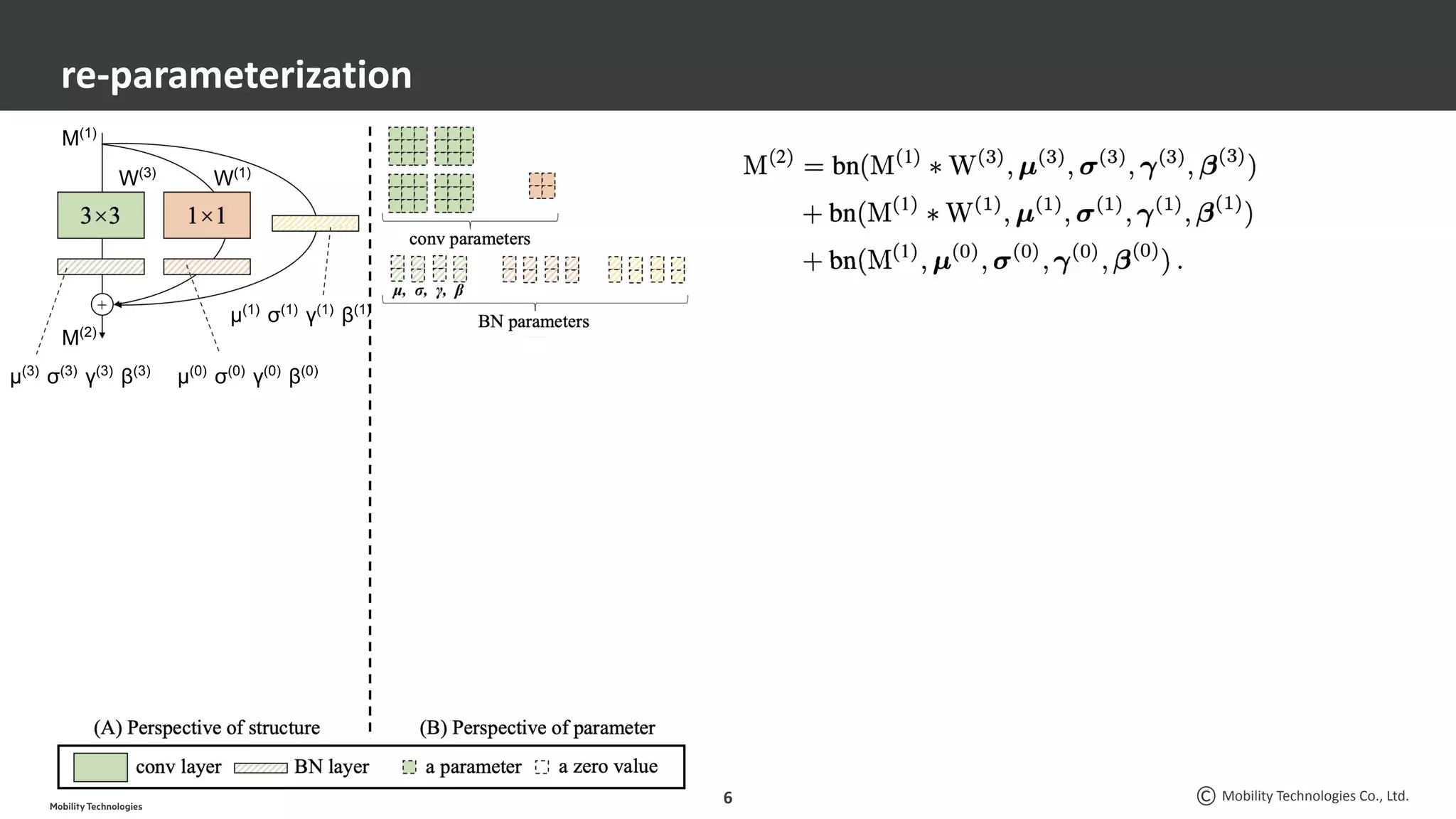
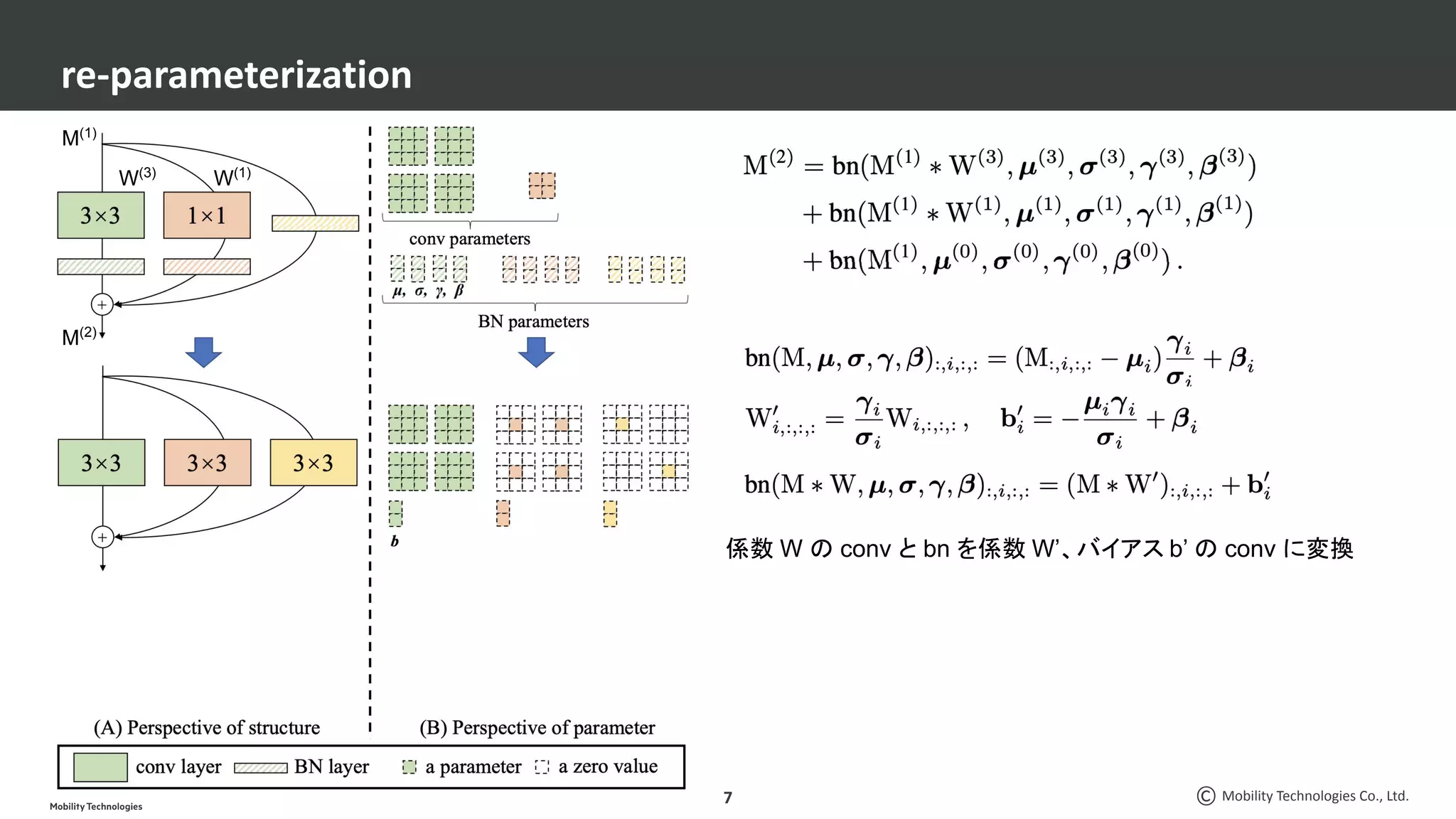














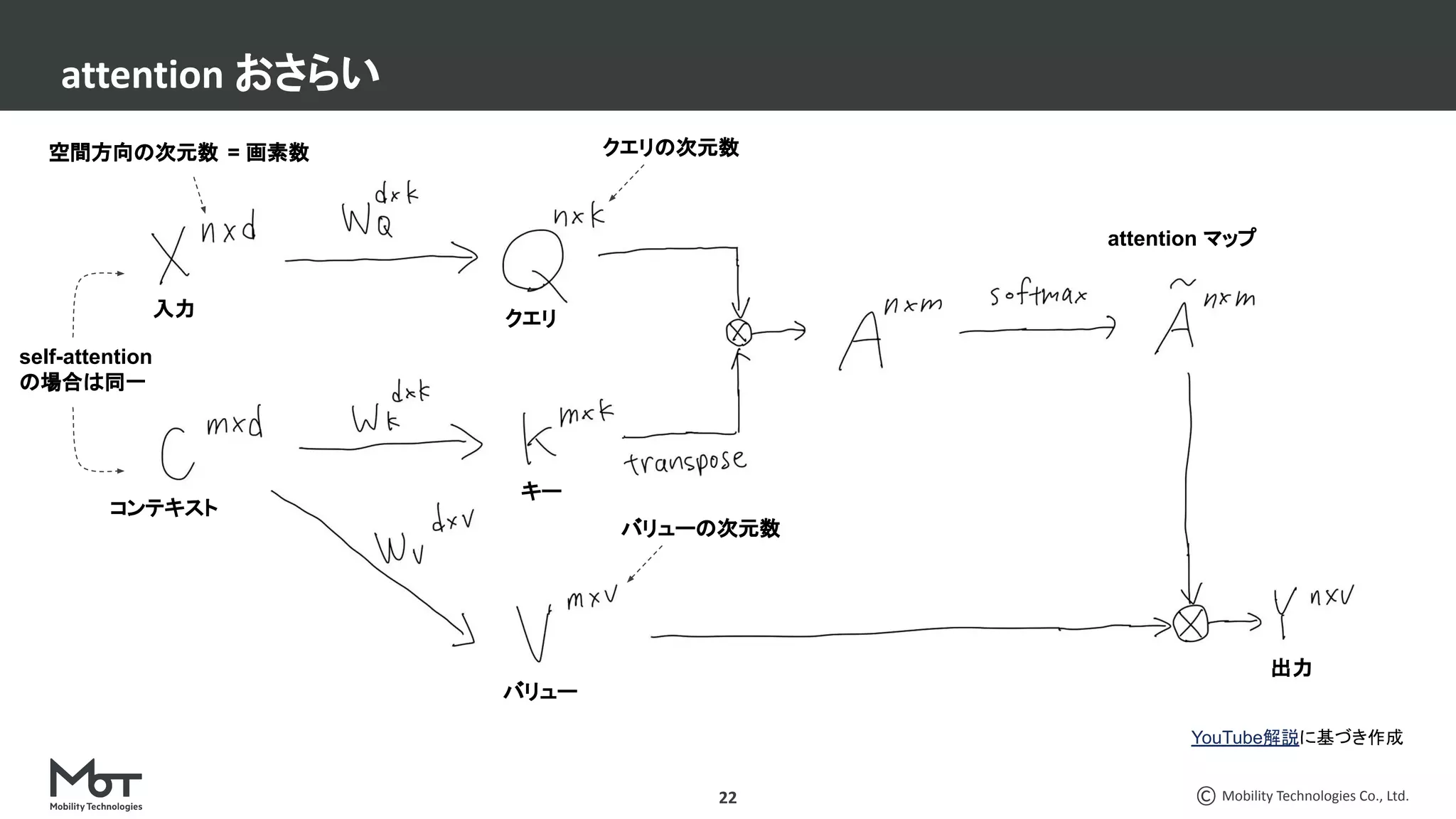
