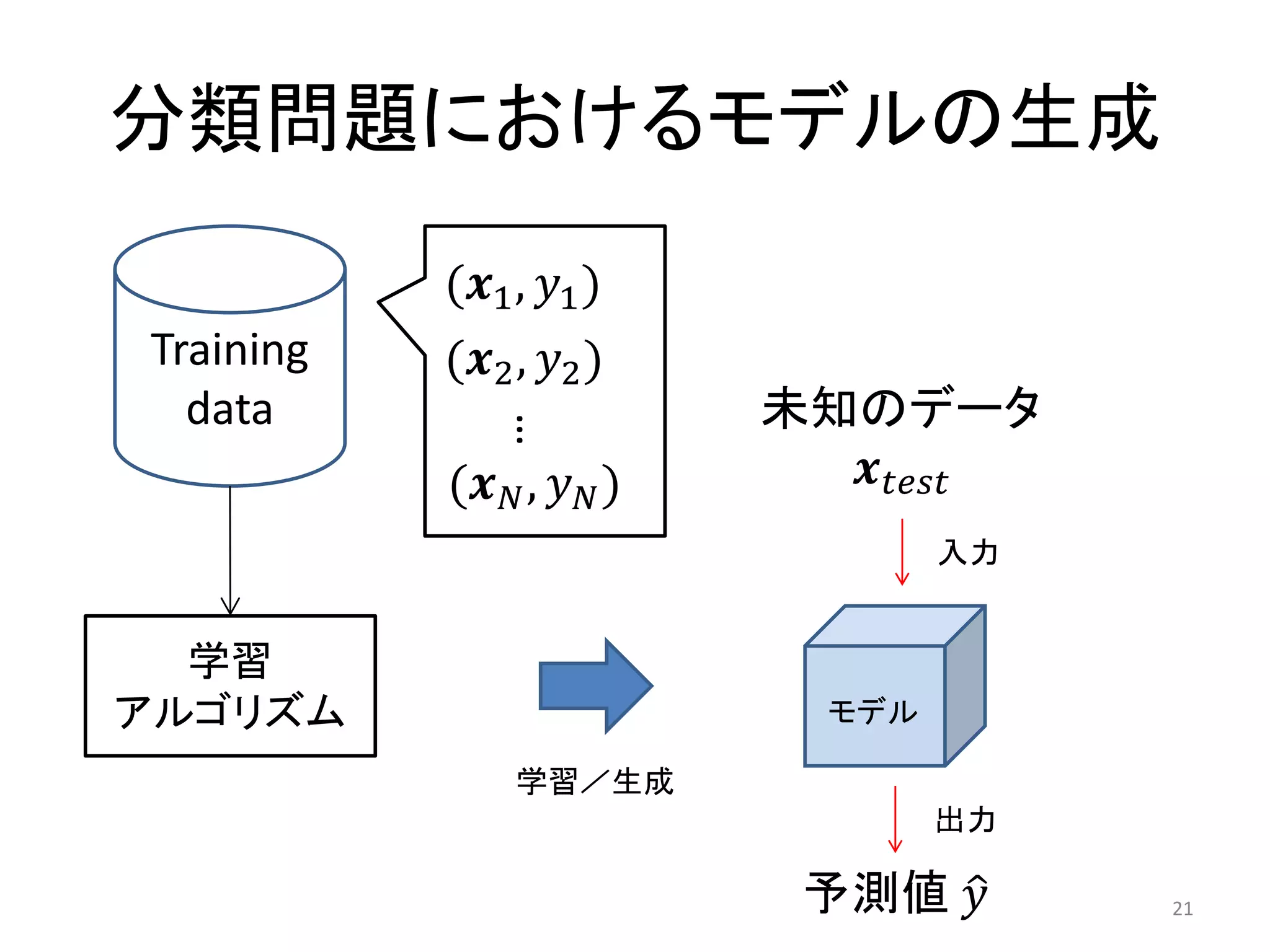
实装
• RankingSVM
– svm_rank by T. Joachims
• http://www.cs.cornell.edu/People/tj/svm_light/svm_rank.html
• Stochastic Pairwise Descent
– sofia-ml by D. Sculley
• http://code.google.com/p/sofia-ml/
91
92.
