Download as PDF, PPTX



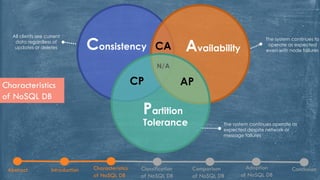
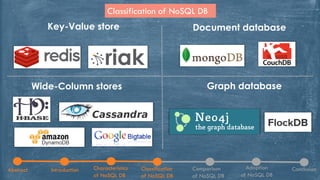

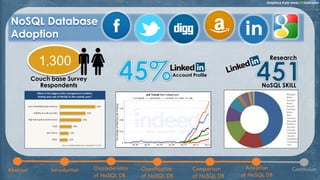



The document discusses NoSQL databases, highlighting their characteristics, classifications, and adoption in the context of big data analytics. It compares NoSQL with traditional SQL databases, noting the strengths and weaknesses of each approach. The paper concludes with insights into the benefits and features of NoSQL systems, including examples of various database types.























































































