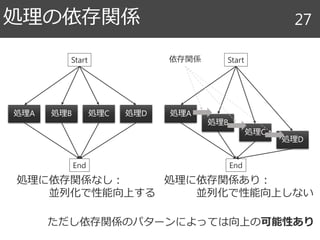
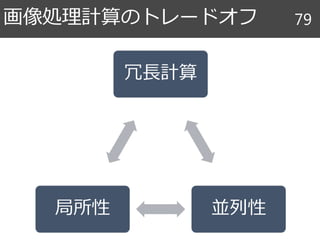
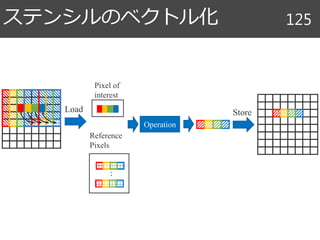
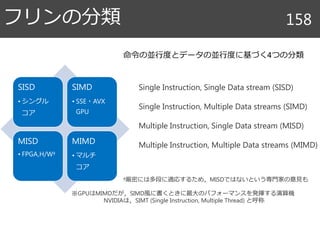
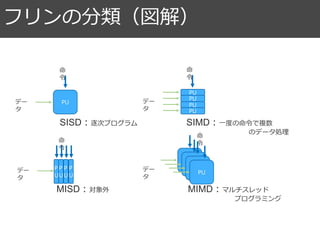
アルゴリズムとスケジュール 86
Buffer<uint8_t> boxFilter3x3(Buffer<uint8_t>&src)
{
//変数宣言
Func in = BoundaryConditions::repeat_edge(src);
Func src16, blurx, blury;
Var x, y, c, xi, yi;
//アルゴリズム記述部
src16(x,y,c) = cast<uint16_t>(in(x,y,c));
blurx(x, y, c) = (src16(x - 1, y, c) + src16(x, y, c) + src16(x + 1, y, c)) / 3;
blury(x, y, c) = saturating_cast<uint8_t>((blurx(x, y - 1, c) + blurx(x, y, c) +
blurx(x, y + 1, c)) / 3);
//スケジュール記述部
blury.tile(x, y, xi, yi, 256, 32).vectorize(xi, 8).parallel(y);
blurx.compute_at(blury, x).store_at(blury, x).vectorize(x, 8);
Buffer<uint8_t> ret = blury.realize(src.width(), src.height(), src.channels());
return ret;
}
Jonathan Ragan-Kelley,Andrew Adams, Sylvain Paris, Marc Levoy, Saman Amarasinghe, Fredo Durand, “Decoupling Algorithms from
Schedules for Easy Optimization of Image Processing Pipelines,” ACM Trans. on Graphics (SIGGRAPH), 2012.
「Halideの提案1」
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Fredo Durand, Saman Amarasinghe, “Halide: A Language and
Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines,” Proc. PLDI 2013.
「Halideの提案2」
Jonathan Ragan-Kelley, “Decoupling Algorithms from the Organization of Computation for High Performance Image Processing:
The design and implementation of the Halide language and compiler,” Ph.D. dissertation, MIT, May 2014.
「上をまとめた博士論文」
Gaurav Chaurasia, Jonathan Ragan-Kelley, Sylvain Paris, George Drettakis, Fredo Durand, “Compiling High Performance Recursive
Filters,” Proc. High-Performance Graphics (HPG), Pages 85-94, 2015.
「Halideのリカーシブフィルタ機能」
Ravi Teja Mullapudi Andrew Adams, Dillon Sharlet, Jonathan Ragan-Kelley, Kayvon Fatahalian, “Automatically Scheduling Halide
Image Processing Pipelines,” ACM Trans. on Graphics (SIGGRAPH), 2016.
「スケジューラの自動最適化」
Liming Lou, Paul Nguyen, Jason Lawrence, Connelly Barnes, “Image Perforation: Automatically Accelerating Image Pipelines by
Intelligently Skipping Samples,” ACM Trans. on Graphics (SIGGRAPH), 2016.
「サブサンプリングベースの画像高速化のHalide実装」
Shih-Wei Liao, Sheng-Jun Tsai, Chieh-Hsun Yang , Chen-Kang Lo “Locality-aware scheduling for stencil code in Halide,”International
