The Marathon 2:A Navigation System
Steve Macenski, Francisco MartÍn, Ruffin White, Jionatan Gins Clavero
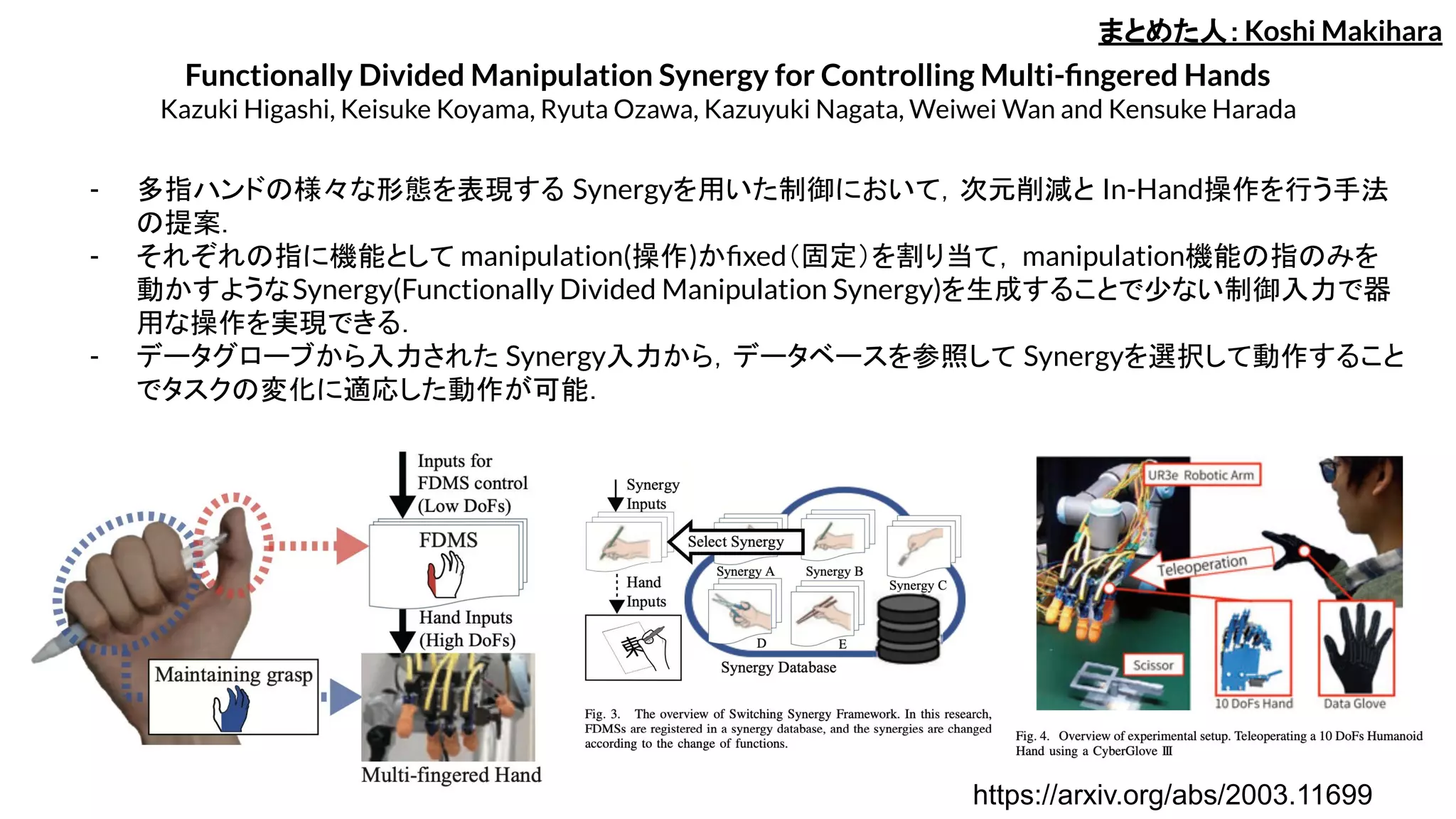
- ROS2 の自律移動ソフトウェア Navigation2 と評価に関する論文
- ROS1 の Navigation1 の枠組みをベースに ROS2への移行と新機能追加が行われている
- アルゴリズム強化として SLAM Toolbox、Spatio-Temporal Voxel Layer (STVL)、layered costmaps,
Timed Elastic Band (TEB) controller, and a multi-sensor fusion framework for state estimation(Robot
Localization)などを新たに採用
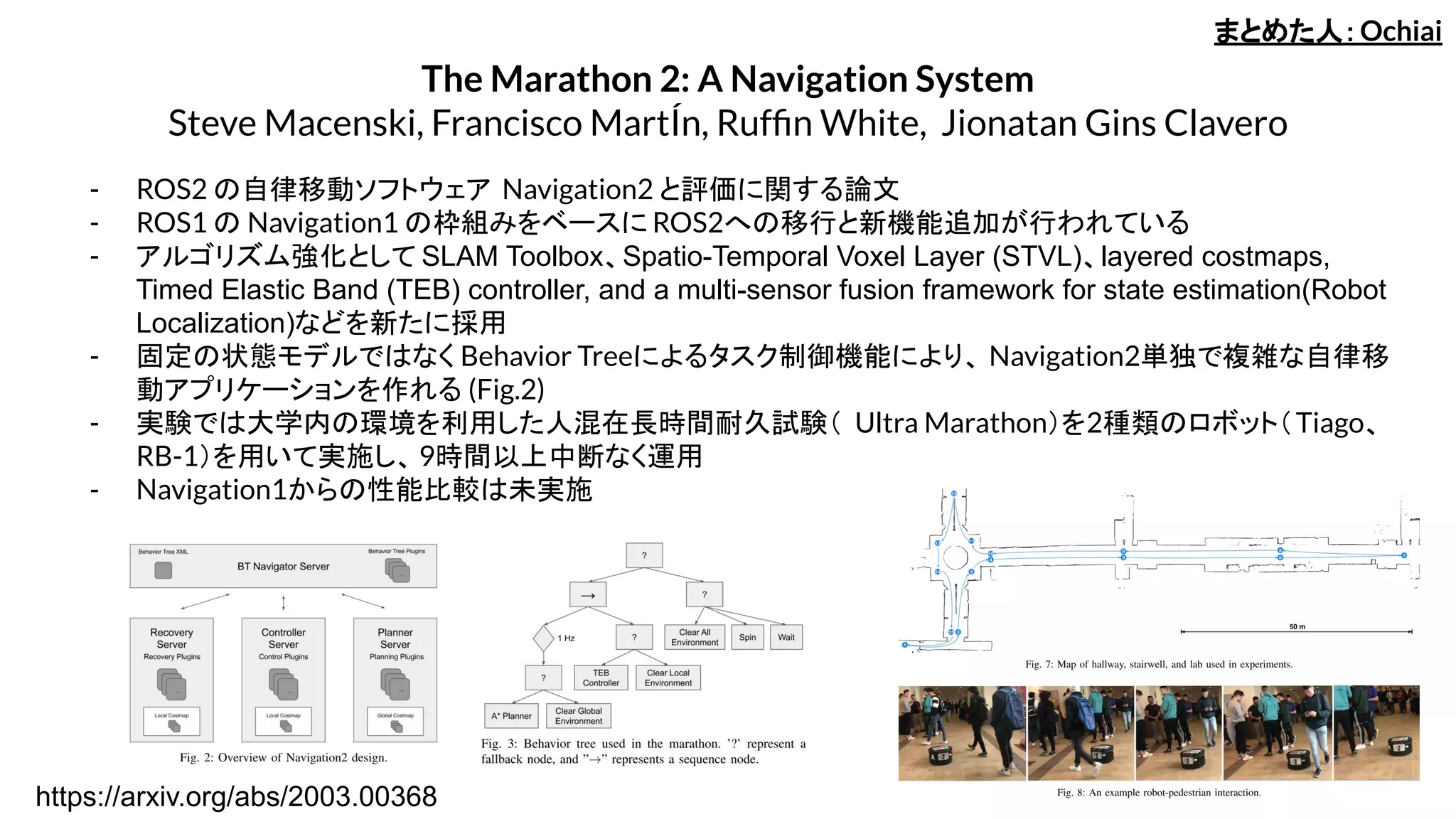
- 固定の状態モデルではなく Behavior Treeによるタスク制御機能により、 Navigation2単独で複雑な自律移
動アプリケーションを作れる (Fig.2)
- 実験では大学内の環境を利用した人混在長時間耐久試験( Ultra Marathon)を2種類のロボット(Tiago、
RB-1)を用いて実施し、9時間以上中断なく運用
- Navigation1からの性能比較は未実施
まとめた人:Ochiai
https://arxiv.org/abs/2003.00368
4.
Neural Manipulation Planningon Constraint Manifolds
Ahmed H. Qureshi, Jiangeng Dong, Austin Choe, and Michael C. Yip
まとめた人:Ochiai
- タスク拘束条件付き動作計画問題を DNNを用いて解くアルゴリズムの提案( Fig.2)
- 著者が過去に提案している MPNetの発展型
- サンプリング型アルゴリズムのヒューリスティックとして DNNを用いることで効率よく C-Spaceと拘束条件の
成す多様体を効率よく探索
- DNNには3D-CNNによる3Dセンター入力と、テキストによるタスク拘束条件記述の特徴空間表現、初期条
件、ゴール条件、現在状態を入力として与える
- 2種類のタスク(キッチン、バーテンダー)についてランダムな物体配置と物体操作シナリオに対する
CBiRRTによる解を生成し教示データとしている
- 従来手法(CBiRRT、TBRRT、AtlasRRT)と比較して一桁違う計算速度を実現( Fig.4、Fig.6)
https://www.researchgate.net/publication/343568163_Neural_Manipulation_Planning_on_Constraint_Manifolds
5.
Dynamically Constrained MotionPlanning Networks for Non-Holonomic Robots
Jacob J. Johnson, Linjun Li, Fei Liu, Ahmed H. Qureshi and Michael C. Yip
まとめた人:Ochiai
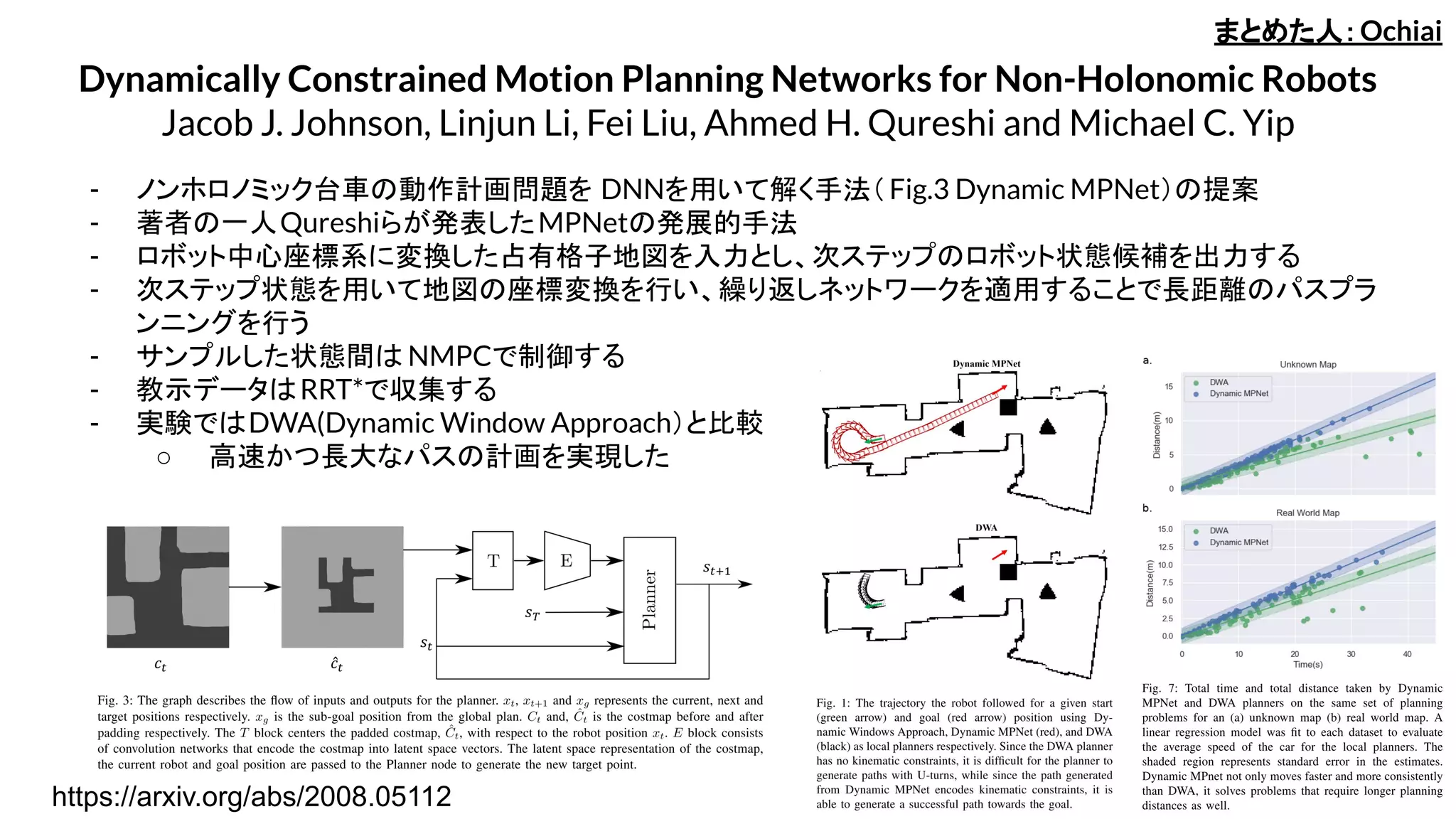
- ノンホロノミック台車の動作計画問題を DNNを用いて解く手法(Fig.3 Dynamic MPNet)の提案
- 著者の一人Qureshiらが発表したMPNetの発展的手法
- ロボット中心座標系に変換した占有格子地図を入力とし、次ステップのロボット状態候補を出力する
- 次ステップ状態を用いて地図の座標変換を行い、繰り返しネットワークを適用することで長距離のパスプラ
ンニングを行う
- サンプルした状態間は NMPCで制御する
- 教示データはRRT*で収集する
- 実験ではDWA(Dynamic Window Approach)と比較
○ 高速かつ長大なパスの計画を実現した
https://arxiv.org/abs/2008.05112
6.
