Downloaded 147 times




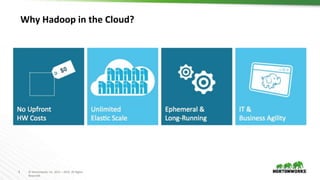
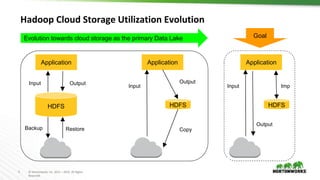


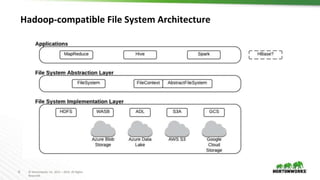

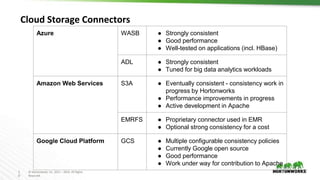






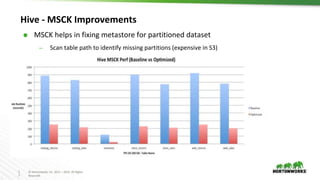
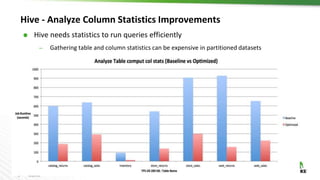


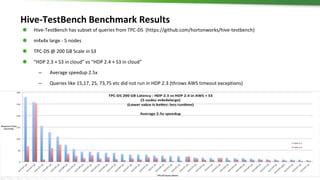






The document discusses Hadoop integration with cloud storage. It describes the Hadoop-compatible file system architecture, which allows applications to work with different storage systems transparently. Recent enhancements to the S3A connector for Amazon S3 are discussed, including performance improvements and support for encryption. Benchmark results show significant performance gains for Hive queries running on S3A compared to earlier versions. Upcoming work on consistency, output committers, and abstraction layers is outlined to further improve object store integration.











































































