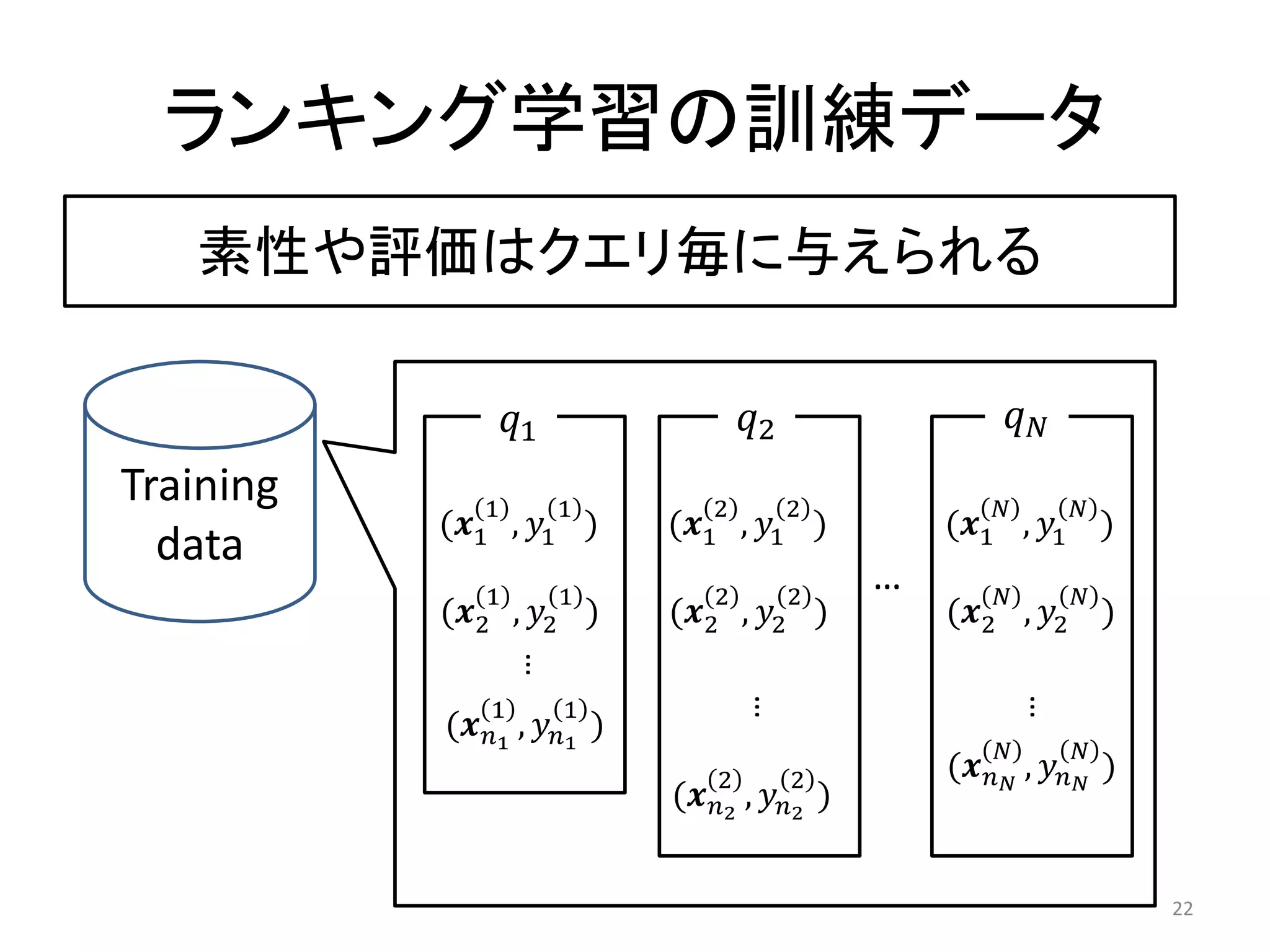
Learning to Rank教科書
•Tie-Yan Liu. Learning to Rank for Information Retrieval.
Springer (2011).
• Tie-Yan Liu. Learning to Rank for Information Retrieval
(Foundations and Trends(R) in Information Retrieval), Now
Publishers (2009)
• Hang Li, Learning to Rank for Information Retrieval and
Natural Language Processing, Morgan & Claypool (2011)
92
93.