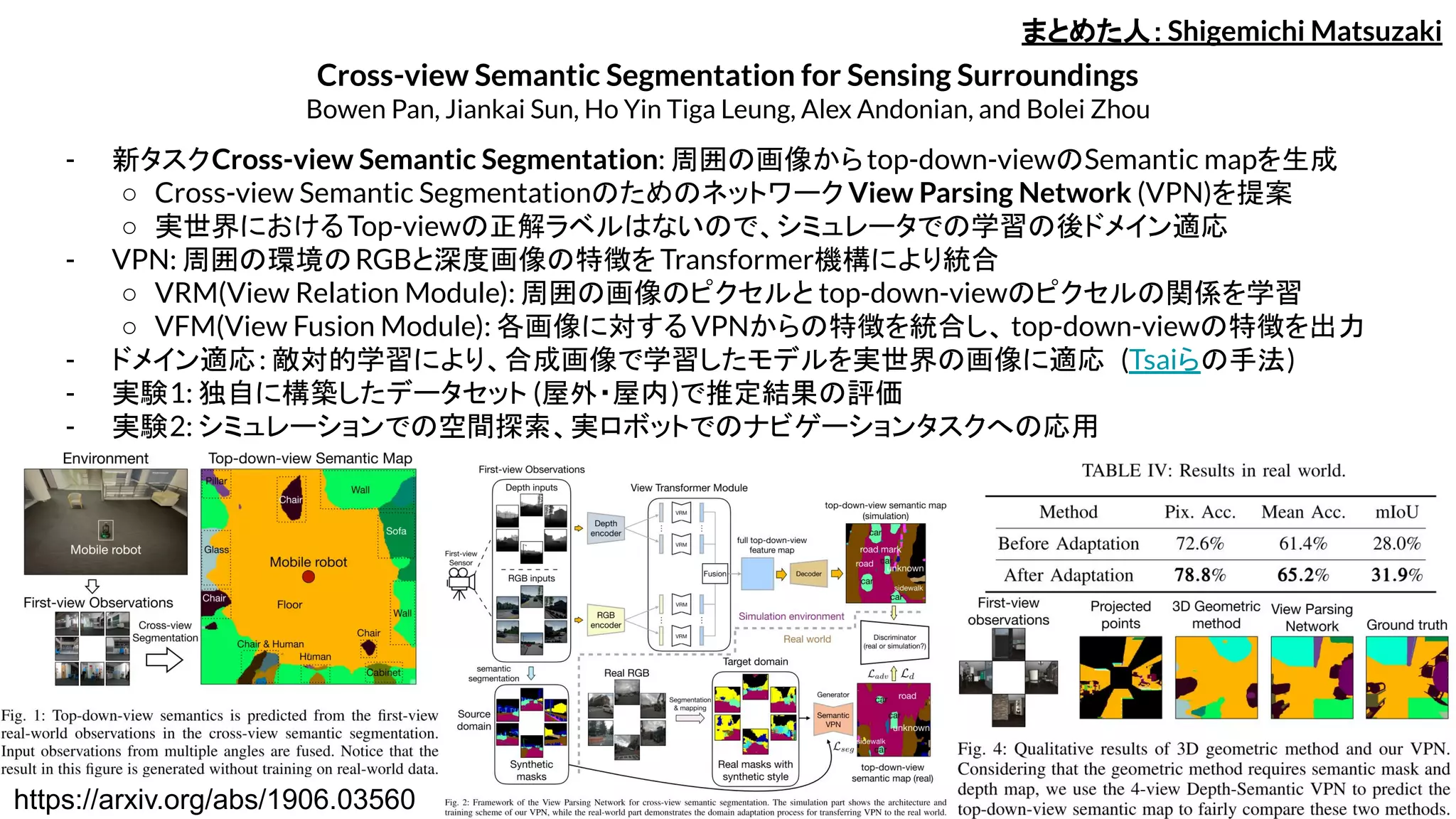
Cloth Region Segmentationfor Robust Grasp Selection
Jianing Qian, Thomas Weng, Luxin Zhang, Brian Okorn, David Held
- 乱雑に置かれた布を並行グリッパでピックするための,把持点を RGBDデータをもとに決定する手法を提案した.
- 取得した点群データから,布のエッジ・コーナを U-Netを利用して,推定(セグメンテーション)を行う.
- エッジ・コーナーが色付けされた布を人間がランダムに操作,その様子からセグメンテーション用のデータセットを作成.
- U-Netがセグメンテーションした出力画像をもとに,把持方向と把持点を算出.このとき,把持点に優先度をつけ,優先度の高い把持点
から把持持動作を行う.
- RANSAC・Canny-Depth・Canny-colorを利用したエッジ・コーナ検出手法と比べて把持成功率を実現した.
まとめた人:Hachimine
https://rss2020vlrrm.github.io/papers/8_CameraReadySubmission_Cloth_Region_Seg
mentation_for_Robust_Grasp_Selection__RSSVLRRM2020_%20(12).pdf
7.
Design and Controlof SLIDER: An Ultra-lightweight, Knee-less,
Low-cost Bipedal Walking Robot
JianingKe Wang, David Marsh, Roni Permana Saputra, Digby Chappell, Zhonghe Jiang, Akshay Raut, Bethany Kon, and Petar Kormushev
- 膝関節を有さない,直動脚を用いる 10DOFの二足歩行ロボットを開発,歩行実験を行った.
- 直動脚は膝関節を有する構成と比較し,重心を低くすることが可能となり,慣性モーメントを減らすことができる.
- CFRPをメインとする直動脚は, BLDCモータとタイミングベルトを利用して直動動作を実現している.
- 腰や足の関節には,3 Dプリンタと,自作のサイクロイド減速機を用いた構成を採用.
- IMUやBLDC用のMDはすべてROS上で動作し,GazeboでOpenHRPのプラグインを使用して歩行シミュレーション環境を構築.
- 歩行制御には, ZMPを採用している.膝関節を有する2足歩行と比較し,重心移動の少ない歩行を実現することが確認できた.
まとめた人:Hachimine
https://kormushev.com/papers/Wang_IROS-2020.pdf
8.
Exploiting Visual-outer Shapefor Tactile-inner Shape Estimation of
Objects Covered with Soft Materials
Tomoya Miyamoto, Hikaru Sasaki, and Takamitsu Matsubara
- 衣類などの柔軟な素材で覆われ,視覚情報のみでは形状を推定することができない対象物体に対して, RGBDとアクティブタッチを利
用した形状の推定方法を提案.
- GPIS(Gaussoam Process implicit surface)をポイントクラウドベースに拡張.
- 接触センサのみを利用したアクティブタッチと比較して,視覚情報を追加することで,より効率的に形状を推定することが可能となった.
- RGBDデータから,active touchするべき点を算出,その後 GPISを用いて,RGBベースから算出した物体形状と接触センサを利用した
物体形状との類似度を計算する .
まとめた人:Hachimine
https://www.researchgate.net/publication/343447024_Exploiting_Visual-Outer_Shape_f
or_Tactile-Inner_Shape_Estimation_of_Objects_Covered_with_Soft_Materials
9.
Model-Free, Vision-Based ObjectIdentification and Contact Force
Estimation with a Hyper-Adaptive Robotic Grippers
- 独立してスライド動作を行うピンを指先に持つグリッパを利用し,把持した際のピンの移動量をもとに対象物体の識別・接触面の反力を
推定するシステムを提案.
- ピンの移動量は,カメラを用いて撮影.撮影した画像から取得した移動量をもとに,教示なし学習である random forestを用いて,把持
対象物体の分類を行う.
- 接触面の反力推定には,ピンに加わる力とピンの移動量を 3次関数として定式化したものや, CNNを用いたもの,random forestを使用
するものなど復習の手法を実験し比較. CNNを用いたものが最も精度が高かった.
- 評価にはYCBデータセット中の12種類を使用.
Waris Hasan, Lucas Gerez, and Minas Liarokapis
まとめた人:Hachimine
https://www.researchgate.net/publication/343361683_Model-Free_Vision-Based_Object_Identific
ation_and_Contact_Force_Estimation_with_a_Hyper-Adaptive_Robotic_Gripper
10.
Active 6D Multi-ObjectPose Estimation in Cluttered Scenarios with
Deep Reinforcement Learning
- 深層強化学習のフレームワークを用いたアクティブカメラによって,ばら積みされた物体の個数とそれぞれの位置・姿勢を推定する手
法を提案した.
- 従来の次撮影地点決定手法 (random, maximum distance, Entropy base)と比較し,効率的に位置・姿勢の推定が可能.
- RGBDデータ⇒物体ごとのバウンディングボックス⇒物体ごとの不確かさ (attention)を計算⇒不確かな物体の位置・姿勢を最小化する
ように,次撮影地点を強化学習の方策 (PPO)を利用して決定.
- 各物体ごとの不確かさ (attention)は,ニューラルネットワークを用いて特徴量を抽出したものを使用する.
- 次撮影地点は,現在の撮影地点・これまで撮影した地点・各物体ごとの不確かさから求める.
Juil Sock, Guillermo Garcia-Hernando and Tae-Kyun Kim
まとめた人:Hachimine
https://arxiv.org/abs/1910.08811
11.
Learning to TakeGood Pictures of People with a Robot Photographer
Rhys Newbury, Akansel Cosgun, Mehmet Koseoglu and Tom Drummond
- 人の良い写真を自動で撮影するロボットの研究
- 適当に動いてYOLOで人を見つけたら写真系列を取得して,その中から最も良い写真を選択する
○ positioningを良く行うことよりも,写真の評価を良くできるようにすることに主眼を置いた
- 良い顔で写っているかを評価するネットワークと、画像全体が良いかを評価するネットワークの二段階で良
い写真を選択する
- 本システムで選択された 2328枚を,97人(1人当たり24枚)に1~5点で評価してもらった結果,平均 3.71点
,標準偏差1.06点であった
- 他の似たタスクで同様の評価をしているものと比較すると良い結果である (疑似的な比較でしかない )
まとめた人:Kazuki Mano
https://arxiv.org/abs/1904.05688
12.