Conference on Parallel Processing Workshops, 2016.
「ステンシル計算向けスケジューラ」
Felix Heide, Steven Diamond, Jonathan Ragan-Kelley, Matthias Niesner, Wolfgang Heidrich, Gordon Wetzstein, “ProxImaL: Efficient
Image Optimization using Proximal Algorithms,” ACM Trans. on Graphics (SIGGRAPH), 2016.
「最適化アルゴリズムのためのDSL.Halideがベース」
Patricia Suriana, Andrew Adams, Shoaib Kamil, “Parallel Associative Reductions in Halide,” Proc. International Symposium on Code
Generation and Optimization,2017
「リダクションの並列化」
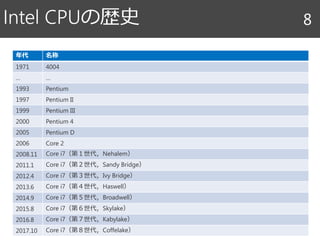
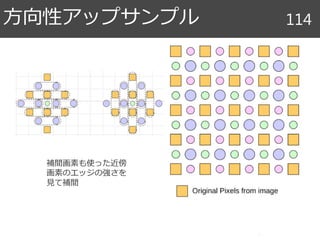
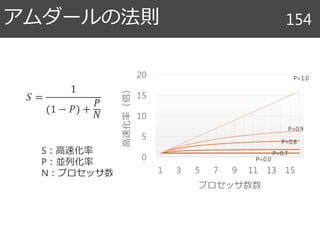
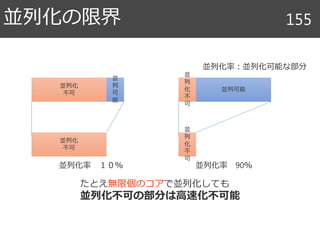
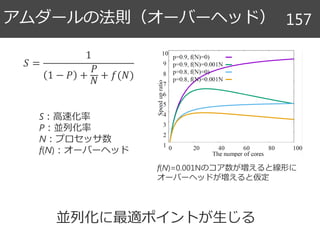
Halide関連文献 90
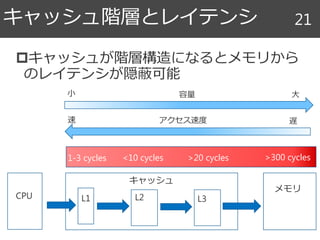
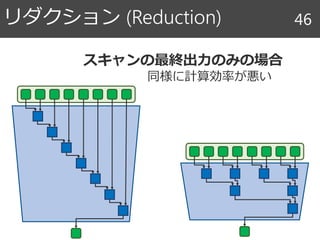
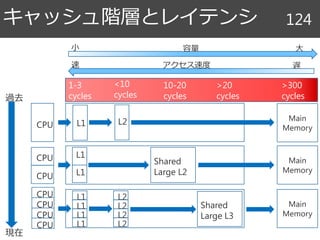
キャッシュ階層とレイテンシ 124
CPU L1L2
1-3
cycles
<10
cycles
>20
cycles
10-20
cycles過去
現在
CPU Shared
Large L2CPU
L1
L1
CPU
CPU
CPU
CPU
L1
L1
L1
L1
L2
L2
L2
L2
Shared
Large L3
Main
Memory
Main
Memory
Main
Memory
>300
cycles
容量小 大
アクセス速度速 遅
行列積(MATMUL) 140
for (i=0;i<N; i++)
for (j=0; j<N; j++)
for (k=0; k<N; k++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
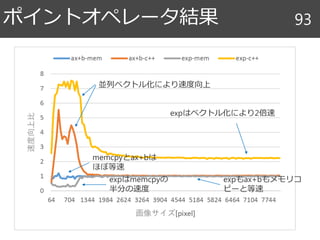
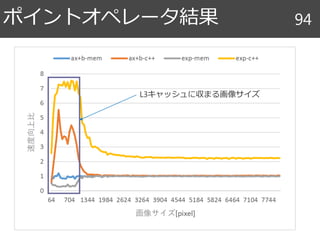
k
k
縦方向のアクセスはキャッシュが
うまく使えていない
N2のデータに対してO(N3)
141.
行列積(MATMUL) 141
for (j=0;j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
k
ループ順序の入れ替え
i
142.
行列積(MATMUL) 142
for (j=0;j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
k+1
ループ順序の入れ替え
i
143.
A
行列積(MATMUL) 143
for (j=0;j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C B= ×
i
j
k+n
ループ順序の入れ替え
i
144.
行列積(MATMUL) 144
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
145.
行列積(MATMUL) 145
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
146.
行列積(MATMUL) 146
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
147.
行列積(MATMUL) 147
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
148.
行列積(MATMUL) 148
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
149.
行列積(MATMUL) 149
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
150.
行列積(MATMUL) 150
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
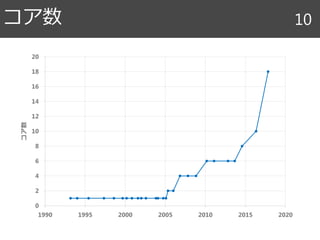
この領域が繰り返し処理される
→最も変動する場所が局所化
→近いキャッシュに乗ったまま処理可能
151.
行列積(MATMUL) 151
C AB= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
残った領域もブロックで処理