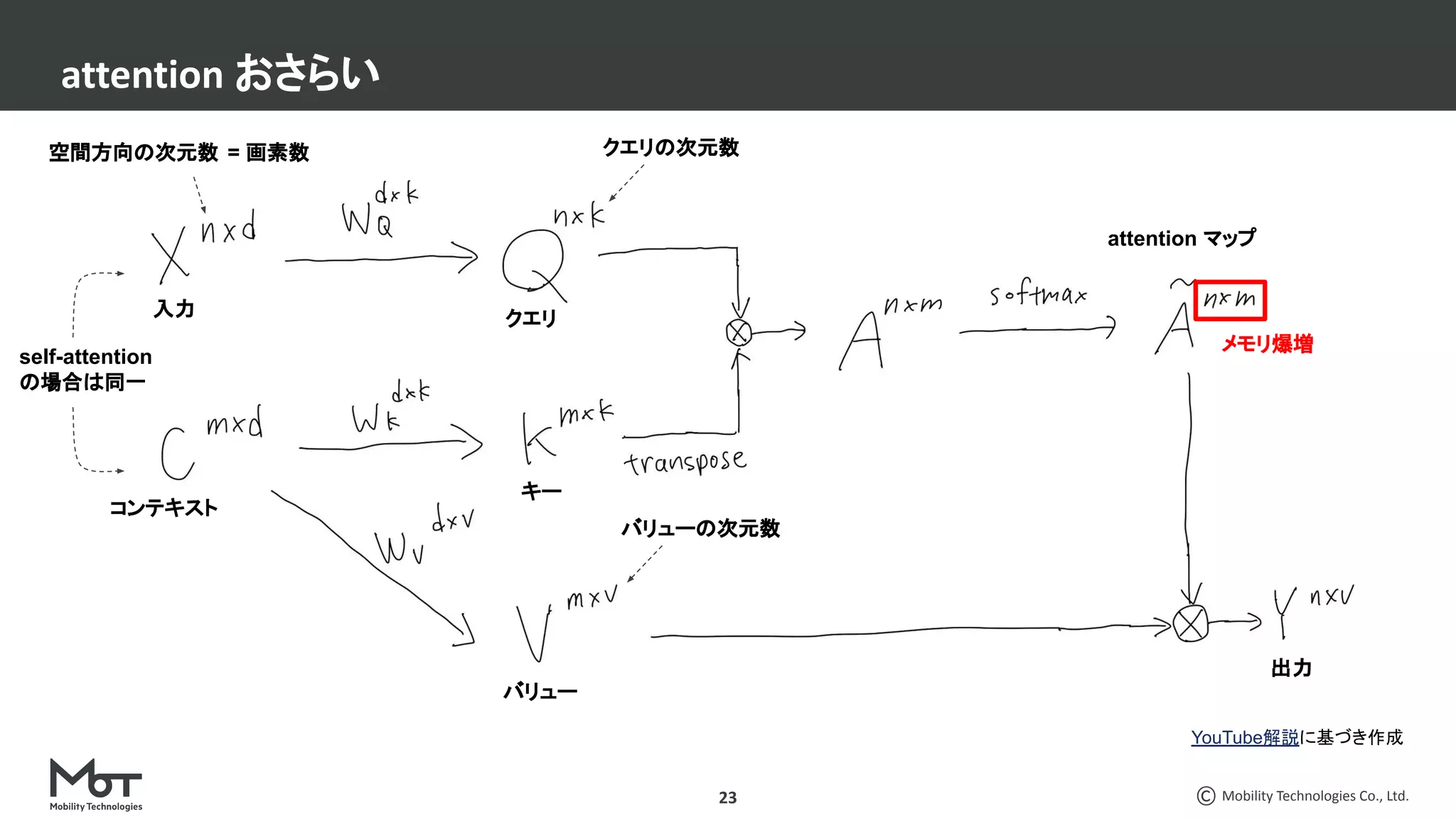
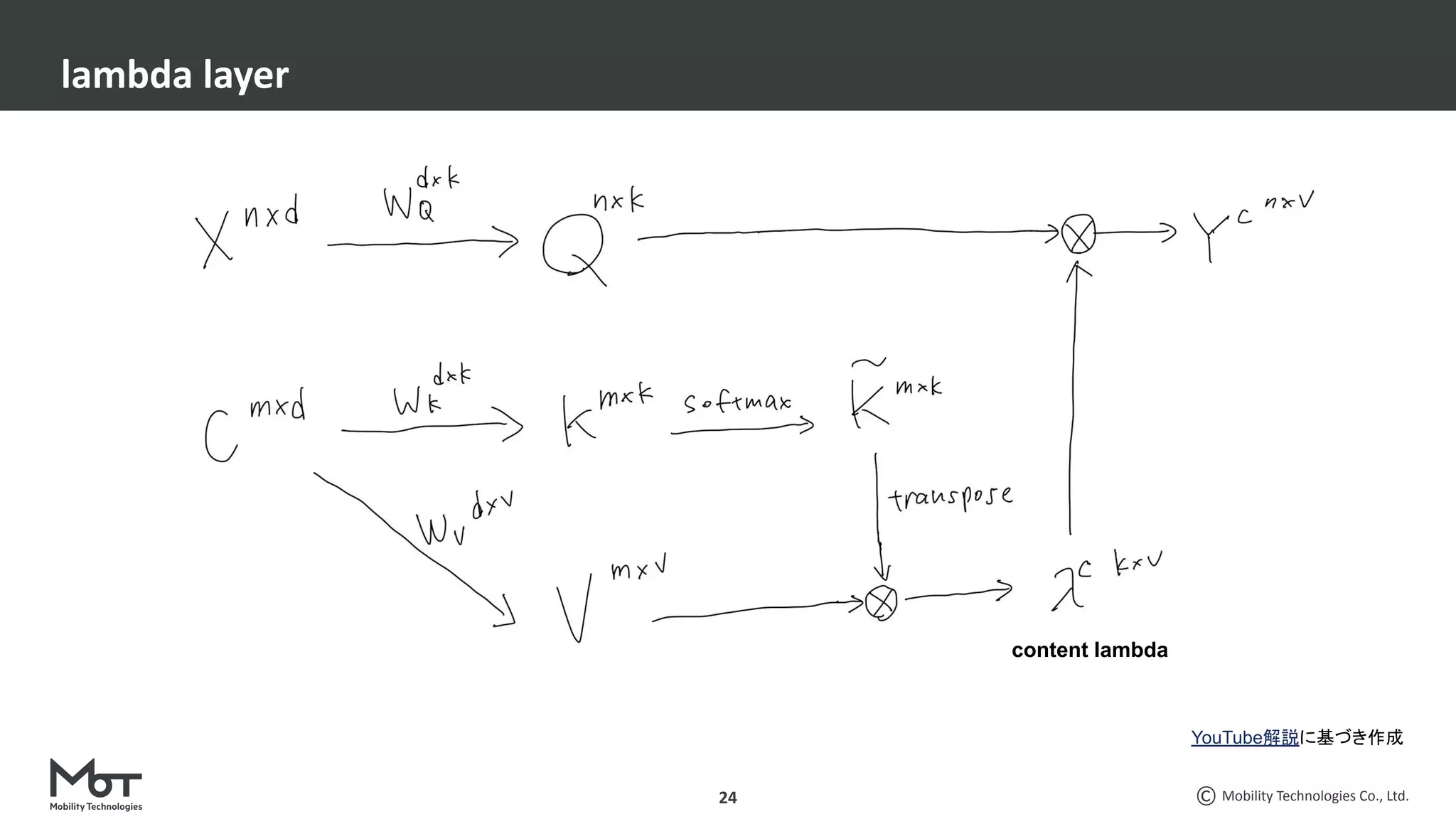


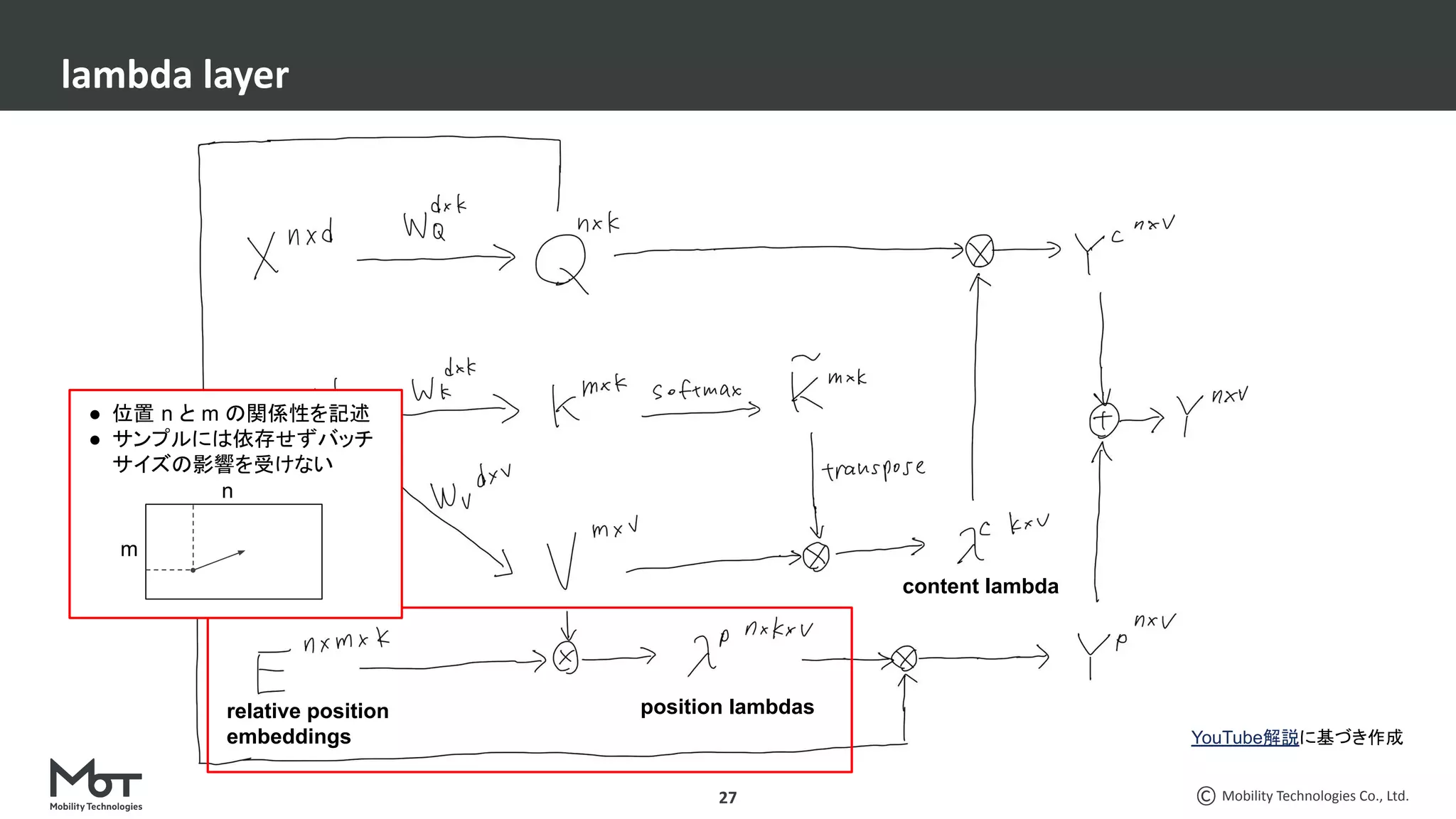