Modelling social interactionbetween humans and service robots in large public spaces
Bani Anvari and Helge A Wurdemann
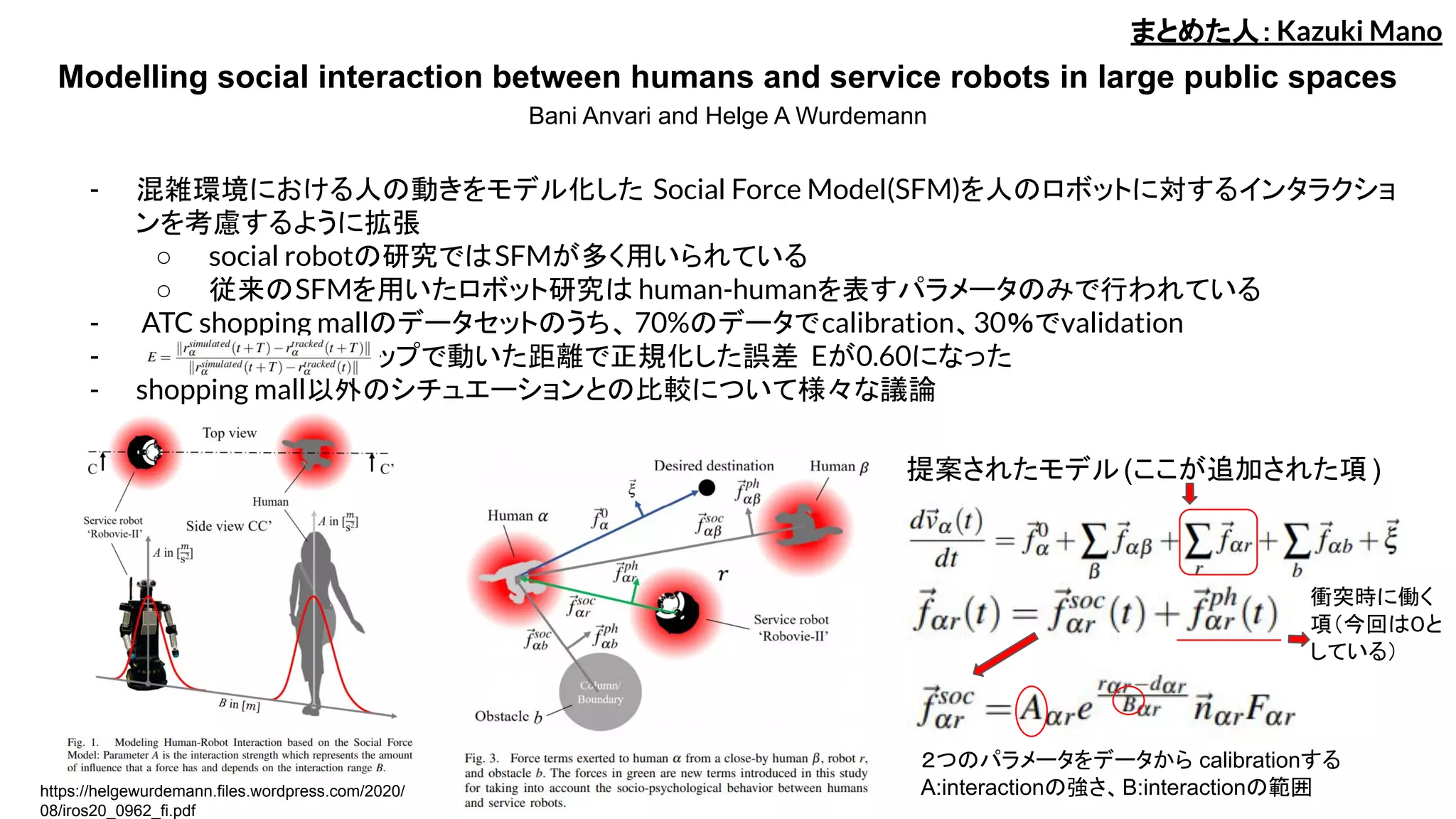
- 混雑環境における人の動きをモデル化した Social Force Model(SFM)を人のロボットに対するインタラクショ
ンを考慮するように拡張
○ social robotの研究ではSFMが多く用いられている
○ 従来のSFMを用いたロボット研究は human-humanを表すパラメータのみで行われている
- ATC shopping mallのデータセットのうち、 70%のデータでcalibration、30%でvalidation
- 1ステップで動いた距離で正規化した誤差 Eが0.60になった
- shopping mall以外のシチュエーションとの比較について様々な議論
まとめた人:Kazuki Mano
提案されたモデル(ここが追加された項 )
衝突時に働く
項(今回は0と
している)
2つのパラメータをデータから calibrationする
A:interactionの強さ、B:interactionの範囲https://helgewurdemann.files.wordpress.com/2020/
08/iros20_0962_fi.pdf
Fast Uncertainty Estimationfor Deep Learning Based Optical Flow
Serin Lee, Vincenzo Capuano, Alexei Harvard, and Soon-Jo Chung
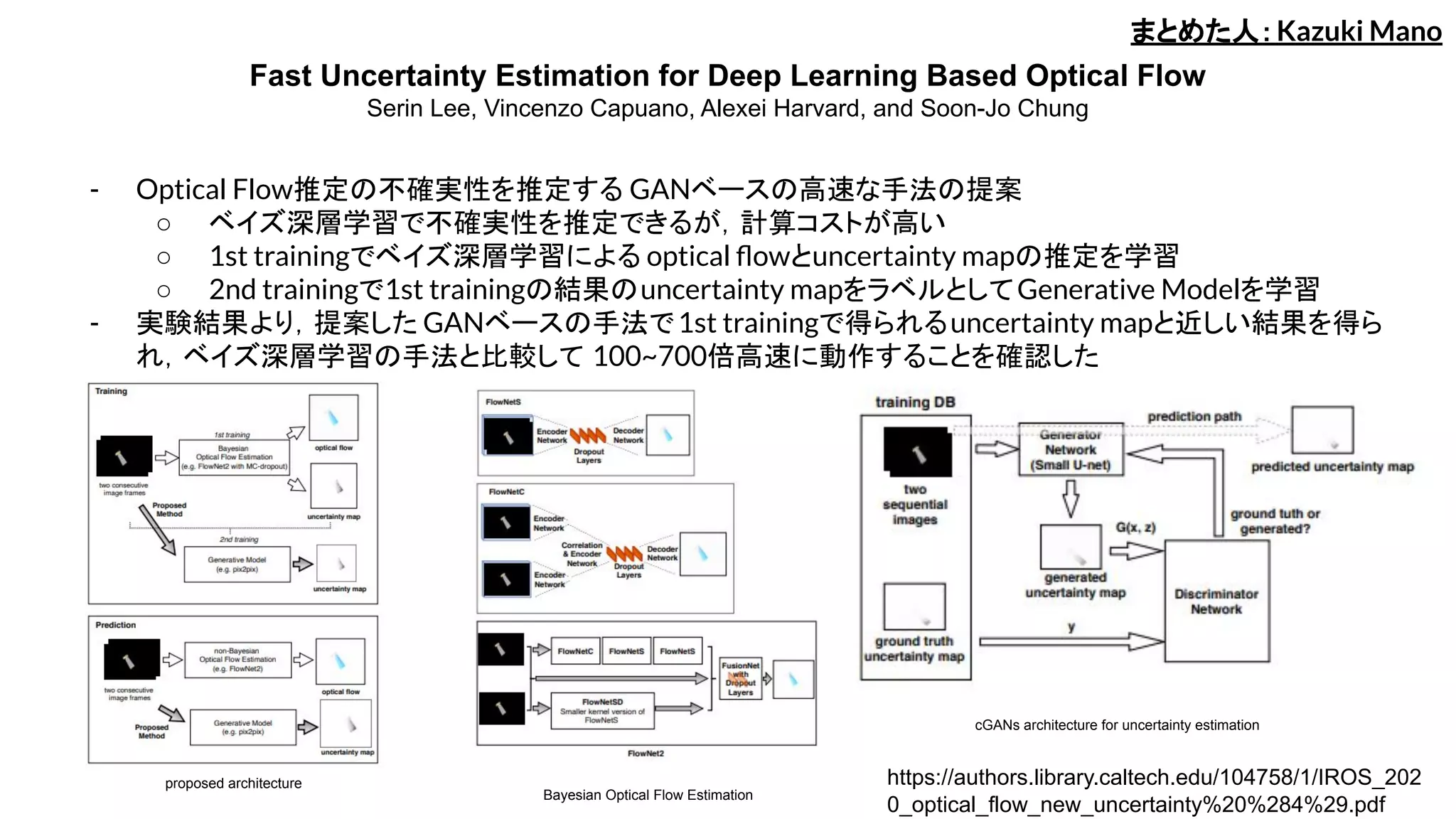
- Optical Flow推定の不確実性を推定する GANベースの高速な手法の提案
○ ベイズ深層学習で不確実性を推定できるが,計算コストが高い
○ 1st trainingでベイズ深層学習による optical flowとuncertainty mapの推定を学習
○ 2nd trainingで1st trainingの結果のuncertainty mapをラベルとしてGenerative Modelを学習
- 実験結果より,提案した GANベースの手法で1st trainingで得られるuncertainty mapと近しい結果を得ら
れ,ベイズ深層学習の手法と比較して 100~700倍高速に動作することを確認した
まとめた人:Kazuki Mano
proposed architecture
Bayesian Optical Flow Estimation
cGANs architecture for uncertainty estimation
https://authors.library.caltech.edu/104758/1/IROS_202
0_optical_flow_new_uncertainty%20%284%29.pdf
15.
Alleviating the Burdenof Labeling:Sentence Generation by Attention Branch Encoder–Decoder Network
Tadashi Ogura, Aly Magassouba, Komei Sugiura, Tsubasa Hirakawa, Takayoshi Yamashita, Hironobu Fujiyoshi and Hisashi Kawai
- 家庭用ロボット(DSRs;Domestic Service Robots)が行うタスクを対象に,自然な文を生成する研究
- 既存のMulti-ABN[Magassouba, 2019]にlinguistic branch, generation branchを導入して改良したABENを提案
○ linguistic branch: 生成される文の単語間の attention mapを推定
○ generation branch: subwordのシーケンスを生成
- Attention branchとBERTでエンコードされたsubword を組み合わせた
- BLEU scoreやROUGEなどでVSE[Vinyals, 2015], Multi-ABNとの定量的比較で最良の結果
- 定性的比較(右下図)では, Muliti-ABNはどのボトルがターゲットか特定不能だが ABENは特定可能
まとめた人:Kazuki Mano
https://arxiv.org/abs/2007.04557
16.