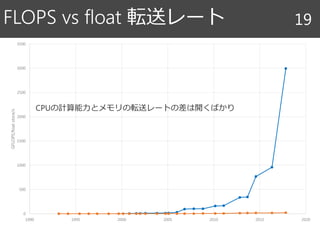
![クロック数 9
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
1990 1995 2000 2005 2010 2015 2020
クロック数[GHz]
ターボ
ブースト
Core iシリーズ
Pentium 4
Extreme
Pentium Extreme
(デュアルコア)
Core 2 Extreme
(クアッドコア)
Pentium
ハイパー
スレッディング](https://image.slidesharecdn.com/random-171130232630/85/slide-9-320.jpg)





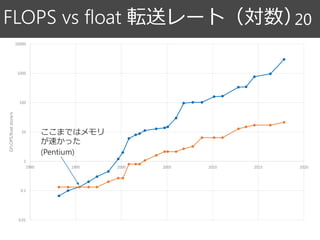
![メモリ帯域 18
0
10
20
30
40
50
60
70
80
90
1995 2000 2005 2010 2015 2020
GB/s
バンド幅 [GB/S]](https://image.slidesharecdn.com/random-171130232630/85/slide-18-320.jpg)
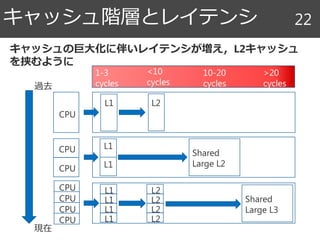
![ラストレベルキャッシュ 23
0
5
10
15
20
25
30
1990 1995 2000 2005 2010 2015 2020
LLCサイズ[MB]
L1キャッシュ L2キャッシュ L3キャッシュ](https://image.slidesharecdn.com/random-171130232630/85/slide-23-320.jpg)


















![ルーフラインモデル 57
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
演算能力の理論上限
(1493.31GFLOPS) 28.56
天井はマシンの
理論演算能力
マシンの
理論演算強度
プログラムの演算強度
と実パフォーマンス
途中まではメモリの
帯域でバウンド
メモリの転送が
間に合わない
flopsとB/Fでプログラムを解析するモデル
由来:理論FLOPSで屋根の様に天井がクリップされるから](https://image.slidesharecdn.com/random-171130232630/85/slide-57-320.jpg)

