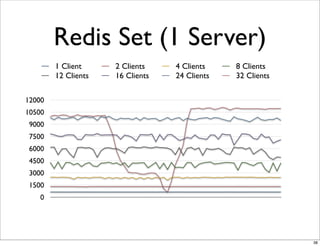
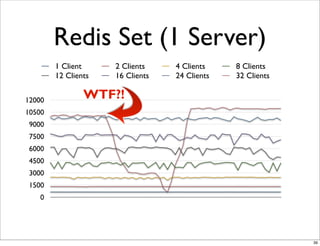
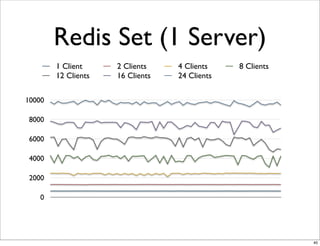
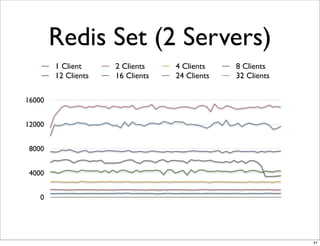
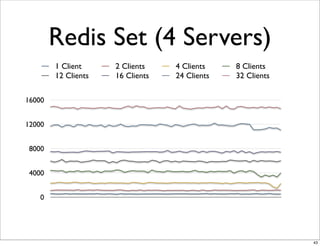
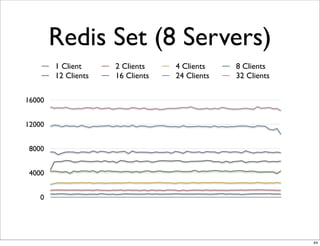
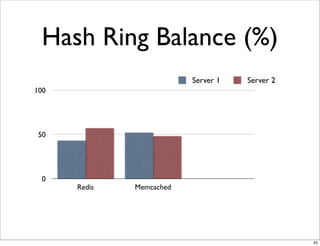
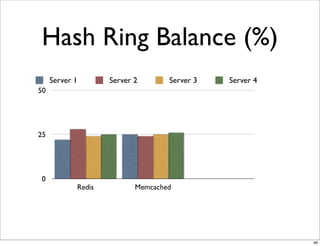
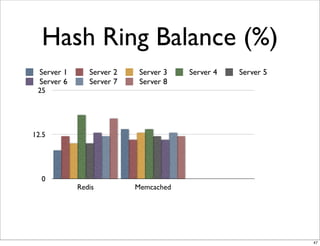
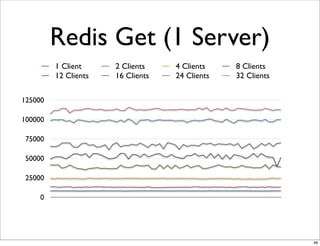
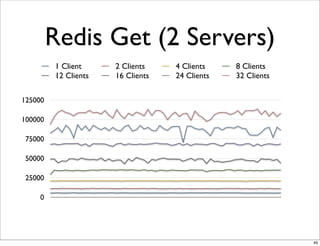
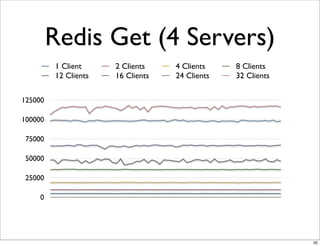
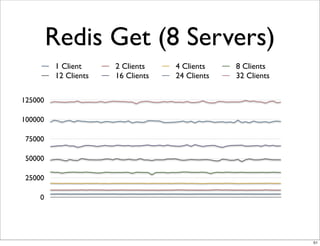
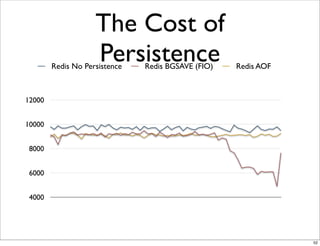
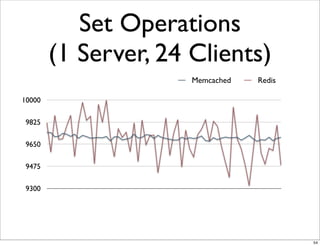
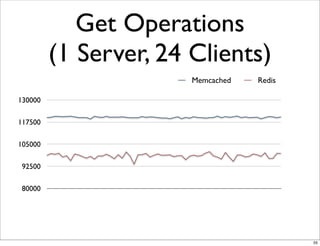
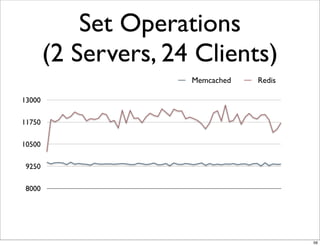
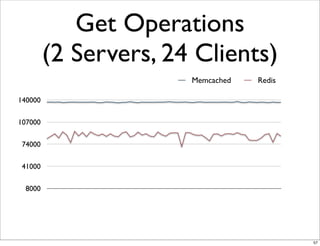
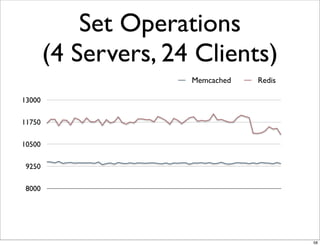
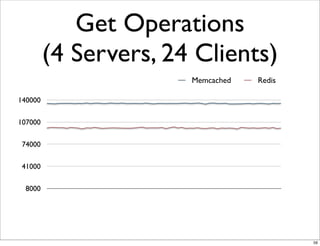
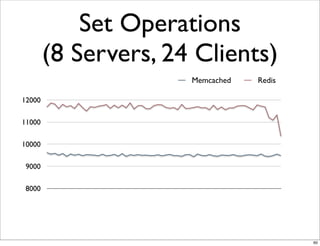
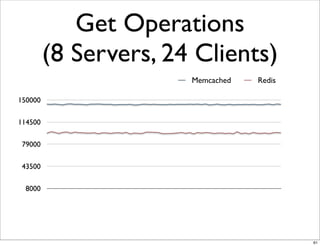
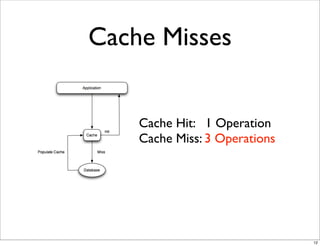
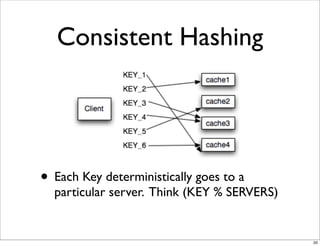
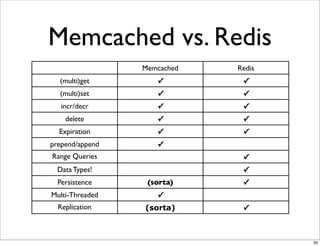
This document compares the caching technologies Memcached and Redis. It provides an overview of how caching works and the problems that can occur with caching like cache misses, stale data, and warm-up times. It details the features of Memcached and Redis, including their data structures and operations. Benchmarks are presented comparing the performance of Memcached and Redis for set and get operations with varying numbers of servers and clients. Redis performance degrades under heavy load due to its single-threaded architecture while Memcached scales better. The document concludes more benchmarks are needed to fully evaluate Redis.


















![Memcached Example
employee_id = 1234
employee_json = {
name => ‘Ryan Lowe’,
title => ‘Production Engineer’ }
set(employee_id, employee_json)
get(employee_id) [Returns employee_json]
22](https://image.slidesharecdn.com/redismemcachedpdf-120808142024-phpapp01/85/Redis-memcached-pdf-22-320.jpg)












![About the Benchmarks
• 1 Hour
• Redis 2.6 & Memcached 1.4.5
• 64,000,000 Keys
"KEY_#{i.to_s}"
• 51-Character Values
(0...50).map{ ('a'..'z').to_a[rand(26)] }.join
36](https://image.slidesharecdn.com/redismemcachedpdf-120808142024-phpapp01/85/Redis-memcached-pdf-36-320.jpg)