Learning an Uncertainty-AwareObject Detector for Autonomous Driving
Gregory P. Meyer and Niranjan Thakurdesai
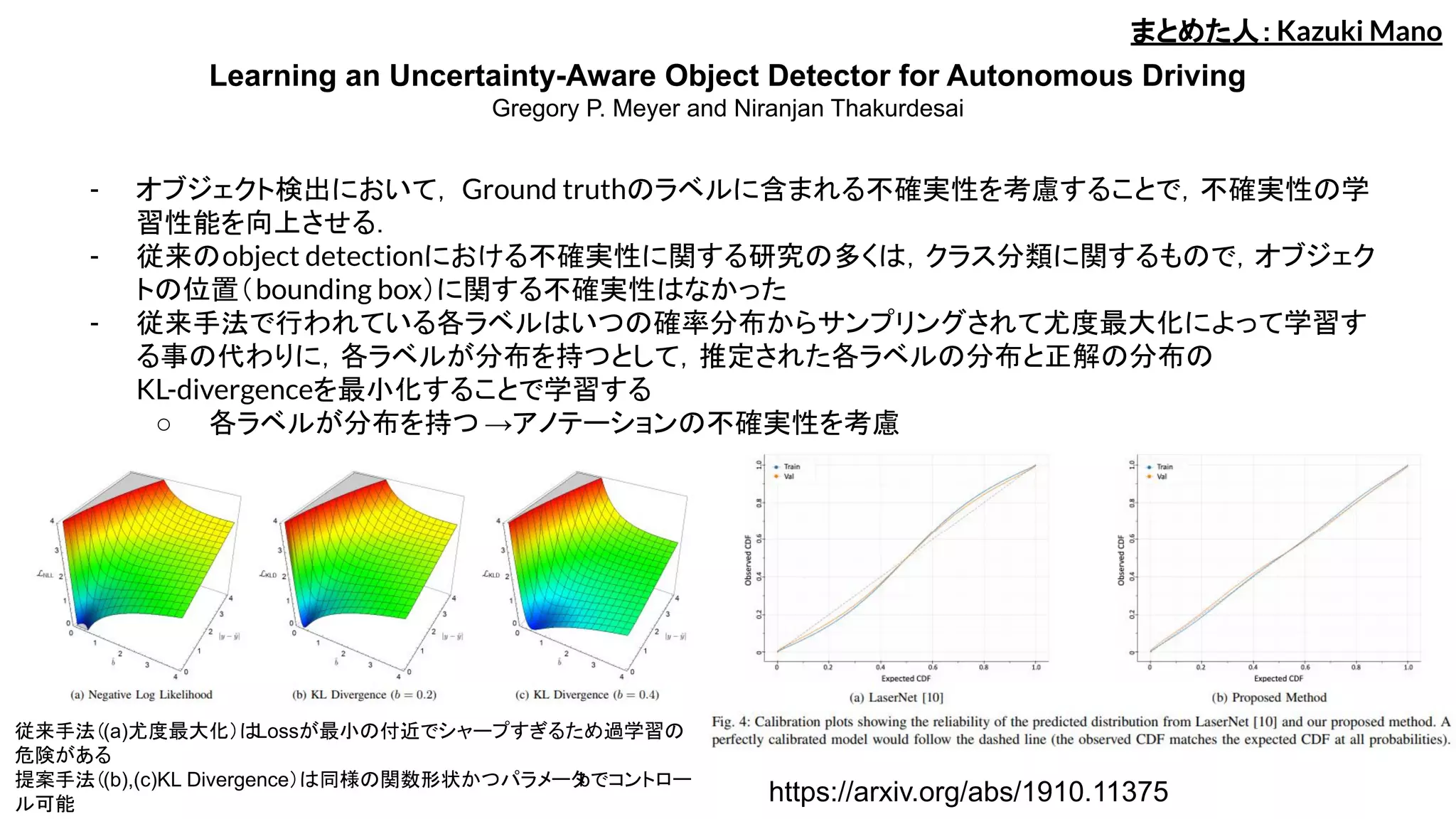
- オブジェクト検出において, Ground truthのラベルに含まれる不確実性を考慮することで,不確実性の学
習性能を向上させる.
- 従来のobject detectionにおける不確実性に関する研究の多くは,クラス分類に関するもので,オブジェク
トの位置(bounding box)に関する不確実性はなかった
- 従来手法で行われている各ラベルはいつの確率分布からサンプリングされて尤度最大化によって学習す
る事の代わりに,各ラベルが分布を持つとして,推定された各ラベルの分布と正解の分布の
KL-divergenceを最小化することで学習する
○ 各ラベルが分布を持つ →アノテーションの不確実性を考慮
-
まとめた人:Kazuki Mano
従来手法((a)尤度最大化)はLossが最小の付近でシャープすぎるため過学習の
危険がある
提案手法((b),(c)KL Divergence)は同様の関数形状かつパラメータbでコントロー
ル可能 https://arxiv.org/abs/1910.11375
17.
Leveraging Stereo-Camera Datafor Real-Time Dynamic Obstacle Detection and Tracking
Thomas Eppenberger , Gianluca Cesari , Marcin Dymczyk, Roland Siegwart, and Renaud Dube
- 安価なステレオカメラを用いてリアルタイムに動的物体の検出とトラッキングを行う方法を提案
○ ステレオカメラのみを用いてマップに反映するまでの完全な方法の提案は他にない
- 屋内,屋外環境で評価し,動的物体の検出とトラッキングにおいて MOTP 0.07±0.07m, MOTA 85.3%
○ 静的物体の検出でも precision 96.9%を達成
まとめた人:Kazuki Mano
Intel i7-8650U processor
https://arxiv.org/a
bs/2007.10743
18.
DiversityGAN: Diversity-Aware VehicleMotion Prediction Via Latent Semantic Sampling
Xin Huang, Stephen G. McGill, Jonathan A. DeCastro, Luke Fletcher, John J. Leonard, Brian C. Williams, Guy Rosman
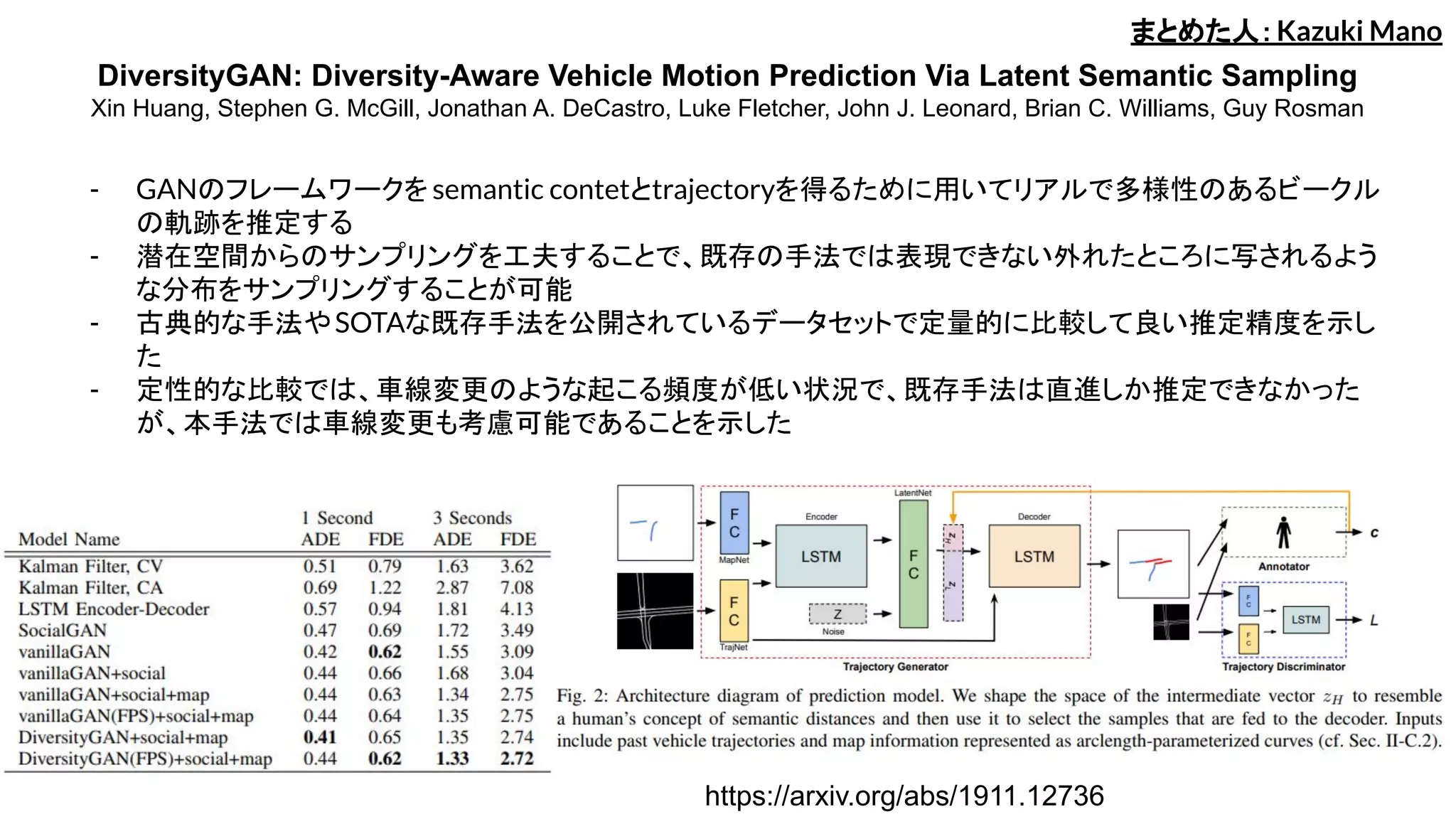
- GANのフレームワークを semantic contetとtrajectoryを得るために用いてリアルで多様性のあるビークル
の軌跡を推定する
- 潜在空間からのサンプリングを工夫することで、既存の手法では表現できない外れたところに写されるよう
な分布をサンプリングすることが可能
- 古典的な手法やSOTAな既存手法を公開されているデータセットで定量的に比較して良い推定精度を示し
た
- 定性的な比較では、車線変更のような起こる頻度が低い状況で、既存手法は直進しか推定できなかった
が、本手法では車線変更も考慮可能であることを示した
まとめた人:Kazuki Mano
https://arxiv.org/abs/1911.12736
19.
Understanding Contexts InsideRobot and Human Manipulation Tasks through Vision-Language
Model and Ontology System in Video Streams
Chen Jiang, Masood Dehghan and Martin Jagersand
- 人やロボットが行う動作を解釈し,知識グラフとしてためるスキームの提案。
- そのために人とロボットのそれぞれが動作を行った動画を集めたデータセットを構築した。
- さらに,動画に動作の知識をキャプション付けする Vision-Languageモデルを設計した。
https://arxiv.org/abs/2003.01163
20.
“Good Robot!”: EfficientReinforcement Learning for Multi-Step Visual Tasks with Sim to Real Transfer
Andrew Hundt, Benjamin Killeen, Nicholas Greene, Hongtao Wu, Heeyeon Kwon, Chris Paxton, and Gregory D. Hager
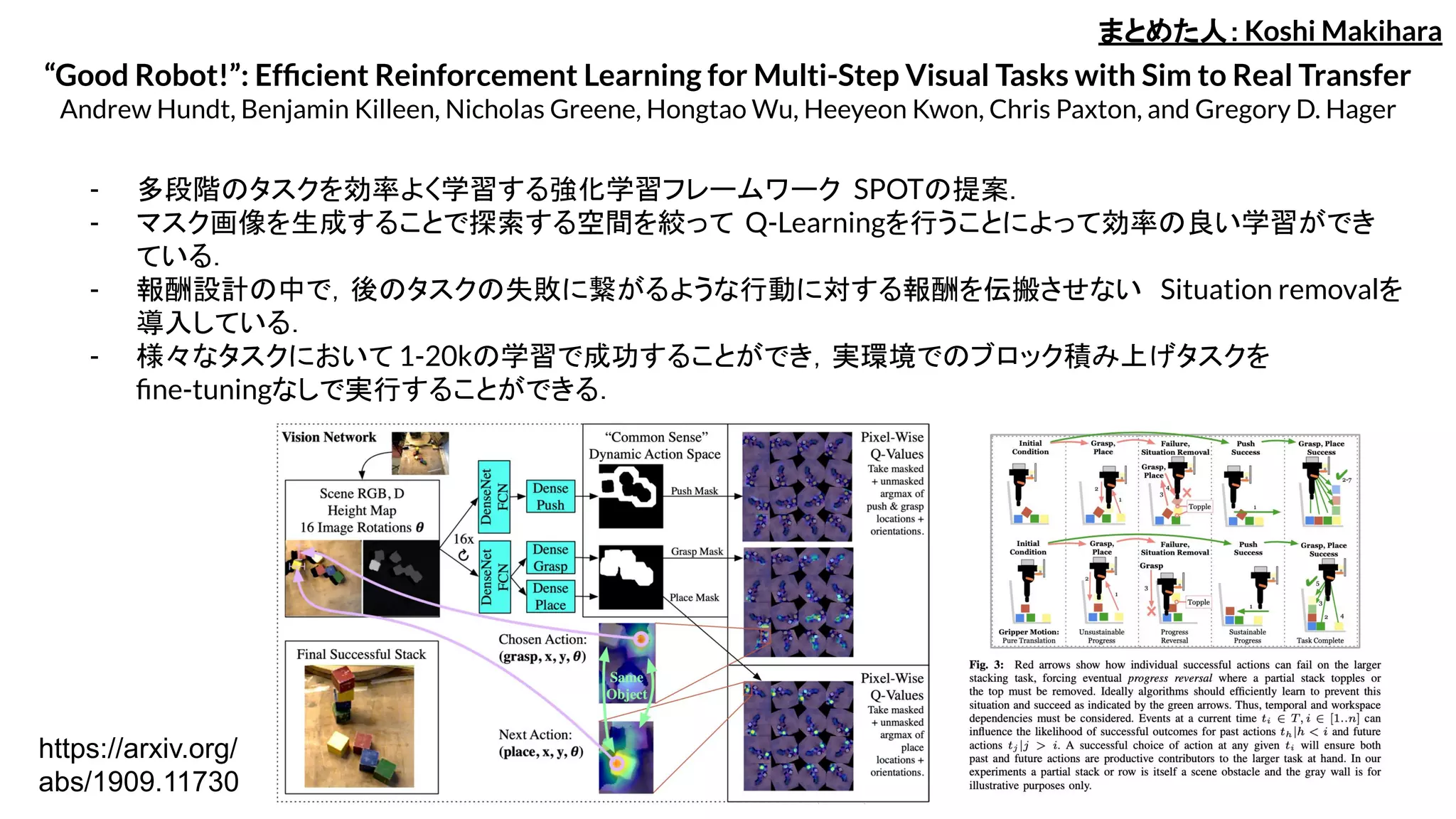
- 多段階のタスクを効率よく学習する強化学習フレームワーク SPOTの提案.