![ルーフラインモデル 59
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
演算能力の理論上限
(1493.31GFLOPS)
28.56
プログラムを天井に近づけるように最適化
マシンの理論演算強度
プログラムの演算強度
と実パフォーマンス
メモリ最適化
並列化
ベクトル化](https://image.slidesharecdn.com/random-171130232630/85/slide-59-320.jpg)
![ルーフラインモデル 60
メモリ最適化
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
演算能力の理論上限
(1493.31GFLOPS)
28.560.50 1.26 9.57
プログラムを天井に近づけるように最適化
マシンの理論演算強度
各メモリ帯域の上限
高演算
強度処理
並列化
ベクトル化
並列化
ベクトル化
低演算
強度処理
メモリアクセスで
バウンド
理論値まで
高速化](https://image.slidesharecdn.com/random-171130232630/85/slide-60-320.jpg)
![ルーフラインモデル 61
メモリ最適化
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
演算能力の理論上限
(1493.31GFLOPS)
28.560.50 1.26 9.57
プログラムを天井に近づけるように最適化
マシンの理論演算強度
各メモリ帯域の上限
並列化
ベクトル化
低演算
強度処理
メモリアクセスで
バウンド
中演算
強度処理
メモリ最適化
並列化
ベクトル化
パフォーマンスが下がる
アルゴリズムに変更して
でも演算強度を上げる](https://image.slidesharecdn.com/random-171130232630/85/slide-61-320.jpg)
![ルーフラインモデル 62
メモリ最適化
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
演算能力の理論上限
(1493.31GFLOPS)
28.560.50 1.26 9.57
プログラムを天井に近づけるように最適化
マシンの理論演算強度
各メモリ帯域の上限
高演算
強度処理
並列化
ベクトル化
並列化
ベクトル化
低演算
強度処理
メモリアクセスで
バウンド
理論値まで
高速化
中演算
強度処理
メモリ最適化
並列化
ベクトル化
パフォーマンスが下がる
アルゴリズムに変更して
でも演算強度を上げる](https://image.slidesharecdn.com/random-171130232630/85/slide-62-320.jpg)



























![ルーフラインによる解析 95
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
画像サイズが小さいとき
並列化
ベクトル化](https://image.slidesharecdn.com/random-171130232630/85/slide-95-320.jpg)
![ルーフラインによる解析 96
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
画像サイズが大きいとき:メモリでバウンド
並列化
ベクトル化](https://image.slidesharecdn.com/random-171130232630/85/slide-96-320.jpg)


![J,I:出力画像,入力画像
width:画像の横幅,height:画像の縦幅,
rj:フィルタカーネルの縦幅,ri:フィルタカーネルの横幅
ss:空間ガウスシグマ,sr:レンジガウスシグマ
For(j=0; j<height; j++)
For(i=0; i<width; i++)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i]=exp((kj+ji)2/-2ss) exp((I[j+kj][i+ki]- I[j][i])2/-2sr) I[j+kj][i+ki];
FIRフィルタのベクトル化 99](https://image.slidesharecdn.com/random-171130232630/85/slide-99-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=exp((kj+ji)2/-2ss) exp((I[j+kj][i+ki+0]- I[j][i+0])2/-2sr) I[j+kj][i+ki+0];
J[j][i+1]=exp((kj+ji)2/-2ss) exp((I[j+kj][i+ki+1]- I[j][i+1])2/-2sr) I[j+kj][i+ki+1];
J[j][i+2]=exp((kj+ji)2/-2ss) exp((I[j+kj][i+ki+2]- I[j][i+2])2/-2sr) I[j+kj][i+ki+2];
J[j][i+3]=exp((kj+ji)2/-2ss) exp((I[j+kj][i+ki+3]- I[j][i+3])2/-2sr) I[j+kj][i+ki+3];
FIRフィルタのベクトル化 100
画素操作のx座標をループアンローリングしてベクトル長4でベクトル化
同時
計算](https://image.slidesharecdn.com/random-171130232630/85/slide-100-320.jpg)