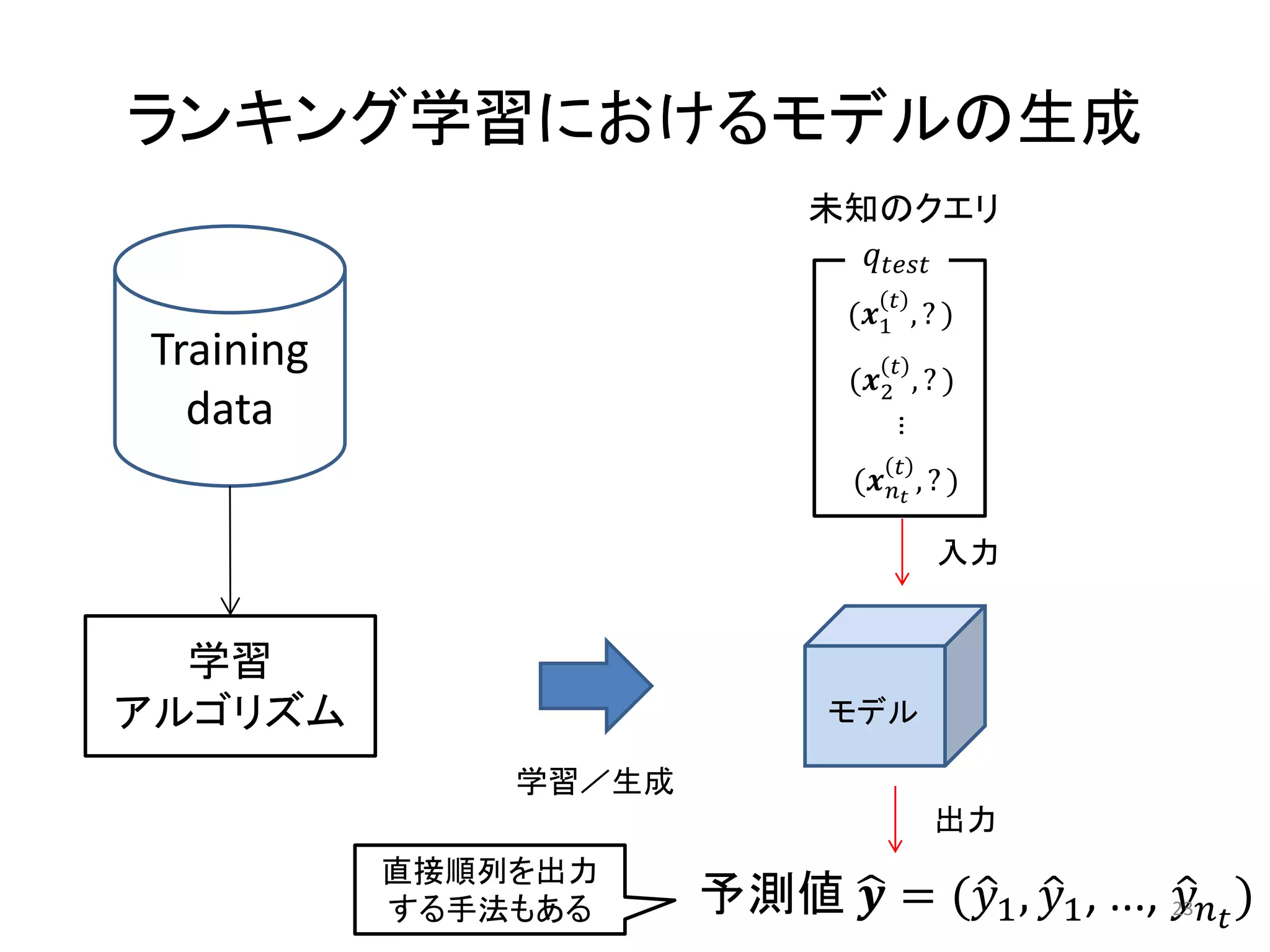
情報検索の教科書
• Christopher D. Manning, Prabhakar Raghavan, Hinrich Schuetze, “Introduction
to Information Retrieval”, Cambridge University Press (2008).
– Webで全ページ公開されている.情報検索全般的にバランスよく書かれている
• Bruce Croft, Donald Metzler, Trevor Strohman, “Search Engines: Information
Retrieval in Practice”, Pearson Education (2009).
– 検索エンジン寄りの話.エンジニア向けに書かれている.一番簡単かも.
• Stefan Buttcher, Charles L. A. Clarke and Gordon V. Cormack, “Information
Retrieval”, The MIT Press, 2010.
– 实装から理論まで王道を押さえてしっかり書かれている印象.特にお薦め.
93
94.
チュートリアル資料
• Tie YanLiu. Learning to Rank for Information Retrieval. SIGIR ‘08
Tutorial.
– http://research.microsoft.com/en-us/people/tyliu/letor-tutorial-
sigir08.pdf
• Hang Li. Learning to Rank. ACL-IJCNLP ‘09 Tutorial.
– http://research.microsoft.com/en-us/people/hangli/li-acl-ijcnlp-2009-
tutorial.pdf
• Shivani Agarwal. Ranking Methods in Machine Learning, SDM ’10
Tutorial.
– http://web.mit.edu/shivani/www/Events/SDM-10-Tutorial/sdm10-
tutorial.pdf
• 徳永拓之. Confidence Weightedでランク学習を实装してみた.
TokyoNLP#4 (2011).