- マスク画像を生成することで探索する空間を絞って Q-Learningを行うことによって効率の良い学習ができ
ている.
- 報酬設計の中で,後のタスクの失敗に繋がるような行動に対する報酬を伝搬させない Situation removalを
導入している.
- 様々なタスクにおいて 1-20kの学習で成功することができ,実環境でのブロック積み上げタスクを
fine-tuningなしで実行することができる.
まとめた人:Koshi Makihara
https://arxiv.org/
abs/1909.11730
21.
SwingBot: Learning PhysicalFeatures from In-hand Tactile Exploration for Dynamic Swing-up
Manipulation
Chen Wang, Shaoxiong Wang, Branden Romero, Filipe Veiga and Edward Adelson
- 触覚を使って把持した物体の物理特徴を学習し,スイング動作を行う手法.
- 視触覚センサGelSightを使ってtilting(傾ける)とshaking(振る)動作を行った時の触覚情報を取得して,物
体の摩擦係数や質量,重心位置や慣性モーメントなどの物理情報を推定する.
- 未知の物理情報を持つ物体に対して推定を行い,動的なスイング動作をした時の姿勢(角度)を推定し,こ
れを自己教師としてスイング動作を学習する.
まとめた人:Koshi Makihara
http://gelsight.csail.mit.edu/swingbot/IROS2020_SwingBot.pdf
22.
Design and Controlof Roller Grasper V2 for In-Hand Manipulation
Shenli Yuan, Lin Shao, Connor L. Yako, Alex Gruebele, and J. Kenneth Salisbury
- 指先につけた2自由度の球形の回転機構をもつ active surfaceを使って物体操作をする手法.
- 1つの指に合計3自由度の機構を設け, 3本の指からなるハンドを使って,ピボット動作ところがし動作を行
い任意の位置姿勢へ In-Hand操作を行う.
- 解析的アプローチによって得られた操作ポリシーをエキスパートとして模倣学習に用いて,未知の形状の
物体に対してIn-Hand操作の任意の軌道を生成する.
- 模倣学習を用いることによってロバスト性の高い動作と,安全で再現性のある軌道を生成することができ
る.
まとめた人:Koshi Makihara
https://arxiv.org/abs/2004.08499
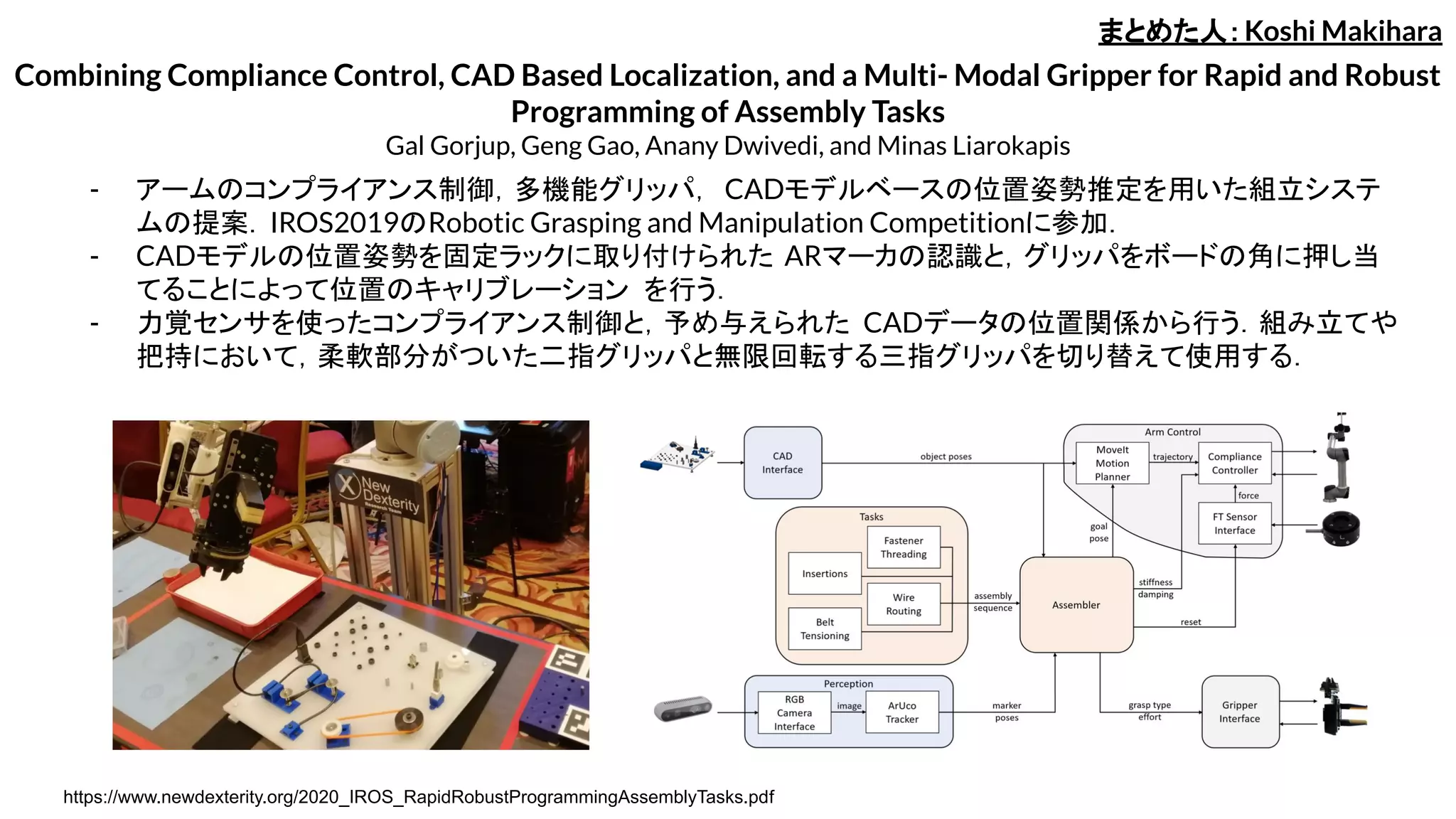
Combining Compliance Control,CAD Based Localization, and a Multi- Modal Gripper for Rapid and Robust
Programming of Assembly Tasks
Gal Gorjup, Geng Gao, Anany Dwivedi, and Minas Liarokapis
- アームのコンプライアンス制御,多機能グリッパ, CADモデルベースの位置姿勢推定を用いた組立システ
ムの提案.IROS2019のRobotic Grasping and Manipulation Competitionに参加.
- CADモデルの位置姿勢を固定ラックに取り付けられた ARマーカの認識と,グリッパをボードの角に押し当
てることによって位置のキャリブレーション を行う.
- 力覚センサを使ったコンプライアンス制御と,予め与えられた CADデータの位置関係から行う.組み立てや
把持において,柔軟部分がついた二指グリッパと無限回転する三指グリッパを切り替えて使用する.
まとめた人:Koshi Makihara
https://www.newdexterity.org/2020_IROS_RapidRobustProgrammingAssemblyTasks.pdf
25.
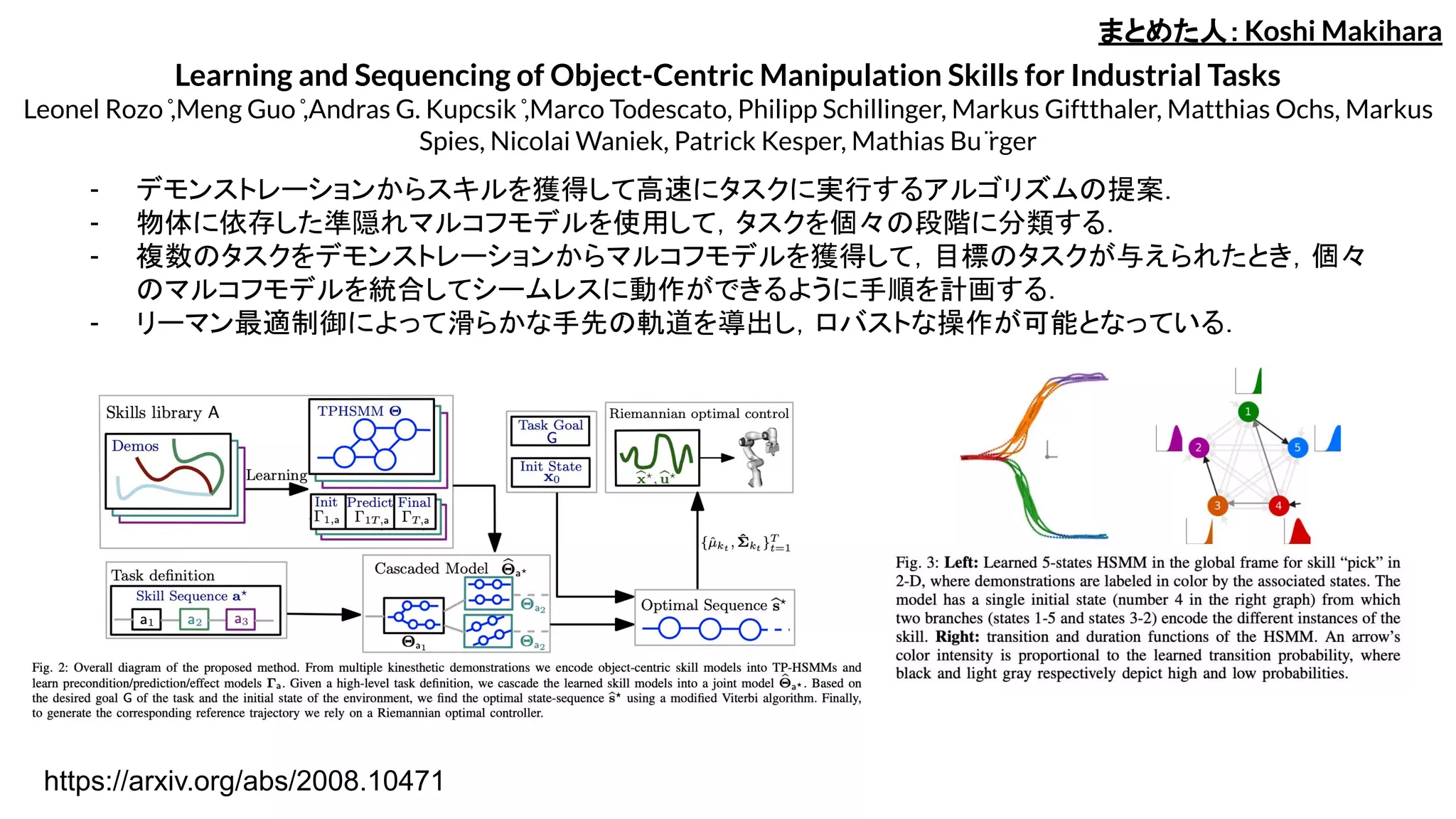
Learning and Sequencingof Object-Centric Manipulation Skills for Industrial Tasks
Leonel Rozo ̊,Meng Guo ̊,Andras G. Kupcsik ̊,Marco Todescato, Philipp Schillinger, Markus Giftthaler, Matthias Ochs, Markus
Spies, Nicolai Waniek, Patrick Kesper, Mathias Bu ̈rger
- デモンストレーションからスキルを獲得して高速にタスクに実行するアルゴリズムの提案.
