Downloaded 133 times























![30 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
What’s new in Ambari 2.5 for upgrades?
30
● Auto Start of services
● Delete older version of the Software
● AMBARI-18435 Releases space used by older versions post upgrade. Previously this had to be done
manually. For eg,
curl 'http://c6401.ambari.apache.org:8080/api/v1/clusters/cl1/requests' -u admin:admin -H "X-Requested-By: ambari" -X POST -
d'{"RequestInfo":{"context":"remove_previous_stacks", "action" : "remove_previous_stacks", "parameters" : {"version":"2.5.0.0-
1245"}}, "Requests/resource_filters": [{"hosts":"c6403.ambari.apache.org, c6402.ambari.apache.org"}]}'
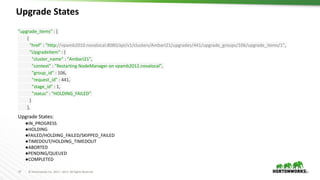
● Upgrade history
● Pulls all data about upgrades/downgrades from Ambari DB and displays in UI](https://image.slidesharecdn.com/april51750hortonworkssharmapoornalingam-170410123910/85/Apache-Ambari-HDP-Cluster-Upgrades-Operational-Deep-Dive-and-Troubleshooting-30-320.jpg)




The document presents an in-depth overview of upgrading Apache Ambari and Hadoop Data Platform (HDP) clusters, detailing the upgrade processes, prerequisites, methodologies, and troubleshooting techniques. It narrates a case study of a Hadoop administrator named Sam, who plans and executes an upgrade to Ambari 2.5 and HDP 2.6, emphasizing best practices and potential challenges. Additionally, it covers new features in Ambari 2.5, the importance of backup and compatibility checks, and the significance of documenting the upgrade process.























































































