Downloaded 31 times













![19 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
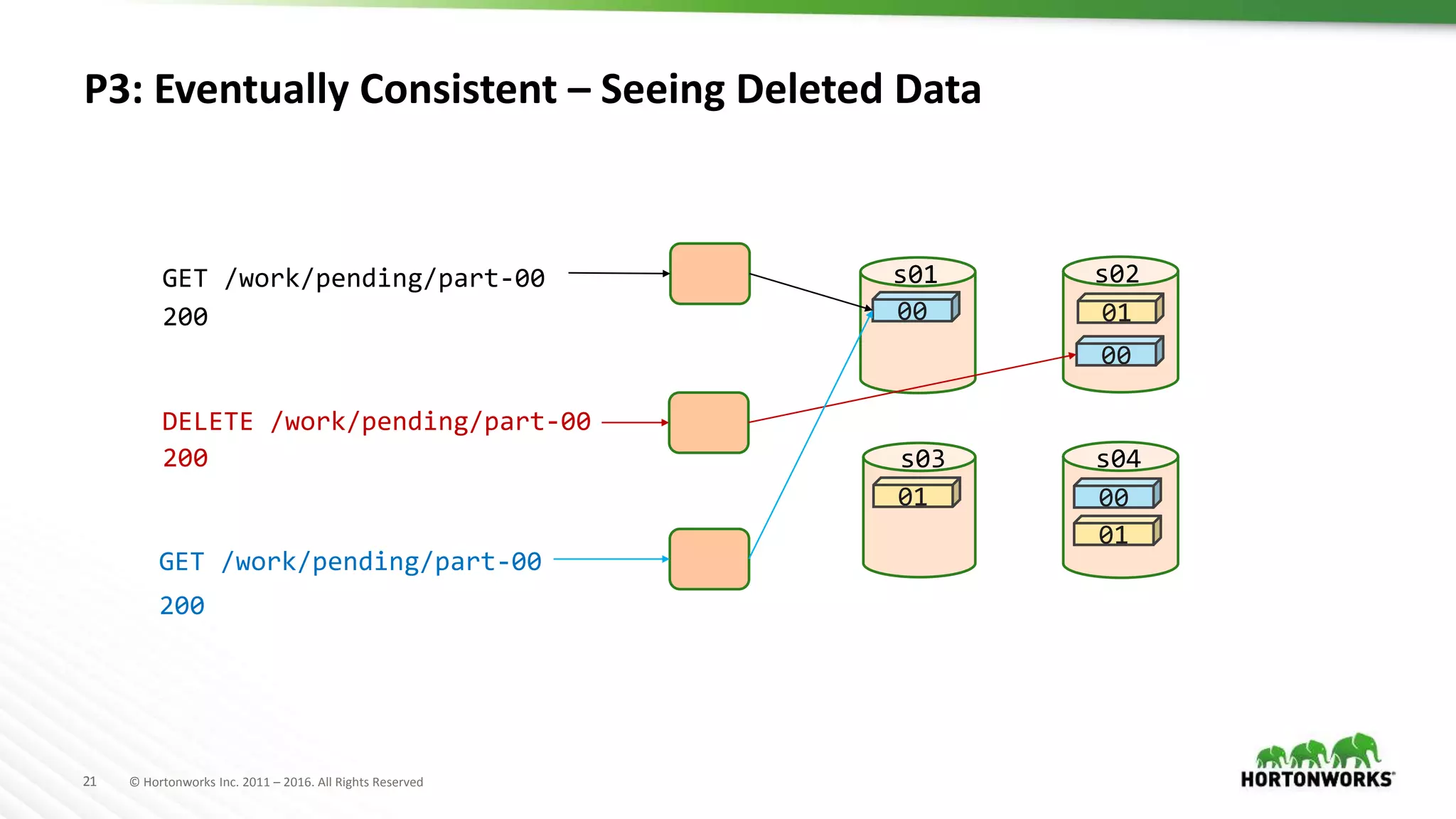
P2: Not Atomic API: rename()
A Series of Operations on The Client
00
00
00
01
01
s01 s02
s03 s04