- 物体に依存した準隠れマルコフモデルを使用して,タスクを個々の段階に分類する.
- 複数のタスクをデモンストレーションからマルコフモデルを獲得して,目標のタスクが与えられたとき,個々
のマルコフモデルを統合してシームレスに動作ができるように手順を計画する.
- リーマン最適制御によって滑らかな手先の軌道を導出し,ロバストな操作が可能となっている.
まとめた人:Koshi Makihara
https://arxiv.org/abs/2008.10471
26.
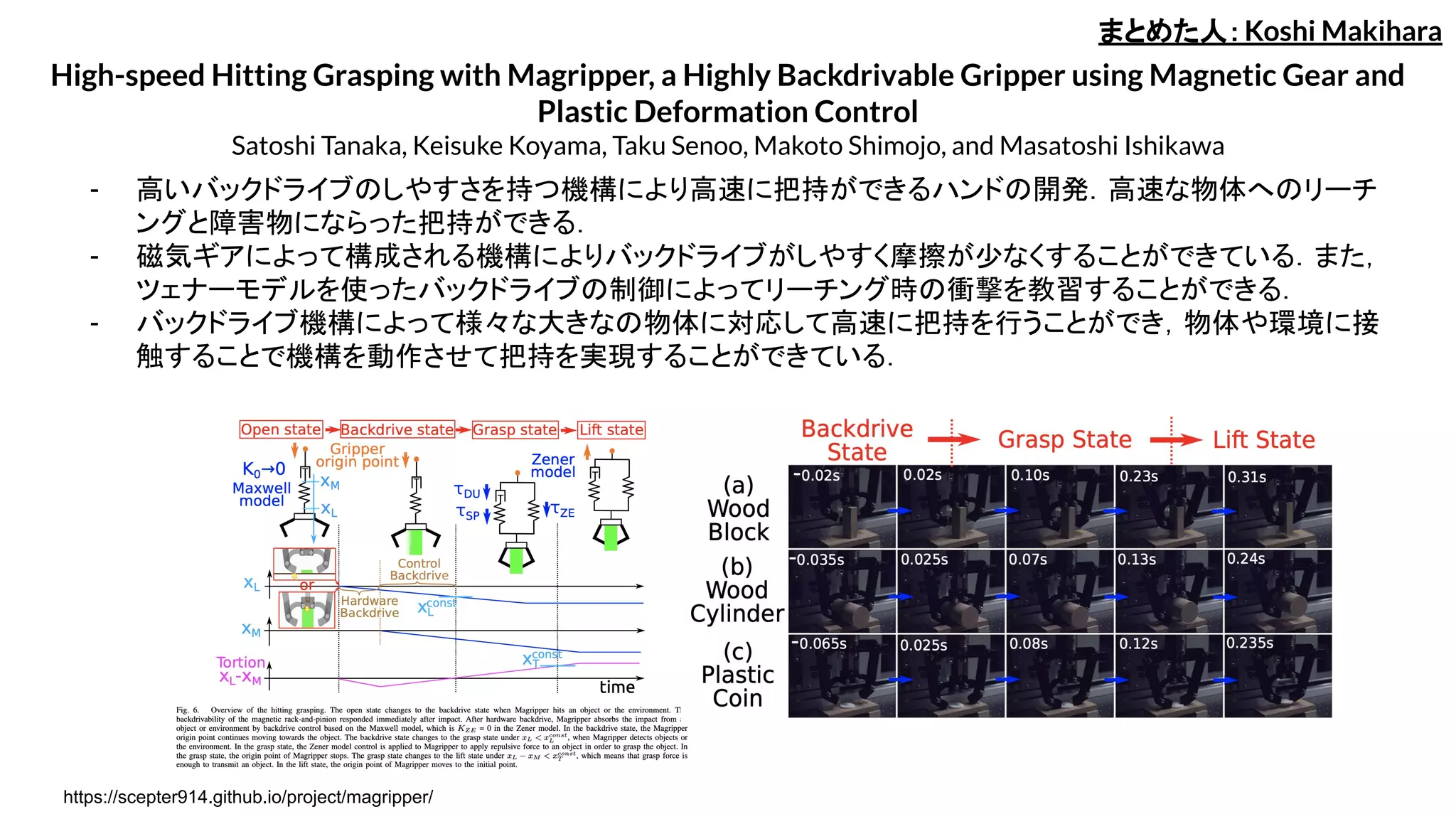
High-speed Hitting Graspingwith Magripper, a Highly Backdrivable Gripper using Magnetic Gear and
Plastic Deformation Control
Satoshi Tanaka, Keisuke Koyama, Taku Senoo, Makoto Shimojo, and Masatoshi Ishikawa
- 高いバックドライブのしやすさを持つ機構により高速に把持ができるハンドの開発.高速な物体へのリーチ
ングと障害物にならった把持ができる.
- 磁気ギアによって構成される機構によりバックドライブがしやすく摩擦が少なくすることができている.また,
ツェナーモデルを使ったバックドライブの制御によってリーチング時の衝撃を教習することができる.
- バックドライブ機構によって様々な大きなの物体に対応して高速に把持を行うことができ,物体や環境に接
触することで機構を動作させて把持を実現することができている.
まとめた人:Koshi Makihara
https://scepter914.github.io/project/magripper/
27.
A Probabilistic Shared-ControlFramework for Mobile Robots
Soheil Gholami , Virginia Ruiz Garate, Elena De Momi, and Arash Ajoudani
- 移動ロボットのターゲット検出と制御を目的とした共有制御フレームワークを提案.
- ターゲットの変更,センサーのエラー,予期せぬ障害物の発生に対応.
- オペレータの操作入力をターゲットの確率的評価と統合.
- オペレータは操作中,環境の視覚的 FBと目標推定ステータスの音声 FBを受取.
- シミュレーションと実機実験により,時間効率の向上と操作負担の軽減を確認.
まとめた人:Kurena Motokura
https://zenodo.org/record/4017583#.X9g8sekza3I
28.
Unsupervised Domain Adaptationfor Transferring Plant
Classification Systems to New Field Environments, Crops, and Robots
Dario Gogoll, Philipp Lottes, Jan Weyler, Nik Petrinic, Cyrill Stachniss
- 農場における作物,雑草および土壌のセグメンテーションのドメイン適応 (異なる作物/環境/センサ)
- CycleGANをベースとし,画像の変換前後で認識結果が一貫するように拘束をかける semantic
consistency loss (以下SCL)を追加(CyCADAと類似)
- 新規性(CyCADAとの相違点):
1. セグメンテーションの評価に CEではなくIoU lossを使用(クラスの偏りがある場合に学習がより安定する
らしい)
2. Sourceの変換前後に加え, sourceの再変換後,Targetの変換/再変換後にもSCLを追加
- Ablation studyはなかったので,IoU lossの効果や追加された SCLの効果は不明
まとめた人:Shigemichi Matsuzaki
https://www.researchgate.net/publication/344100796_Unsupervised_Domai
n_Adaptation_for_Transferring_Plant_Classification_Systems_to_New_Fiel
d_Environments_Crops_and_Robots
Real-time Fusion Networkfor RGB-D Semantic Segmentation
Incorporating Unexpected Obstacle Detection for Road-driving Images
Lei Sun, Kailun Yang, Xinxin Hu, Weijian Hu and Kaiwei Wang
- 屋外におけるリアルタイムな RGB-Dセマンティックセグメンテーション (SS)ネットワークの提案
○ RGB-DのSSは主に屋内で研究されており,屋外ではあまりやられてない
○ AFC : アテンション機構を用いて有用な特徴 (RGB or Depth)に注目して特徴統合
○ Efficient Upsampling Module: Bilinear補間+対応するエンコーダ特徴との足し合わせ
- Multi-dataset learning: 学習データのバリエーションを増やすため,複数のデータセットで学習
○ データセット間のクラスの種類,アノテーション方法の違いに対応する学習手法
■ データセットに共通するクラスと,上記の相違があるクラスで別々に損失を計算 ?
- CityscapesとLost and found datasetで学習
○ Depth(disparity)はステレオ画像を用いて計算
まとめた人:Shigemichi Matsuzaki
https://arxiv.org/abs/2002.10570
31.
Unsupervised Domain Adaptationthrough Inter-modal Rotation for RGB-D Object Recognition
Mohammad Reza Loghmani, Luca Robbiano, Mirco Planamente, Kiru Park, Barbara Caputo and Markus Vincze
- RGB-Dデータを用いた物体認識タスクにおける Sim-to-realのドメイン適応(DA)
- ソースドメイン(シミュレーション画像)で本来のタスクである物体認識を学習
- ドメイン間で不変の特徴を学習するため、 RGB画像と深度画像をそれぞれ独立に回転させ、それらの角度の
差を求めるサブタスクを追加( 0°、90°、180° or 270°)
○ 教師ラベルを必要としない →ソースとターゲット双方で学習
- 既存の実画像データセットに対応する独自の合成データセットを構築し、 DAの性能を評価
○ 既存のDA手法ではRGB-Dデータに対して良い結果が得られない
■ DepthはRGBより情報が少ないので、効果的な特徴抽出の戦略がないと ×
○ 提案手法ではサブタスクにより良い特徴が抽出できている?
まとめた人:Shigemichi Matsuzaki
https://arxiv.org/abs/2004.10016
32.
Autonomous Spot: Long-RangeAutonomous Exploration of
Extreme Environments with Legged Locomotion
Amanda Bouman, Muhammad Fadhil Ginting, Nikhilesh Alatur, Matteo Palieri, David D. Fan, Thomas Touma, Torkom
Pailevanian, Sung-Kyun Kim, Kyohei Otsu, Joel Burdick, and Ali-akbar Agha-Mohammadi
- ボストン・ダイナミクス社の Spotを用いて長時間・広範囲の探索システムの構築
○ Networked Belief-aware Perceptual Autonomy (NeBula)
- 複数のオドメトリソース (kinematic, visual)のうち信頼度を高いものを初期値とし、 LIDARデータのマッチングを
行うことで自己位置推定と SLAM
○ 信頼度の評価、自己位置推定、 SLAMの各技術は別論文
- 複数センサの情報を用いて障害物を検出、サンプリングされたグリッドでのみ通過可能性を計算し、膨張や
補間を用いることによるリアルタイムな Traversability mapの生成
○ Traversability mapは多レイヤで、各レイヤは異なる性質の通過可能性 (一般的な障害物、他ロボッ ト
etc.)を表し、各レイヤの確率を掛け合わせて最終的な通過可能性を計算
- 複数台のロボットで、 1時間以内に〜数kmの距離を自律移動し、探索を行うことに成功
まとめた人:Shigemichi Matsuzaki
https://arxiv.org/abs/2010.09259
33.
Interactive Movement Primitives:Planning to Push Occluding Pieces for Fruit Picking
Sariah Mghames, Marc Hanheide and Amir Ghalamzan E
- 熟した果実を遮蔽する熟していない果実を押しのけるための動作計画手法 Interactive-ProMP (I-ProMP)
○ ProMP(Probabilistic Movement Primitives)を改良
- 異なる非線形性を持つ ProMPモデルを複数組み合わせ、比較的線形に近い果実へのアプローチと非線形性
の高い押しのけ動作を実現
- 把持対象の果実周辺の各果実について押しのける先の位置を
求め、それをProMPの条件として動作計画
- シミュレーション環境 (Gazebo)で実験
まとめた人:Shigemichi Matsuzaki
https://arxiv.org/abs/2004.12916
34.
Efficient Trajectory LibraryFiltering for Quadrotor Flight in Unknown Environments
Vaibhav K. Viswanathan, Eric Dexheimer, Guanrui Li, Giuseppe Loianno, Michael Kaess, and Sebastian Scherer
- MAVの軌道計画における、障害物との衝突リスクのある軌道候補の効率的なフィルタリング
- 軌道計画の中で、衝突判定が大きな計算量を要する。既存手法は正確で遅い or 早くて粗い
- 提案手法:
○ オフライン処理: ロボット座標系の3D格子地図上で、予め生成したすべての軌道候補に対し衝突判定
■ N個の候補に対し、各セルについて軌道がそのセルに衝突するかを長さ Nのビット列として格納
○ オンライン処理: ビット計算(OR)により高速な衝突判定
- シミュレーションと実機で動作確認
○ 軌道計画のループは〜 50Hzで動作可能
まとめた人:Shigemichi Matsuzaki
https://www.cs.cmu.edu/~kaess/pub/Viswanathan20iros.pdf
Real-world human-robot collaborativereinforcement learning
Ali Shafti, Jonas Tjomsland, William Dudley and A. Aldo Faisal
- エージェントが人と共同でタスクを行う Human-in-the-Loop強化学習
○ 2つの軸の自由度を持つ台の片方を人間が,もう片方をエージェントが操作して,台の上に乗ったボール
をゴールまで運ぶタスク
- 新規性: 既存のhuman-in-the-loopシステムではシミュレータのみのシステムだったり,人とエージェント間の
明示的なコミュニケーションを要したりする.
