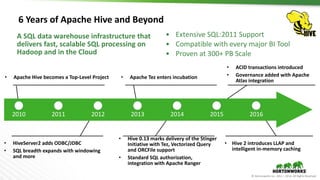
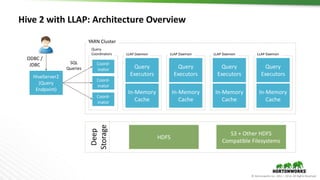
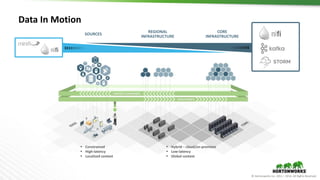
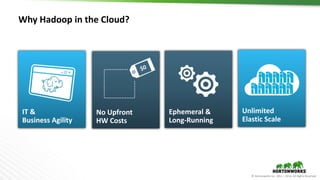
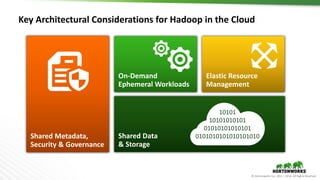
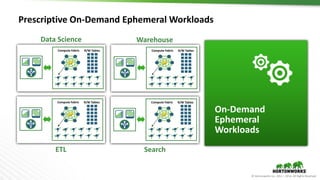
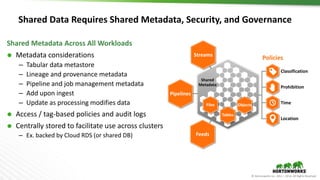
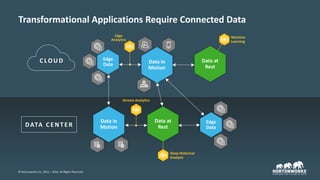
The document outlines the evolution and advancements in the Apache Hadoop ecosystem from its inception in 2006 to 2016, highlighting significant projects like Apache Hive and the improvements in performance and scalability through features like LLAP. It discusses the transition of Hadoop into cloud environments, focusing on architecture, resource management, data governance, and the advantages of cloud storage. Additionally, it emphasizes the importance of enhancing performance through caching and managing workloads effectively within cloud infrastructure.





















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