![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=EXP(|kj+ji|) exp((I[j+kj][i+ki+0]- I[j][i+0])2/-2sr) I[j+kj][i+ki+0];
J[j][i+1]=EXP(|kj+ji|) exp((I[j+kj][i+ki+1]- I[j][i+1])2/-2sr) I[j+kj][i+ki+1];
J[j][i+2]=EXP(|kj+ji|) exp((I[j+kj][i+ki+2]- I[j][i+2])2/-2sr) I[j+kj][i+ki+2];
J[j][i+3]=EXP(|kj+ji|) exp((I[j+kj][i+ki+3]- I[j][i+3])2/-2sr) I[j+kj][i+ki+3];
テーブル参照とベクトル化 102
空間ガウスをテーブル化.スカラで位置の絶対値を計算しテーブル引き後,ベ
クトルに単一の値を代入
空間ガウスはカーネルの位置kj,kiだけに依存し,通常画像よりも大きくない
画素位置ごとのテーブルが計算自体いらない
同時
計算](https://image.slidesharecdn.com/random-171130232630/85/slide-102-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=GS[kj][ji]exp((I[j+kj][i+ki+0]- I[j][i+0])2/-2sr) I[j+kj][i+ki+0];
J[j][i+1]=GS[kj][ji]exp((I[j+kj][i+ki+1]- I[j][i+1])2/-2sr) I[j+kj][i+ki+1];
J[j][i+2]=GS[kj][ji]exp((I[j+kj][i+ki+2]- I[j][i+2])2/-2sr) I[j+kj][i+ki+2];
J[j][i+3]=GS[kj][ji]exp((I[j+kj][i+ki+3]- I[j][i+3])2/-2sr) I[j+kj][i+ki+3];
テーブル参照とベクトル化 103
テーブル引きした同一
の値を入れるだけ
画素の差分とexp計算](https://image.slidesharecdn.com/random-171130232630/85/slide-103-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=GS[kj][ji]exp((D[j+kj][i+ki+0])2/-2sr) I[j+kj][i+ki+0];
J[j][i+1]=GS[kj][ji]exp((D[j+kj][i+ki+1])2/-2sr) I[j+kj][i+ki+1];
J[j][i+2]=GS[kj][ji]exp((D[j+kj][i+ki+2])2/-2sr) I[j+kj][i+ki+2];
J[j][i+3]=GS[kj][ji]exp((D[j+kj][i+ki+3])2/-2sr) I[j+kj][i+ki+3];
テーブル参照とベクトル化 104
テーブル引きした同一
の値を入れるだけ
差分をDとして表現
差分自体はベクトル計算可能](https://image.slidesharecdn.com/random-171130232630/85/slide-104-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=GS[kj][ji]EXP(|D[j+kj][i+ki+0]|) I[j+kj][i+ki+0];
J[j][i+1]=GS[kj][ji]EXP(|D[j+kj][i+ki+1]|) I[j+kj][i+ki+1];
J[j][i+2]=GS[kj][ji]EXP(|D[j+kj][i+ki+2]|) I[j+kj][i+ki+2];
J[j][i+3]=GS[kj][ji]EXP(|D[j+kj][i+ki+3]|) I[j+kj][i+ki+3];
テーブル参照とベクトル化 105
テーブル引きした同一
の値を入れるだけ
差分の絶対値でテーブル参照](https://image.slidesharecdn.com/random-171130232630/85/slide-105-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=GS[kj][ji]EXP(|DR1|) EXP(|DG1|) EXP(|DB1|) I[j+kj][i+ki+0];
J[j][i+1]=GS[kj][ji]EXP(|DR2|) EXP(|DG2|) EXP(|DB2|) I[j+kj][i+ki+1];
J[j][i+2]=GS[kj][ji]EXP(|DR3|) EXP(|DG3|) EXP(|DB3|) I[j+kj][i+ki+2];
J[j][i+3]=GS[kj][ji]EXP(|DR4|) EXP(|DG4|) EXP(|DB4|) I[j+kj][i+ki+3];
テーブル参照とベクトル化(カラーの場合)107
テーブル引きした同一
の値を入れるだけ
差分の絶対値でテーブル参照3回
必要
カラーのdiffはDR1~4, DG1
~4,DB1~4と省略して記述](https://image.slidesharecdn.com/random-171130232630/85/slide-107-320.jpg)
![For(j=0; j<height; j++)
For(i=0; i<width; i+=4)
For(kj=-rj; kj<rj; kj++)
For(ki=-ri; ki<ri; ki++)
J[j][i+0]=GS[kj][ji]EXP(|DRGB1|) I[j+kj][i+ki+0];
J[j][i+1]=GS[kj][ji]EXP(|DRGB2|) I[j+kj][i+ki+1];
J[j][i+2]=GS[kj][ji]EXP(|DRGB3|) I[j+kj][i+ki+2];
J[j][i+3]=GS[kj][ji]EXP(|DRGB4|) I[j+kj][i+ki+3];
テーブル参照とベクトル化(カラーの場合)108
テーブル引きした同一
の値を入れるだけ
L2ノルムの量子化値の絶対値でテーブル参照1回
DRGB=round( 𝑅2 + 𝐺2 + 𝐵2)
ルートの計算はベクトル演算可能
diffはDRGB1~4と省略して記述](https://image.slidesharecdn.com/random-171130232630/85/slide-108-320.jpg)