hash("/work/pending/part-01")
["s02", "s03", "s04"]
copy("/work/pending/part-01",
"/work/complete/part01")
01
01
01
01
delete("/work/pending/part-01")
hash("/work/pending/part-00")
["s01", "s02", "s04"]](https://image.slidesharecdn.com/1493venkateshcloudywithachanceofhadooprealworldconsiderations-170626210949/75/Cloudy-with-a-chance-of-Hadoop-real-world-considerations-19-2048.jpg)



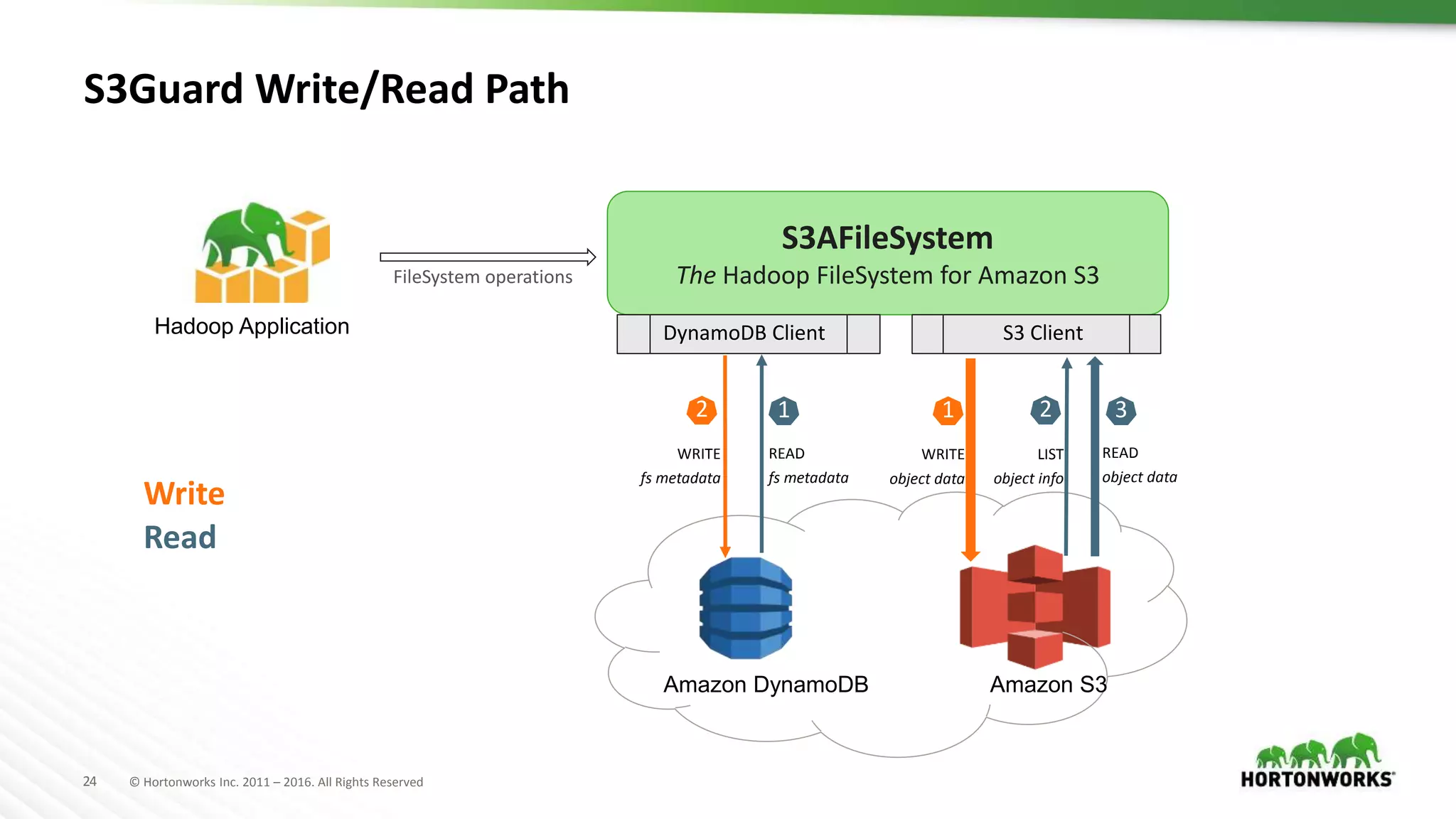
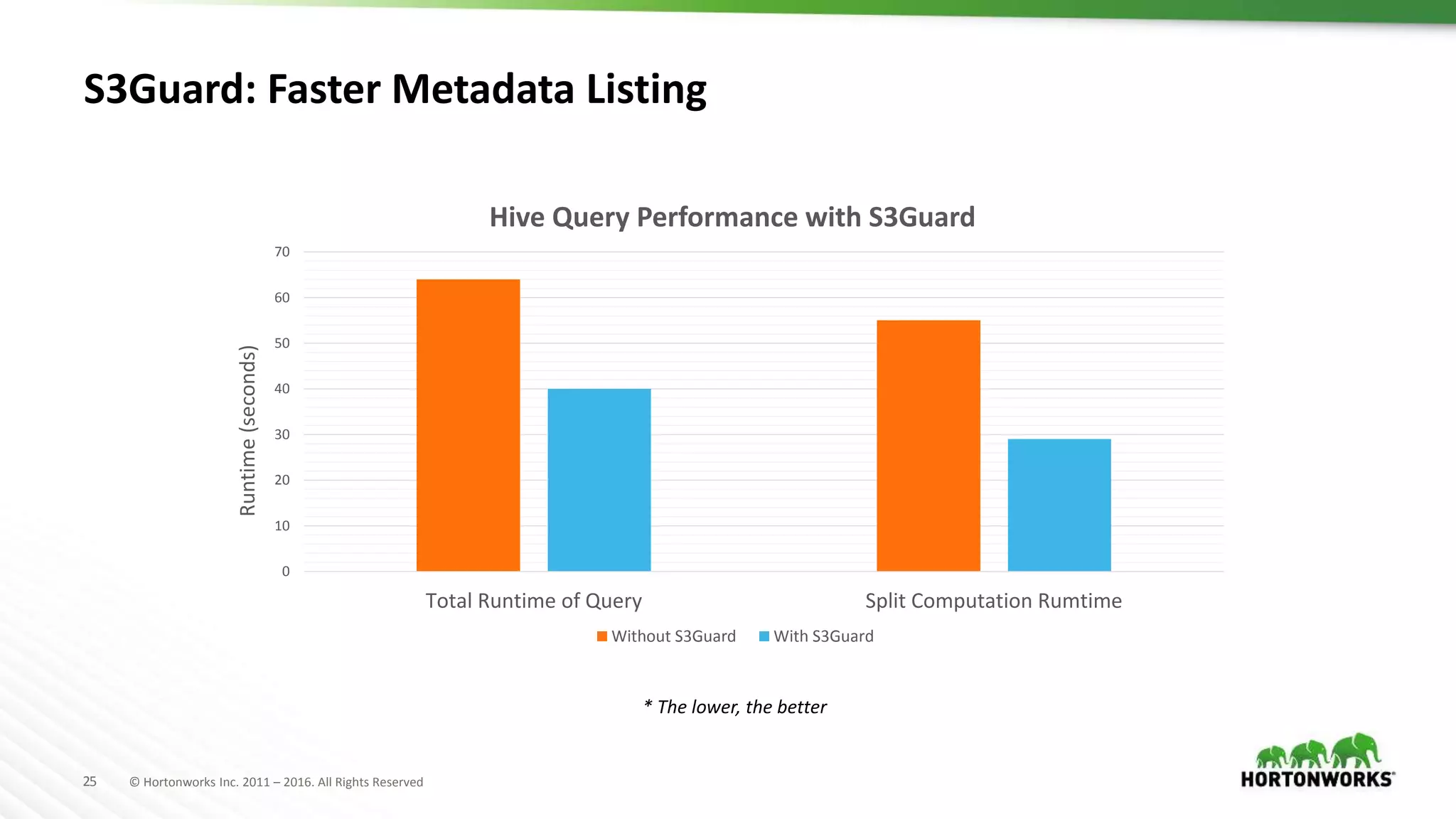




