References
• D. Hafner,T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent
dynamics for planning from pixels. In International Conference on Machine Learning
(ICML), 2019.
• A. X. Lee, A. Nagabandi, P. Abbeel, S. Levine. Stochastic Latent Actor-Critic: Deep
Reinforcement Learning with a Latent Variable Model, arxiv, 2019.
• Levine, S. and Abbeel, P. Learning neural network policies with guided policy search
under unknown dynamics. In NIPS, 2014.
• Johnson, M., Duvenaud, D., Wiltschko, A., Datta, S., and Adams, R. Composing graphical
models with neural networks for structured representations and fast inference. In NIPS,
2016.
• Watter, M., Springenberg, J., Boedecker, J., and Riedmiller, M. Embed to control: A locally
linear latent dynamics model for control from raw images. In NIPS, 2015
• M. Karl, M. Soelch, J. Bayer, and P. van der Smagt. Deep variational bayes filters: Unsuper-
vised learning of state space models from raw data. In Proceedings of ICLR, 2017.
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Solar: Deep structured latent representations for
model-based reinforcement learning
Presentater: Kei Akuzawa, Matsuo Lab. D1](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Solar: Deep structured latent representations for
model-based reinforcement learning
Presentater: Kei Akuzawa, Matsuo Lab. D1](https://image.slidesharecdn.com/20190816-190816001737/75/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-1-2048.jpg)



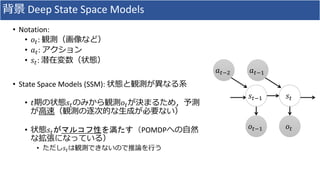
![背景 Deep State Space Models
• 学習:
• Amortized Inference (VAEと同様入力データで条件づけられた推論モデル)
を用いることが多い
• 生成モデル:
• 𝑝 𝑜1:𝑇|𝑎1:𝑇 = 𝑡=1
𝑇
𝑝 𝑜𝑡 𝑠𝑡 𝑝 𝑠𝑡 𝑠𝑡−1, 𝑎 𝑡−1 𝑑𝑠1:𝑇
• 推論モデル:
• 𝑞 𝑠1:𝑇|𝑜1:𝑇, 𝑎1:𝑇 = 𝑡=1
𝑇
𝑞 𝑠𝑡|𝑜1:𝑇. 𝑎 𝑡
• ELBO:
• 𝐸 𝑞 𝑠1:𝑇|𝑜1:𝑇,𝑎1:𝑇
log 𝑝 𝑜1:𝑇|𝑠1:𝑇 − 𝐷 𝐾𝐿[𝑞 𝑠𝑡|𝑜1:𝑇, 𝑎1:𝑇 |𝑝 𝑠𝑡 𝑠𝑡−1, 𝑎 𝑡−1 ]
𝑜𝑡−1
𝑎 𝑡−2
𝑜𝑡
𝑎 𝑡−1
𝑠𝑡−1 𝑠𝑡](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-6-320.jpg)
![[余談] DSSMとそのRLにおける用途
DSSMのRLにおける用途 DSSM自体の工夫
Solar 最適制御(潜在変数の遷移が線形
となるようなDSSMを採用すること
により,画像観測においても
Linnear-Quadratic Regulator(LQR)
でコントローラーを学習)
潜在空間上の遷移が線形になるよ
うに設計
PlaNet [Hafner+ 2019] プランニング(DSSMの潜在空間上
で高速なプランニングを行う)
長期の予測が行えるような補助タ
スク(overshooting)
SLAC [Lee+2019] 表現学習(DSSMで推論した潜在変
数がマルコフ性を満たすことを利
用して,𝑠𝑡を入力にとるactorを用い
たsoft actor-criticを提案)
方策自体もグラフィカルモデルで
書く(Control as Inference)](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-7-320.jpg)
![背景 Linear Quadratic Regulator
• 線形の時変環境モデル,二次形式のコスト関数が与えられている状況を想定
• for 𝑡 ∈ {1, … , 𝑇}
• 𝑝 𝑠𝑡 𝑠𝑡−1, 𝑎 𝑡−1 = 𝑁 𝑭 𝒕
𝑠𝑡−1
𝑎 𝑡−1
, 𝜮 𝑡
• 𝑝 𝑐𝑡 𝑠𝑡, 𝑎 𝑡 = 𝑁(
1
2
𝑠𝑡
𝑎 𝑡
𝑇
𝐶
𝑠𝑡
𝑎 𝑡
+ 𝑐 𝑇
𝑠𝑡
𝑎 𝑡
)
• コストが最小かつエントロピーが最大になる方策を陽に求めることができる(制
御理論のアルゴリズムが使えて嬉しい)
• 基本GPS[Levin and Abeel 2014]で提案された改善版アルゴリズムと同じっぽい
• (GPSのようにNeural Network PolicyにFittingしているわけではない???)](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-8-320.jpg)