![BF
Time[ms]
3970X 4960X 5960X 6950X
Year
0
100
200
300
400
500
600
700
2012 2013 2014 2015 2016 2017
SSE EXP
SSE LUT set
SSE Quantization LUT set
AVX EXP
AVX LUT set
AVX LUT gather
AVX Quantization LUT set](https://image.slidesharecdn.com/random-171130232630/85/slide-127-320.jpg)
![BF: SSE
Time[ms]
3970X 4960X 5960X 6950X
Year
0
100
200
300
400
500
600
700
2012 2013 2014 2015 2016 2017
SSE EXP
SSE LUT set
SSE Quantization LUT set](https://image.slidesharecdn.com/random-171130232630/85/slide-128-320.jpg)
![BF: AVX/AVX2
Time[ms]
3970X 4960X 5960X 6950X
Year
0
50
100
150
200
250
300
350
400
450
2012 2013 2014 2015 2016 2017
AVX EXP
AVX LUT set
AVX LUT gather
AVX Quantization LUT set
AVX Quantization LUT gather
AVX2 with FMA3 EXP
AVX2 with FMA3 LUT set](https://image.slidesharecdn.com/random-171130232630/85/slide-129-320.jpg)
![BF: EXP
Time[ms]
3970X 4960X 5960X 6950X
Year
0
100
200
300
400
500
600
700
2012 2013 2014 2015 2016 2017
SSE EXP
AVX EXP
AVX2 with FMA3 EXP](https://image.slidesharecdn.com/random-171130232630/85/slide-130-320.jpg)
![BF: LUT
Time[ms]
3970X 4960X 5960X 6950X
Year
0
50
100
150
200
250
300
2012 2013 2014 2015 2016 2017
SSE LUT set
AVX LUT set
AVX LUT gather
AVX2 with FMA3 LUT set
AVX2 with FMA3 LUT gather](https://image.slidesharecdn.com/random-171130232630/85/slide-131-320.jpg)
![BF: Quantization LUT
Time[ms]
3970X 4960X 5960X 6950X
Year
0
50
100
150
200
250
300
2012 2013 2014 2015 2016 2017
SSE Quantization LUT set
AVX Quantization LUT set
AVX Quantization LUT gather
AVX2 with FMA3 Quantization
LUT set
AVX2 with FMA3 Quantization
LUT gather](https://image.slidesharecdn.com/random-171130232630/85/slide-132-320.jpg)
![0
100
200
300
400
500
600
700
800
2012 2013 2014 2015 2016 2017
SSE EXP
SSE LUT set
SSE Quantization LUT set
AVX EXP
AVX LUT set
AVX LUT gather
AVX Quantization LUT set
AVX Quantization LUT gather
AVX2 with FMA3 EXP
NLMF
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-133-320.jpg)
![0
100
200
300
400
500
600
700
800
2012 2013 2014 2015 2016 2017
SSE EXP
SSE LUT set
SSE Quantization LUT set
NLMF: SSE
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-134-320.jpg)
![0
100
200
300
400
500
600
700
2012 2013 2014 2015 2016 2017
AVX EXP
AVX LUT set
AVX LUT gather
AVX Quantization LUT set
AVX Quantization LUT gather
AVX2 with FMA3 EXP
AVX2 with FMA3 LUT set
AVX2 with FMA3 LUT gather
AVX2 with FMA3 Quantization LUT
set
NLMF: AVX/AVX2
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-135-320.jpg)
![0
100
200
300
400
500
600
700
800
2012 2013 2014 2015 2016 2017
SSE EXP
AVX EXP
AVX2 with FMA3 EXP
NLMF: EXP
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-136-320.jpg)
![0
100
200
300
400
500
600
2012 2013 2014 2015 2016 2017
SSE LUT set
AVX LUT set
AVX LUT gather
AVX2 with FMA3 LUT set
AVX2 with FMA3 LUT gather
NLMF: LUT
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-137-320.jpg)
![0
100
200
300
400
500
600
2012 2013 2014 2015 2016 2017
SSE Quantization LUT set
AVX Quantization LUT set
AVX Quantization LUT gather
AVX2 with FMA3 Quantization LUT
set
AVX2 with FMA3 Quantization LUT
gather
NLMF: Quantization LUT
Time[ms]
3970X 4960X 5960X 6950X
Year](https://image.slidesharecdn.com/random-171130232630/85/slide-138-320.jpg)

