Downloaded 179 times



















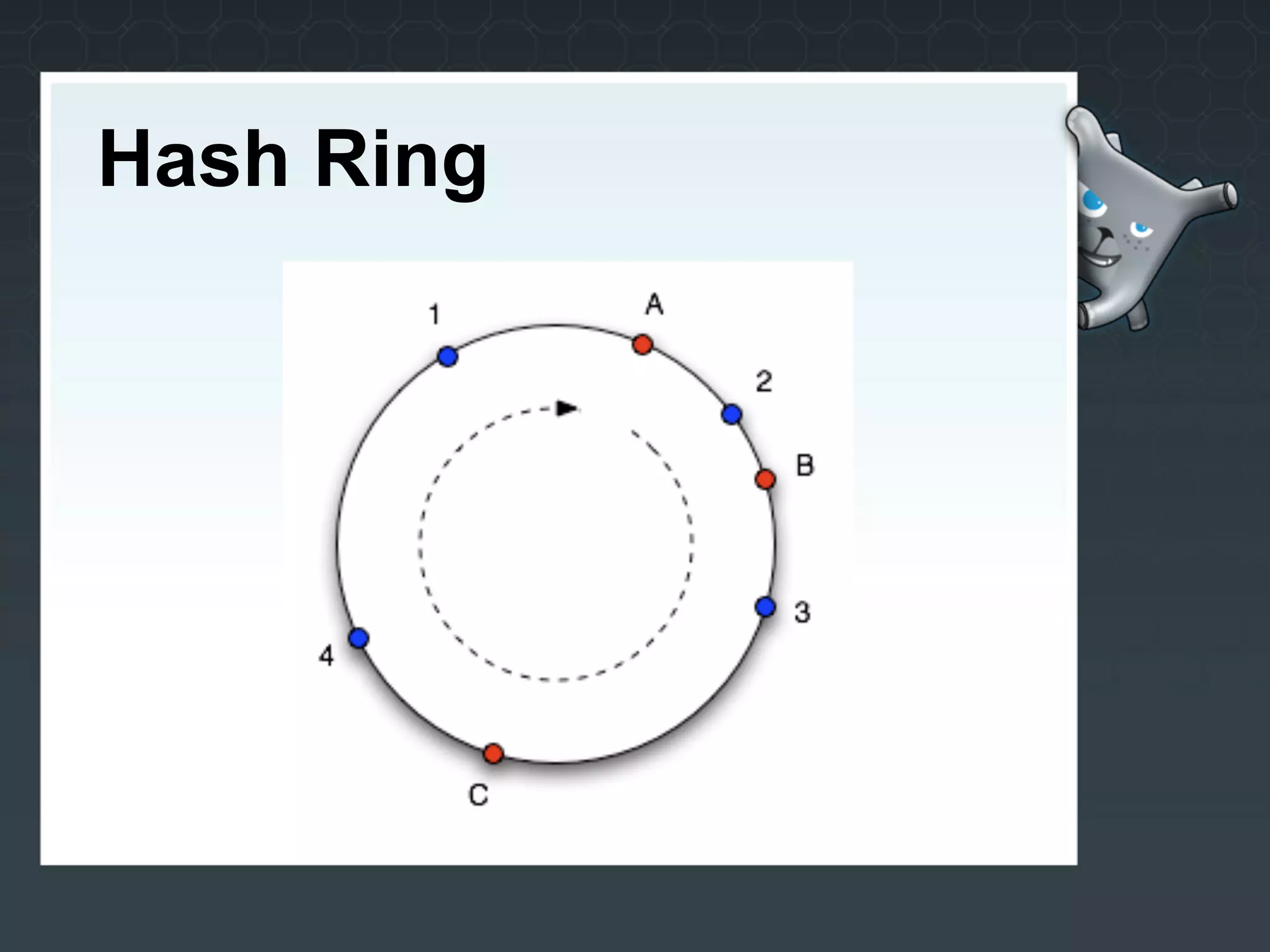













































The document discusses key-value stores as options for scaling the backend of a Facebook game. It describes Redis, Cassandra, and Membase and evaluates them as potential solutions. Redis is selected for its simplicity and ability to handle the expected write-heavy workload using just one or two servers initially. The game has since launched and is performing well with the Redis implementation.



































































