○ 提案手法は,実環境で,状態空間に(暗に)内在する人の操作の情報(人が操作する軸に関する値)を元
に方策を学習
- 複数の被験者による実験から,提案する手法で人間とエージェントの co-traniningが起こることを確認
○ ただし,学習の具合は被験者によって大きく異なる
まとめた人:Shigemichi Matsuzaki
https://arxiv.org/abs/2003.01156
37.
LiTAMIN : LiDAR-basedTracking And MappINg by Stabilized ICP
for Geometry Approximation with Normal Distributions
Masashi Yokozuka, Kenji Koide, Shuji Oishi and Atsuhiko Banno
- 3D LIDARを用いたSLAMにおける、高速かつ安定した ICPマッチング手法
- NDTやGICPでは、共分散行列がランク落ちした場合の最適化計算を安定させるために PCAに基づく共分散
行列の変換を行う→計算量が多い。
- 提案手法ではより計算量の低い新しい共分散行列の変換によるコスト関数を用いる。
- 地図表現にはvoxel grid、対応点の探索には k-d木を使用→両者の長所を取り入れる
- ICPによる誤差に基づいて適応的に重み付けられたコスト関数による頑健なグラフ最適化
- 既存手法より高い精度と、 ICPベースでありながら特徴点ベースの手法に匹敵する処理速度を両立
まとめた人:Shigemichi Matsuzaki
https://staff.aist.go.jp/sh
uji.oishi/assets/projects/
LiTAMIN/index.html
38.
SwingBot: Learning PhysicalFeatures from In-hand Tactile Exploration for Dynamic Swing-up
Manipulation
Chen Wang, Shaoxiong Wang, Branden Romero, Filipe Veiga and Edward Adelson
- 動作対象の物理的性質(質量、持ち手の摩擦力 etc.)を、ロボットがテスト動作を通して推定し、その情報から
目的の動作に適した動作パラメータを推定
○ 指定された角度への物体の振り上げ動作において、物体を持って傾けたり( tilt)振ったり(shake)し
た際の力の変化を、指に取り付けた視触覚センサで検知
○ 各動作によって得られた触覚情報を CNNで特徴空間に埋め込み、振り上げ角度の推定に使用
-
まとめた人:Shigemichi Matsuzaki
http://gelsight.csail.mit.edu/swingbot/IROS2020_SwingBot.pdf
39.
C*: Cross-modal SimultaneousTracking And Rendering for 6-DoF Monocular Camera Localization
Beyond Modalities
Shuji Oishi, Yasunori Kawamata, Masashi Yokozuka, Kenji Koide, Atsuhiko Banno, Jun Miura
- 既知の3次元地図を用いたクロスモーダルな単眼カメラの 6-DoF姿勢推定
- 画像類似度のメトリックとして NID (normalized information distance)を用いることで、地図とカメラが異なるモ
ダリティを持っていても姿勢推定が可能
○ NID: データ間の相互情報量に基づく距離
- 実験: 既存手法(輝度誤差に基づくもの、エッジ間距離に基づくもの)と精度を比較
○ 既存手法でトラッキング不可能な厳しいノイズ条件においても動作可能
○ テクスチャを持った3次元地図のほか、LiDARで生成した反射強度付き地図、物体ラベルを持つセマン
ティック地図を用いても動作可能
○ GeForce 1080、CUDAによる実装で12.5[Hz]の処理速度
まとめた人:Shigemichi Matsuzaki
https://staff.aist.go.jp/shuji.oishi/assets/projects/C-STAR/index.html
40.
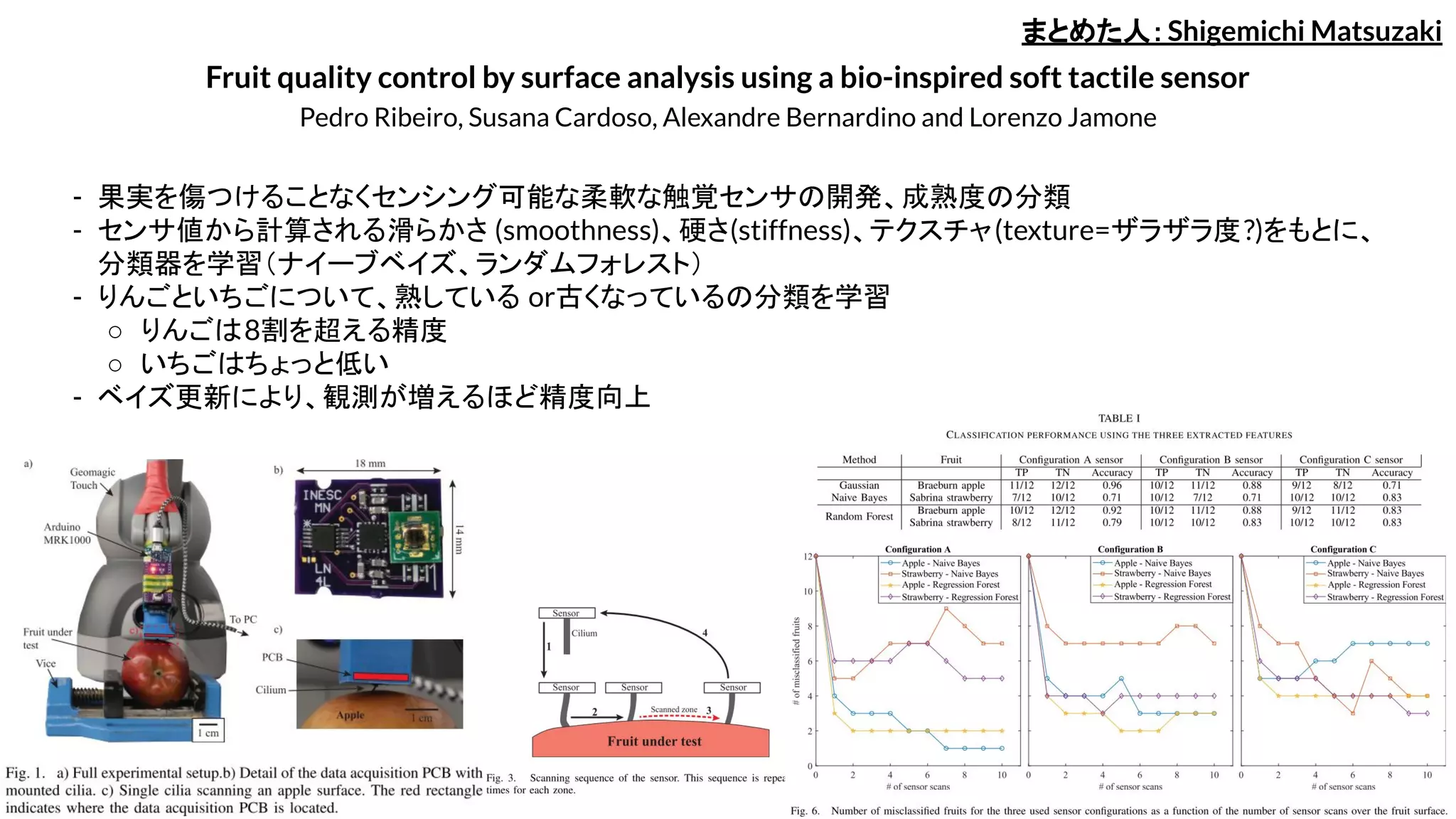
Fruit quality controlby surface analysis using a bio-inspired soft tactile sensor
Pedro Ribeiro, Susana Cardoso, Alexandre Bernardino and Lorenzo Jamone
- 果実を傷つけることなくセンシング可能な柔軟な触覚センサの開発、成熟度の分類
- センサ値から計算される滑らかさ (smoothness)、硬さ(stiffness)、テクスチャ(texture=ザラザラ度?)をもとに、
分類器を学習(ナイーブベイズ、ランダムフォレスト)
- りんごといちごについて、熟している or古くなっているの分類を学習
○ りんごは8割を超える精度
○ いちごはちょっと低い
- ベイズ更新により、観測が増えるほど精度向上
まとめた人:Shigemichi Matsuzaki
41.
Deep Depth Estimationfrom Visual-Inertial SLAM
Kourosh Sartipi, Tien Do, Tong Ke, Khiem Vuong, and Stergios I. Roumeliotis
- Visual Inertial SLAMを用いて,疎なDepth画像から密なDepth画像を生成する問題設定.
- 新規性は重力方向ベクトルと面の法線ベクトルを用いた Depthの補間にある.
- 具体的には画像から推定した Plane Masks,重力方向ベクトルを用いて回転補正した画像から推定した
Surface Normal,Visual Inertial SLAMで得られた疎な点群を用いて平面の Depthを補完する.
- ScanNet dataset,NYUv2 dataset,著者が作成したAzure Kinect datasetを用いたテストにて,従来手法よ
りも高い精度を達成した.
- Experimetsの結果から重力方向ベクトルの補正が最も性能向上に効いていると考えられる.
まとめた人:Shoji Sonoyama
github:https://github.com/MARSLab-UMN/vi_depth_completionhttps://arxiv.org/abs/2008.00092
42.
Safe and EffectivePicking Paths in Clutter given Discrete Distributions of Object Poses
Rui Wang, Chaitanya Mitash, Shiyang Lu, Daniel Boehm, Kostas E. Bekris
- 障害物と対象物の両方に不確実性があり,複数物体で構成されるシーン下で対象物を Pickするタスクにおいて離散分布を用いた
6Dpose推定手法と推定した poseを用いたPlanning Pipelineの提案.
- Planningでは,障害物との衝突確立を最小化し,目標物に到達する確率を最大化するような Pathを生成する.
-
まとめた人:Souta Hirose
https://arxiv.org/abs/2008.04465
43.
X-Ray: Mechanical Searchfor an Occluded Object by Minimizing Support of Learned Occupancy
Distributions
Michael Danielczuk , Anelia Angelova , Vincent Vanhoucke , Ken Goldberg
- 教師あり学習を用いた部分的もしくは完全に隠れている目標物体の探索手法の提案
- 目標物体が他物体により隠されている環境における合成データを用いて,隠されていると想定される箇所を予測している.
- 予測した箇所に対して各物体の segment領域が最も重なっている物体を把持し,探索する.
- Simulationと実機の両方で検証を行った.中央値で 5回のActionによって、15~25個の物体を含むヒープの内 82%~100%において目
標物体を発見した.
まとめた人:Souta Hirose
https://sites.google.com/berkeley.edu/x-ray
44.