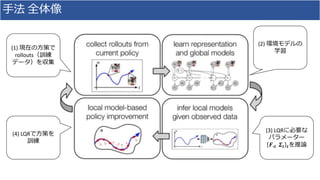


![手法 環境モデルの学習
• ELBO:
• 𝐸 𝑞 𝑠1:𝑇|𝑜1:𝑇
log 𝑝 𝑜1:𝑇|𝑠1:𝑇 −
𝐷 𝐾𝐿 𝑞 𝑠𝑡|𝑜𝑡, 𝑠𝑡−1, 𝑎 𝑡−1, 𝑭, 𝜮 𝑝 𝑠𝑡 𝑠𝑡−1, 𝑎 𝑡−1, 𝑭, 𝜮 − 𝐷 𝐾𝐿[𝑞 𝑭, 𝜮 |𝑝 𝑭, 𝜮 ]
• (基本的にVAEのELBOと同じ)
• あとは, 𝑝 𝑜1:𝑇|𝑠1:𝑇 , 𝜓(𝑠𝑡; 𝑜𝑡, 𝜙), 𝑞 𝑭, 𝜮 のパラメータについてELBOの勾配で学習
• とくに𝑞 𝑭, 𝜮 = 𝑁𝑀𝐼𝑊(𝜓′, 𝜈′, 𝑀0
′
, 𝑉′) に関しては自然勾配が計算できる
• 普通のAmortized Inference, VAEと違いここだけStochastic Variational Inference
• 詳細はJohnson+2016
再構成誤差
近似分布と事前分布のKL項](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-13-320.jpg)
![手法 環境モデルを用いたLQR
• 環境モデルを学習し以下が得られたと想定
• 𝑞∗ 𝑭, 𝜮
• 𝜓∗
𝑠𝑡; 𝑜𝑡, 𝜙
• 𝑝∗ 𝑐𝑡 𝑠𝑡, 𝑎 𝑡 = 𝑁(
1
2
𝑠𝑡
𝑎 𝑡
𝑇
𝐶
𝑠𝑡
𝑎 𝑡
+ 𝑐 𝑇
𝑠𝑡
𝑎 𝑡
)
• コスト関数𝑝∗
𝑐𝑡 𝑠𝑡, 𝑎 𝑡 は持っているので,あとは 𝑭, 𝒕 𝜮 𝒕 𝒕=𝟏,…𝑻がLQRに必要
• ある軌道[𝑜0, 𝑎0, 𝑐0, … , 𝑜 𝑇, 𝑎 𝑇, 𝑐 𝑇]が与えられたとする.𝑝(𝑭 𝒕, 𝜮 𝒕|𝑜1:𝑇, 𝑎1:𝑇)を最も
よく近似する𝑞 𝑭 𝑡, 𝜮 𝒕 を求めたい
• 𝑞∗ 𝑭, 𝜮 を𝑞 𝑭 𝒕, 𝜮 𝒕 の事前分布として用いて(経験ベイズ),ELBOについて
𝑞(𝑠𝑡| … )と𝑞 𝑭 𝒕, 𝜮 𝒕 のEM法を解けば最適な𝑞 𝑭 𝑡, 𝜮 𝒕 が求まる
• ( 最適な𝑞(𝑠𝑡| … )と𝑞 𝑭 𝒕, 𝜮 𝒕 はClosed Formで書ける)](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-14-320.jpg)
![関連研究
• DSSMの遷移モデルの設計が大事
• 特に線形だと制御理論の知見を活かせる,遷移行列のスペクトルが意味を持
つ[Johnson+2016]など,メリットがある
• 他に,線形の遷移モデルを組んでいる研究はあるだろうか?どんな生成/推論モ
デルが好ましいだろうか
• (論文自体で紹介されている関連研究ではなく,発表者から見た関連研究です)](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-15-320.jpg)
![関連研究 E2C
• 「潜在空間上で線形の遷移モデルを学習し,それをLQRに利用する」というコン
セプトの初出
• 定式化がDSSMになっていない => 潜在変数がマルコフ性を満たす保証がない
[PlaNetで指摘]
• 遷移行列のパラメータ𝐴 𝑡は𝐴 𝑡 = ℎ 𝜓
𝑡𝑟𝑎𝑛𝑠
(𝑧𝑡)で求める
• ただし遷移行列𝐴 𝑡はパラメータ数が𝑂(𝑛 𝑟𝑜𝑤 𝑛 𝑐𝑜𝑙)でスケールしないので,実用
上は𝐴 𝑡 = (𝑰 + 𝑣 𝑡 𝑟𝑡
𝑇
)と置いて𝑣 𝑡 𝑧𝑡 , 𝑟𝑡(𝑧𝑡)を求める](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-16-320.jpg)

