Download as ODP, PPTX





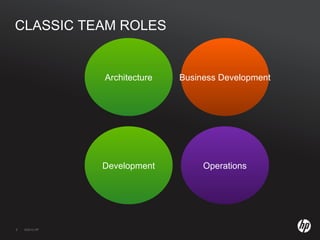
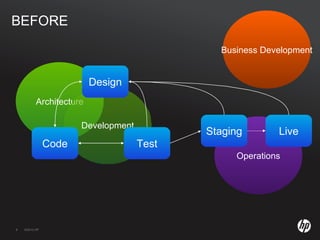

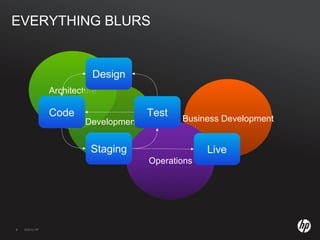
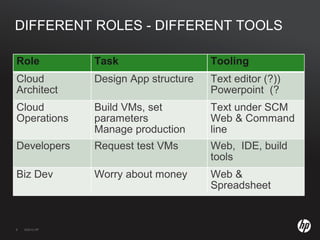



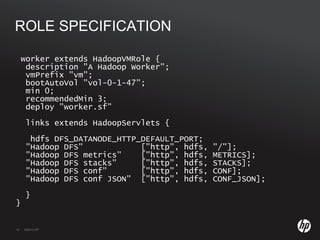

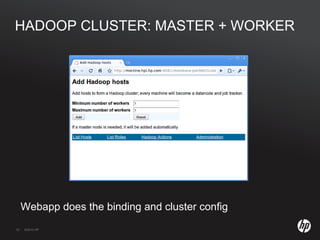
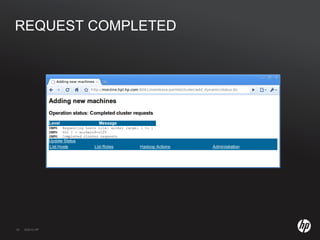
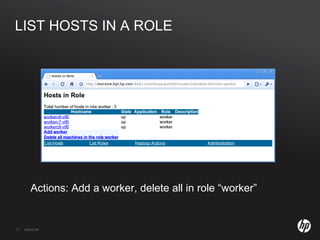
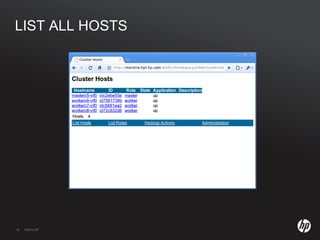
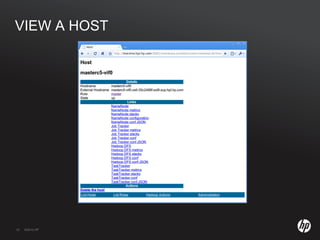
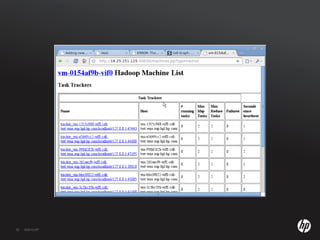
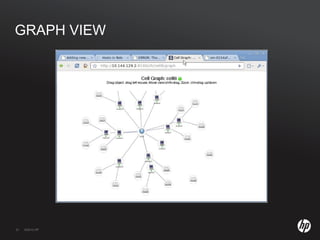




The document discusses running Hadoop clusters in the cloud and the challenges that presents. It introduces CloudFarmer, a tool that allows defining roles for VMs and dynamically allocating VMs to roles. This allows building agile Hadoop clusters in the cloud that can adapt as needs change without static configurations. CloudFarmer provides a web UI to manage roles and hosts.
































































