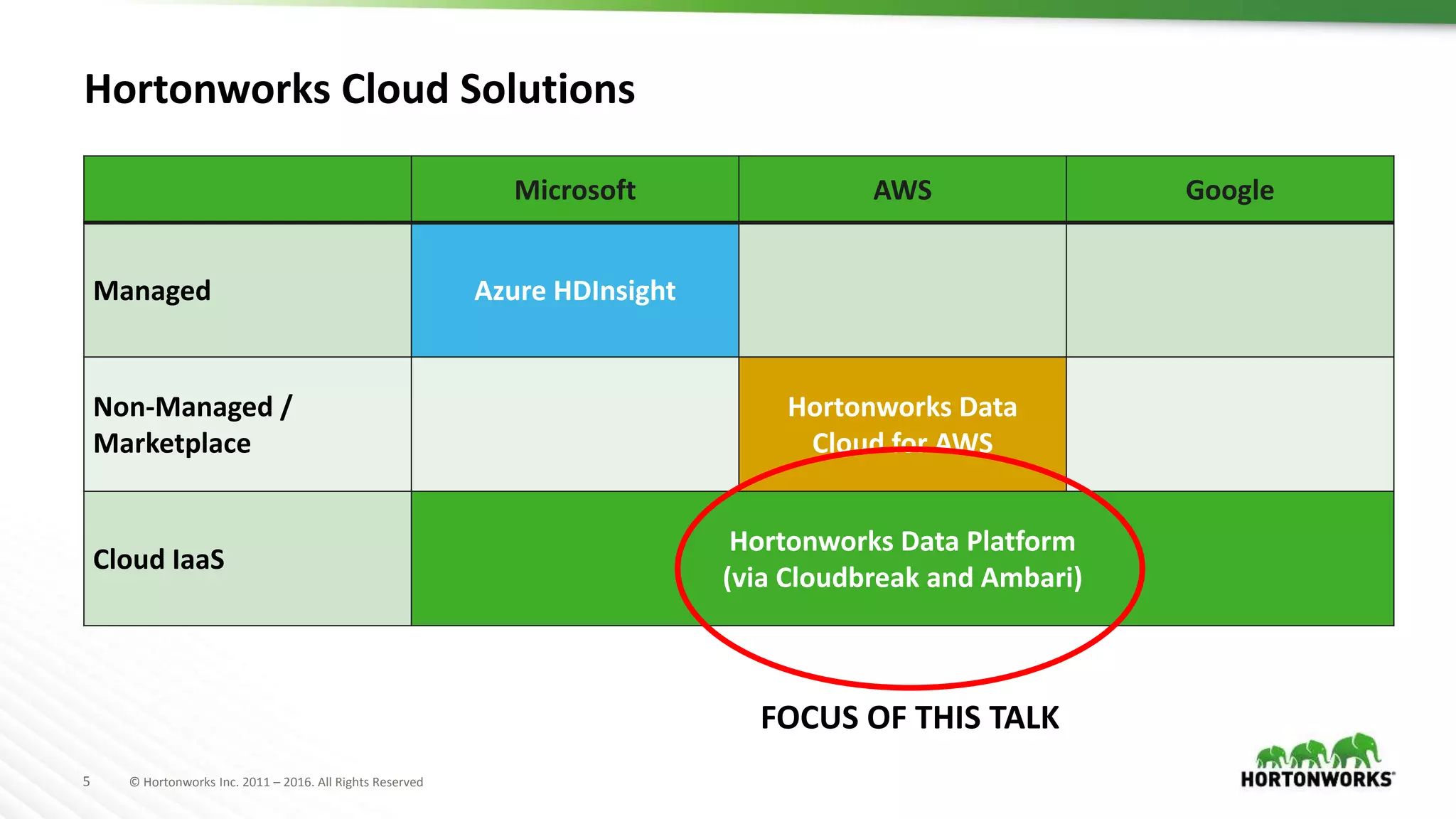
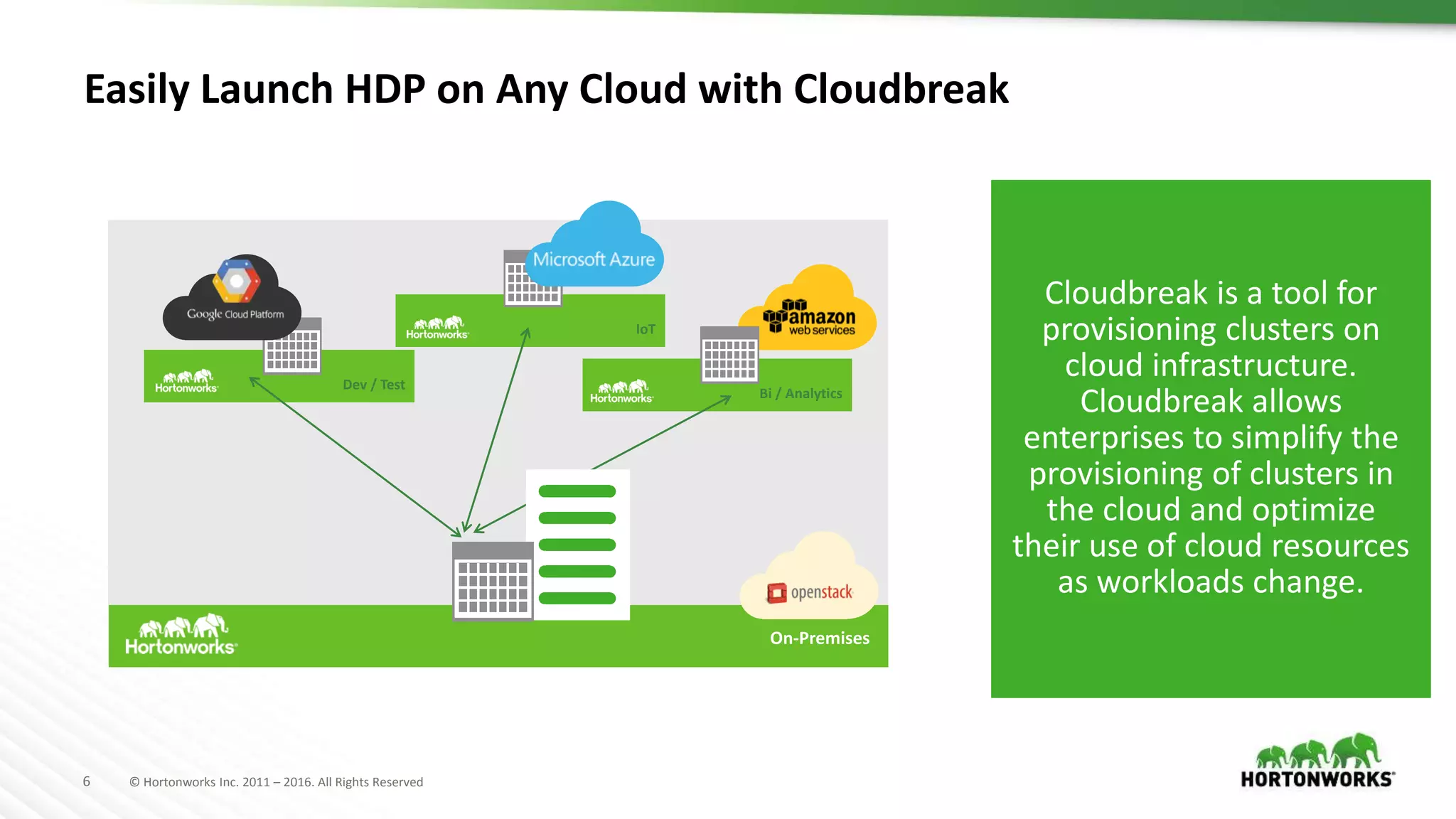
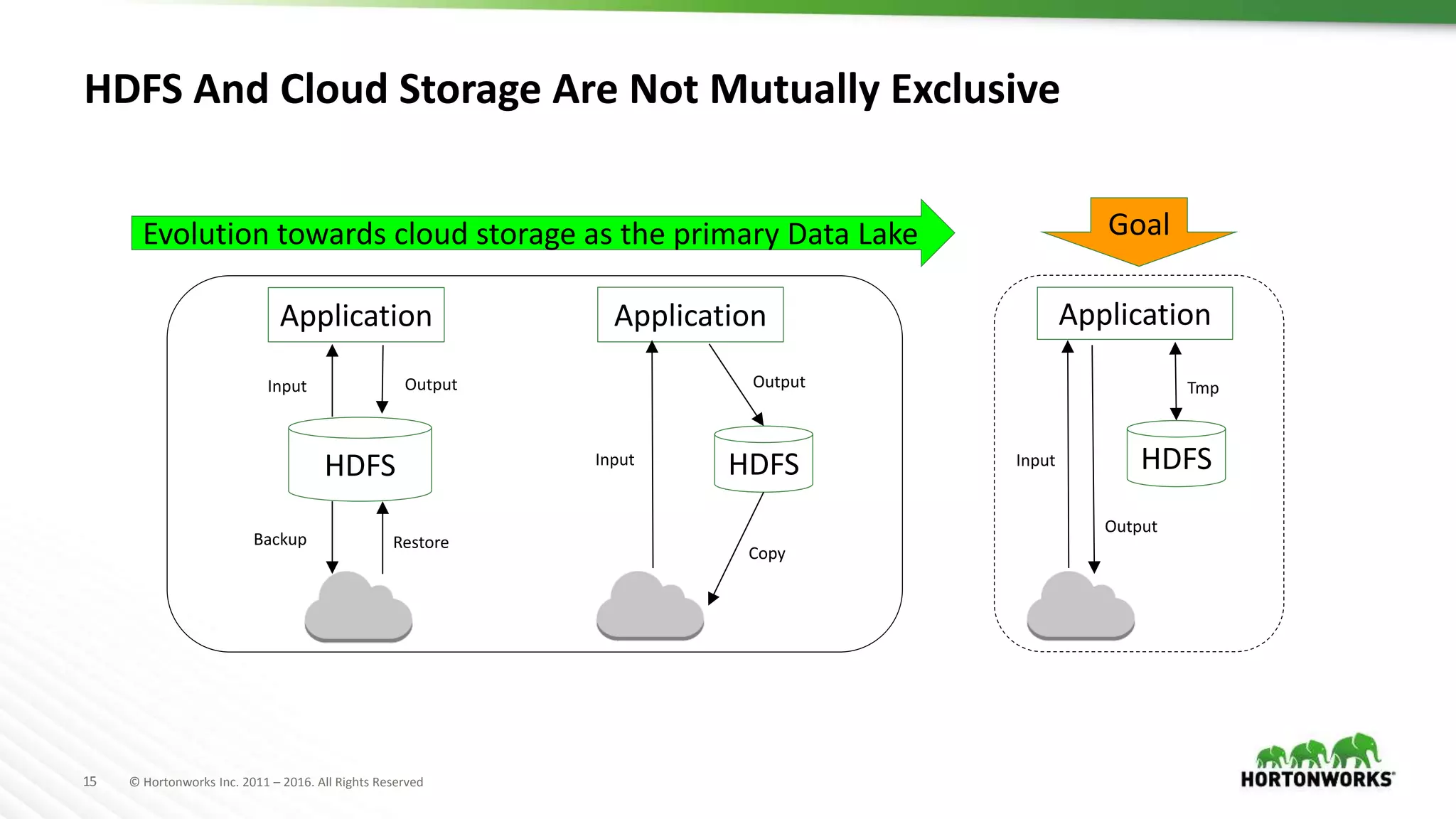
The document discusses the implementation of Hadoop in cloud environments, highlighting various use cases and scenarios, as well as challenges faced during deployment. Key tools like Cloudbreak are introduced for managing Hadoop clusters across different cloud platforms while emphasizing lessons learned regarding performance and storage options. The presentation also addresses practical issues related to cloud storage consistency, particularly when integrating with Hadoop applications.






































































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





