Downloaded 82 times




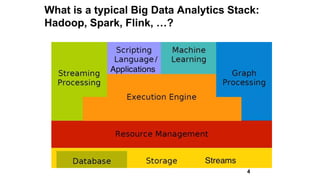




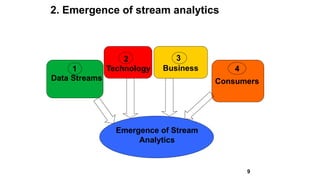
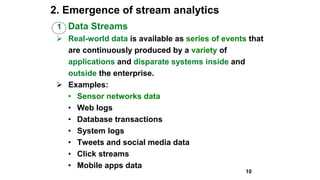

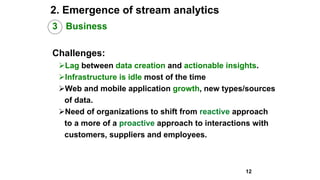

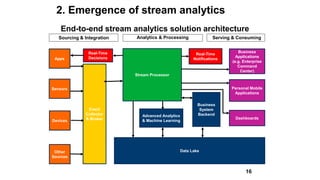









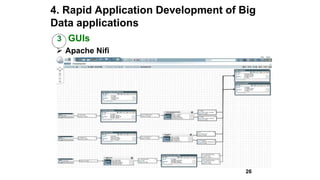











Slim Baltagi, director of Enterprise Architecture at Capital One, gave a presentation at Hadoop Summit on major trends in big data analytics. He discussed 1) increasing portability between execution engines using Apache Beam, 2) the emergence of stream analytics driven by data streams, technology advances, business needs and consumer demands, 3) the growth of in-memory analytics using tools like Alluxio and RocksDB, 4) rapid application development using APIs, notebooks, GUIs and microservices, 5) open sourcing of machine learning systems by tech giants, and 6) hybrid cloud computing models for deploying big data applications both on-premise and in the cloud.











































































