![行列積(MATMUL) 140
for (i=0; i<N; i++)
for (j=0; j<N; j++)
for (k=0; k<N; k++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
k
k
縦方向のアクセスはキャッシュが
うまく使えていない
N2のデータに対してO(N3)](https://image.slidesharecdn.com/random-171130232630/85/slide-140-320.jpg)
![行列積(MATMUL) 141
for (j=0; j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
k
ループ順序の入れ替え
i](https://image.slidesharecdn.com/random-171130232630/85/slide-141-320.jpg)
![行列積(MATMUL) 142
for (j=0; j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C A B= ×
i
j
k+1
ループ順序の入れ替え
i](https://image.slidesharecdn.com/random-171130232630/85/slide-142-320.jpg)
![A
行列積(MATMUL) 143
for (j=0; j<N; j++)
for (k=0; k<N; k++)
for (i=0; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
C B= ×
i
j
k+n
ループ順序の入れ替え
i](https://image.slidesharecdn.com/random-171130232630/85/slide-143-320.jpg)
![行列積(MATMUL) 144
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-144-320.jpg)
![行列積(MATMUL) 145
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-145-320.jpg)
![行列積(MATMUL) 146
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-146-320.jpg)
![行列積(MATMUL) 147
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-147-320.jpg)
![行列積(MATMUL) 148
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-148-320.jpg)
![行列積(MATMUL) 149
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B](https://image.slidesharecdn.com/random-171130232630/85/slide-149-320.jpg)
![行列積(MATMUL) 150
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
この領域が繰り返し処理される
→最も変動する場所が局所化
→近いキャッシュに乗ったまま処理可能](https://image.slidesharecdn.com/random-171130232630/85/slide-150-320.jpg)
![行列積(MATMUL) 151
C A B= ×
i
j
k
タイリング
i
for (j=0; j<N; j++)
for (k=0; k<N/2; k++)
for (i=0; i<N/2; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=0; k<N/2; k++)
for (i= N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
for (k=N/2; k<N; k++)
for (i=N/2; i<N; i++)
C[j][i] += A[j][k] * B[k][i]; // C = A x B
残った領域もブロックで処理](https://image.slidesharecdn.com/random-171130232630/85/slide-151-320.jpg)




![OpenMPによる並列化:加算 162
void add(uchar* a, uchar* b, uchar* dest, int num)
{
for(int i=0;i<num;i++)
{
dest[i] = a[i] + b[i];
}
}
void add_omp (uchar* a, uchar* b, uchar* dest, int num)
{
#pragma omp parallel for
for(int i=0;i<num;i++)
{
dest[i] = a[i] + b[i];
}
}
#pragma omp parallel for
この一行を追加するだけでforループが並列化される
pthreadで書くとこの5倍はプログラムが長くなる](https://image.slidesharecdn.com/random-171130232630/85/slide-162-320.jpg)

![ベクトル並列化プログラム 165
void boxfilter(float* src, float* dest, int w, int h, int r)
{
for(int j=r;j<h-r;j++)
{
float normalize = 1.0f/(float)((2*r+1)*(2*r+1));
for(int i=r;i<w-r;i+=4)
{
float msum = 0.f;
for(int l=-r;l<=r;l++)
{
for(int k=-r;k<=r;k++)
{
msum += src [w*(j+l)+i+l];
}
}
dest[w*j+i]=msum*normalize;
}
}
}](https://image.slidesharecdn.com/random-171130232630/85/slide-165-320.jpg)






![時間局所性が高いた
めL2キャッシュで律
速しやすい
並列化,ベクトル化
が有効に働く
BFのルーフライン解析 173
演算強度 [flop/byte]
パフォーマンス[GFLOPS]
10-3 10210110010-110-2
10-2
104
103
102
101
100
10-1
並列化
ベクトル化](https://image.slidesharecdn.com/random-171130232630/85/slide-173-320.jpg)






















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)





