![関連研究 遷移行列へのInferenceまとめ
直感的 数式的
Solar Stochastic Variational Inference 𝑞∗
𝑭, 𝜮 = 𝑀𝑁𝐼𝑊 𝜓′
, 𝜈′
, 𝑀0
′
, 𝑉′
事後分布𝑞 𝑭 𝒕, 𝜮 𝒕|𝑠1:𝑇, 𝑎1:𝑇 も解析
的に求まる
E2C[Watter+2015] 𝐴 𝑡 = ℎ 𝜓
𝑡𝑟𝑎𝑛𝑠
(𝑧𝑡)として,パラメー
タ𝜓を学習
𝐴 𝑡 = ℎ 𝜓
𝑡𝑟𝑎𝑛𝑠
(𝑧𝑡)
DVBF[Karl+2017] Amortized Inference (データ点非
依存なM個の遷移行列と,デー
タ点依存の重みの線形和)
𝐴 𝑡 =
𝑖=1
𝑀
𝛼 𝑡
(𝑖)
𝐴(𝑖)
,
𝑤ℎ𝑒𝑟𝑒 𝛼 𝑡 = 𝑓𝜓 𝑧𝑡, 𝑢 𝑡
結局どれが良いのかは良くわからないが,なんとなくSolarが使い回しやすそう](https://image.slidesharecdn.com/20190816-190816001737/85/DL-SOLAR-Deep-Structured-Representations-for-Model-Based-Reinforcement-Learning-18-320.jpg)




![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking](https://cdn.slidesharecdn.com/ss_thumbnails/200124dlseminar-200124001212-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]マテリアルズインフォマティクスにおける深層学習の応用](https://cdn.slidesharecdn.com/ss_thumbnails/181207dlwakasugipanasonicver4-181207003725-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20210625robustnetlin-210625020332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Unsupervised Learning of 3D Structure from Images](https://cdn.slidesharecdn.com/ss_thumbnails/sugihara-161213071700-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] Adversarial Skill Chaining for Long-Horizon Robot Manipulation via T...](https://cdn.slidesharecdn.com/ss_thumbnails/211210dlseminarnakamoto-211210051019-thumbnail.jpg?width=640&height=640&fit=bounds)






