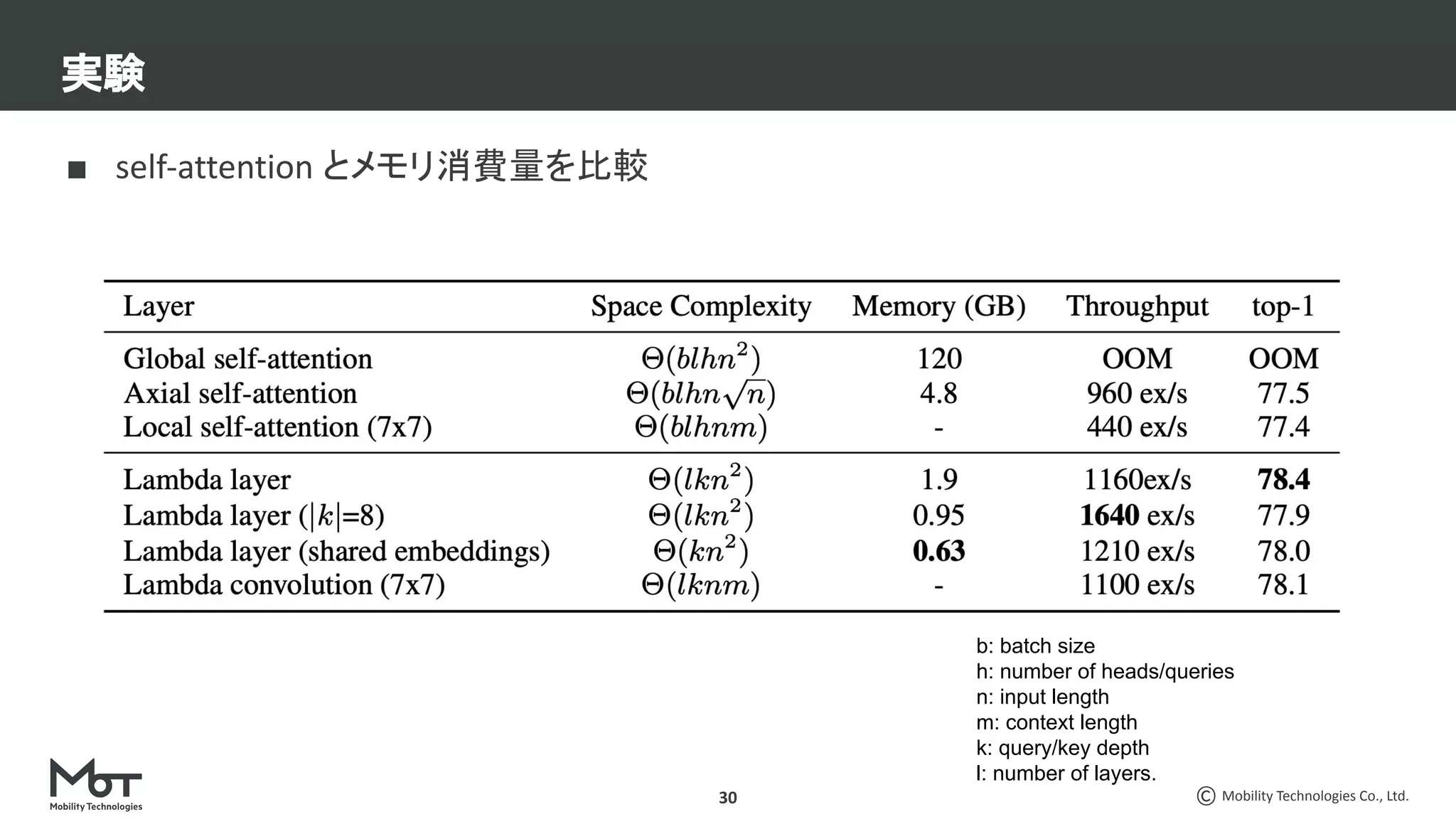





CV分野での最近の脱○○系論文3本を紹介します。 ・脱ResNets: RepVGG: Making VGG-style ConvNets Great Again ・脱BatchNorm: High-Performance Large-Scale Image Recognition Without Normalization ・脱attention: LambdaNetworks: Modeling Long-Range Interactions Without Attention







![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538-thumbnail.jpg?width=640&height=640&fit=bounds)














![[ビッグデータオールスターズ] クラウドサービス最新情報 機械学習/AIでこんなことまでできるんです! (Microsoft編)](https://cdn.slidesharecdn.com/ss_thumbnails/20161218dotsbigdataazureai-161218054508-thumbnail.jpg?width=640&height=640&fit=bounds)