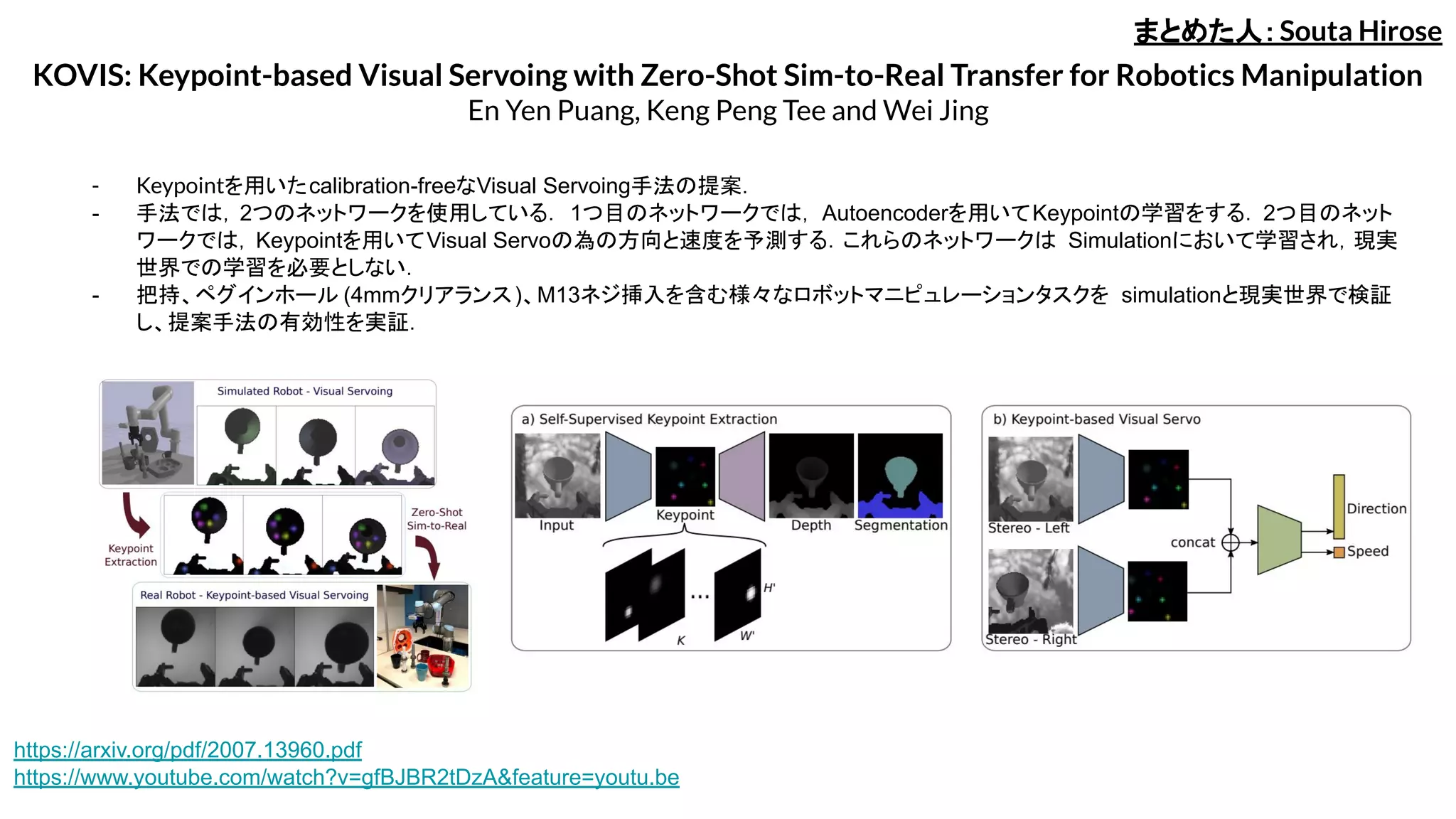
KOVIS: Keypoint-based VisualServoing with Zero-Shot Sim-to-Real Transfer for Robotics Manipulation
En Yen Puang, Keng Peng Tee and Wei Jing
- Keypointを用いたcalibration-freeなVisual Servoing手法の提案.
- 手法では,2つのネットワークを使用している. 1つ目のネットワークでは, Autoencoderを用いてKeypointの学習をする.2つ目のネット
ワークでは,Keypointを用いてVisual Servoの為の方向と速度を予測する.これらのネットワークは Simulationにおいて学習され,現実
世界での学習を必要としない.
- 把持、ペグインホール (4mmクリアランス)、M13ネジ挿入を含む様々なロボットマニピュレーションタスクを simulationと現実世界で検証
し、提案手法の有効性を実証.
まとめた人:Souta Hirose
https://arxiv.org/pdf/2007.13960.pdf
https://www.youtube.com/watch?v=gfBJBR2tDzA&feature=youtu.be
45.
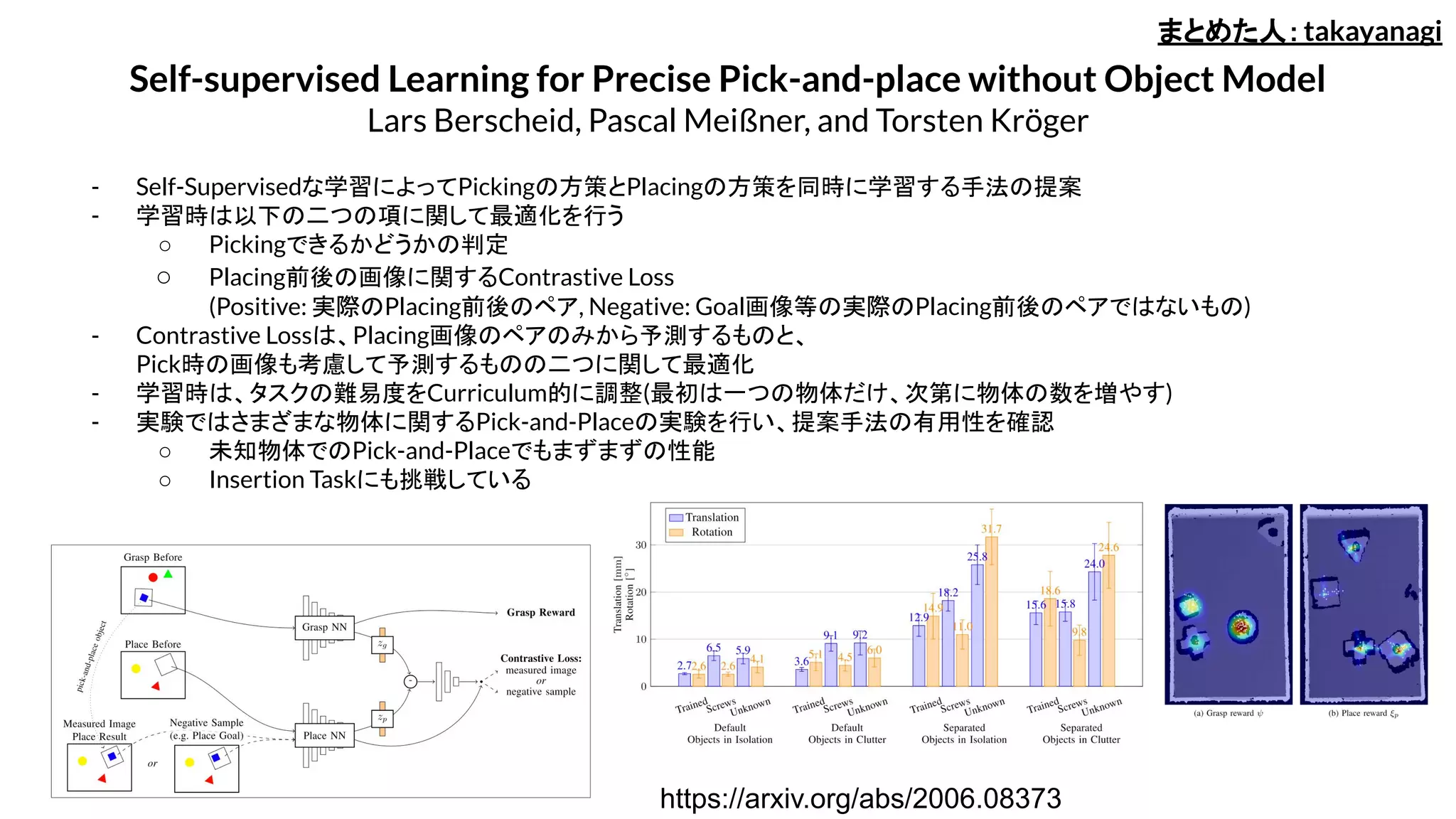
- Self-Supervisedな学習によってPickingの方策とPlacingの方策を同時に学習する手法の提案
- 学習時は以下の二つの項に関して最適化を行う
○Pickingできるかどうかの判定
○ Placing前後の画像に関するContrastive Loss
(Positive: 実際のPlacing前後のペア, Negative: Goal画像等の実際のPlacing前後のペアではないもの)
- Contrastive Lossは、Placing画像のペアのみから予測するものと、
Pick時の画像も考慮して予測するものの二つに関して最適化
- 学習時は、タスクの難易度をCurriculum的に調整(最初は一つの物体だけ、次第に物体の数を増やす)
- 実験ではさまざまな物体に関するPick-and-Placeの実験を行い、提案手法の有用性を確認
○ 未知物体でのPick-and-Placeでもまずまずの性能
○ Insertion Taskにも挑戦している
Self-supervised Learning for Precise Pick-and-place without Object Model
Lars Berscheid, Pascal Meißner, and Torsten Kröger
まとめた人:takayanagi
https://arxiv.org/abs/2006.08373
46.
- 人のデモンストレーションから把持スキルを学習するシステムの提案
- デモンストレーション収集のためのハードウェア環境を構築
○見た目はロボットと変わらず、人が操作しやすい設計
○ デモンストレーション時の行動は、フレーム間のキーポイントの姿勢変化から推定される
- Policyは35種類のAction候補(並進の行動5種類x回転の行動7種類)から適切なものを出力
- 学習は、Human Demonstrationでpretrain後、ロボット環境でfine-tune
- さまざまな場所にある物体を把持する実験で、高い成功率を達成
Grasping in the Wild: Learning 6DoF Closed-Loop Grasping from Low-Cost Demonstrations
Shuran Song Andy Zeng Johnny Lee Thomas Funkhouser
まとめた人:takayanagi
デモ収集用ハードウェア タスク実行ロボット https://arxiv.org/abs/1912.04344











![Alleviating the Burden of Labeling:Sentence Generation by Attention Branch Encoder–Decoder Network
Tadashi Ogura, Aly Magassouba, Komei Sugiura, Tsubasa Hirakawa, Takayoshi Yamashita, Hironobu Fujiyoshi and Hisashi Kawai
- 家庭用ロボット(DSRs;Domestic Service Robots)が行うタスクを対象に,自然な文を生成する研究
- 既存のMulti-ABN[Magassouba, 2019]にlinguistic branch, generation branchを導入して改良したABENを提案
○ linguistic branch: 生成される文の単語間の attention mapを推定
○ generation branch: subwordのシーケンスを生成
- Attention branchとBERTでエンコードされたsubword を組み合わせた
- BLEU scoreやROUGEなどでVSE[Vinyals, 2015], Multi-ABNとの定量的比較で最良の結果
- 定性的比較(右下図)では, Muliti-ABNはどのボトルがターゲットか特定不能だが ABENは特定可能
まとめた人:Kazuki Mano
https://arxiv.org/abs/2007.04557](https://image.slidesharecdn.com/iros2020surveytotalpublic-201215100833/75/IROS2020-survey-15-2048.jpg)















![C*: Cross-modal Simultaneous Tracking And Rendering for 6-DoF Monocular Camera Localization
Beyond Modalities
Shuji Oishi, Yasunori Kawamata, Masashi Yokozuka, Kenji Koide, Atsuhiko Banno, Jun Miura
- 既知の3次元地図を用いたクロスモーダルな単眼カメラの 6-DoF姿勢推定
- 画像類似度のメトリックとして NID (normalized information distance)を用いることで、地図とカメラが異なるモ
ダリティを持っていても姿勢推定が可能
○ NID: データ間の相互情報量に基づく距離
- 実験: 既存手法(輝度誤差に基づくもの、エッジ間距離に基づくもの)と精度を比較
○ 既存手法でトラッキング不可能な厳しいノイズ条件においても動作可能
○ テクスチャを持った3次元地図のほか、LiDARで生成した反射強度付き地図、物体ラベルを持つセマン
ティック地図を用いても動作可能
○ GeForce 1080、CUDAによる実装で12.5[Hz]の処理速度
まとめた人:Shigemichi Matsuzaki
https://staff.aist.go.jp/shuji.oishi/assets/projects/C-STAR/index.html](https://image.slidesharecdn.com/iros2020surveytotalpublic-201215100833/75/IROS2020-survey-39-2048.jpg)




![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)










![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]BADGR: An Autonomous Self-Supervised Learning-Based Navigation System](https://cdn.slidesharecdn.com/ss_thumbnails/20200403rindokukai-200403043041-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/differentiablemappingnetworks-200707033539-thumbnail.jpg?width=640&height=640&fit=bounds)
























