Download as PDF, PPTX




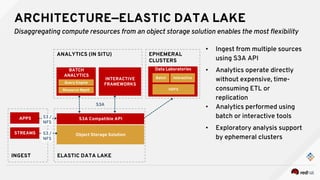
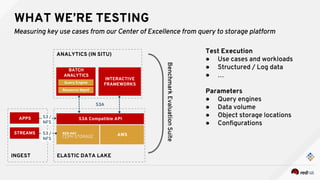













This document discusses using object storage for big data. It outlines key stakeholders in big data projects and what they want from object storage solutions. It then discusses using the Ceph object store to provide an elastic data lake that can disaggregate compute resources from storage. This allows analytics to be performed directly on the object store without expensive ETL processes. It also describes testing various analytics use cases and workloads with the Ceph object store.




















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)