– http://www.slideshare.net/tkng/confidence-weighted
94














![検索ランキングの評価方法
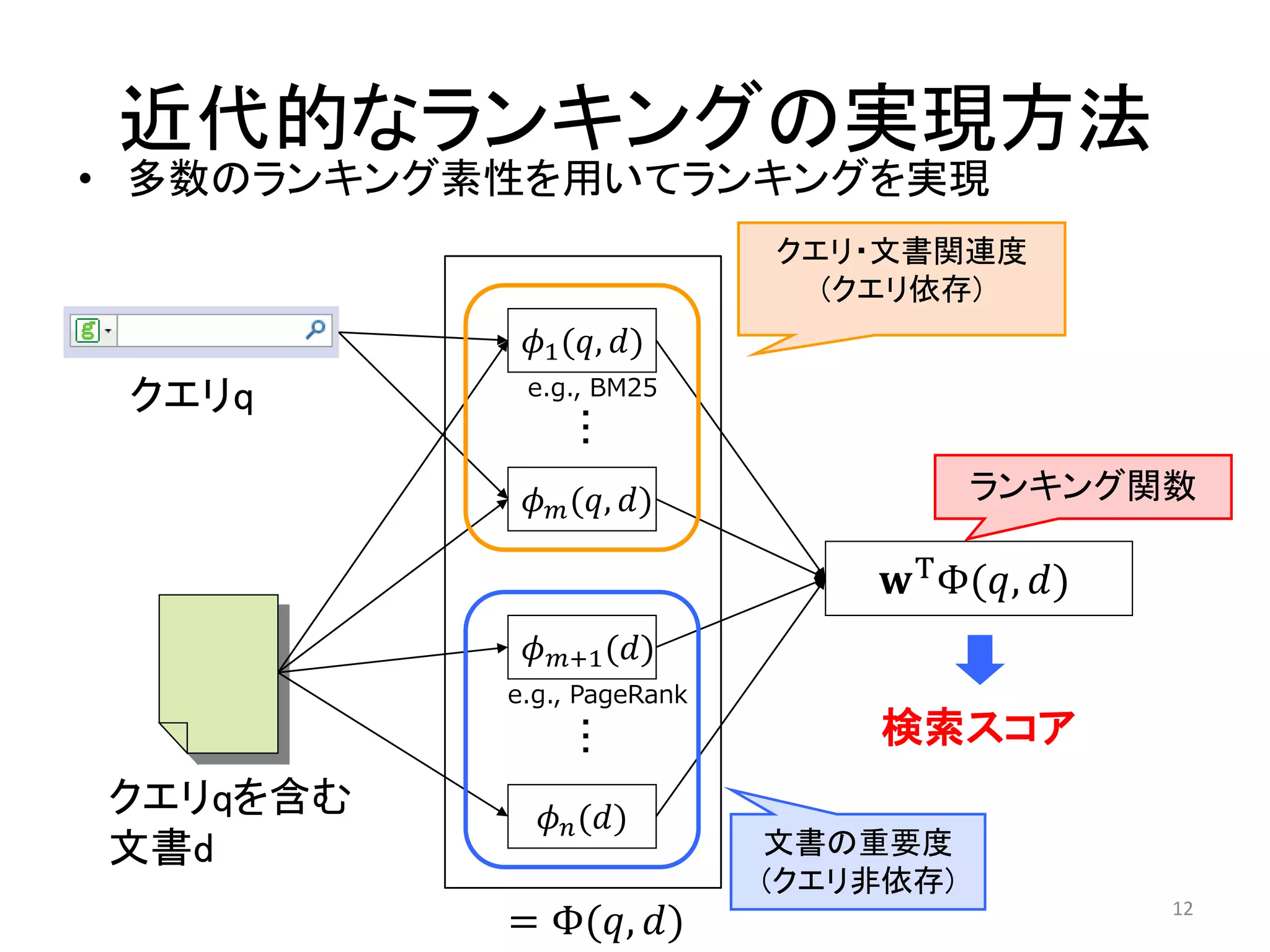
• 正解データとランキングを比較
• 検索結果上位を重視する評価指標
– (1) 順位kに高い点数>順位kに低い点数 分子
– (2) ランキング上位をより重視 分母
• NDCG (Normalized Discouted Cumulative Gain)
– 上記の2つを取り入れた多段階評価指標
– , : クエリqにおける順位iの評価点数
2, − 1
@ ≡
log 1 +
=1
@
@ ≡ (0,1]に正規化
@
19](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-19-2048.jpg)













![Discriminative Model for IR [Nallapati 04]
• 適合 (+1) / 非適合 (-1) の二値分類問題とし
て解く
– 通常の二値分類アルゴリズムが利用可能
1 2
Training
data (11 , 1 1 ) (12 , 1 2 ) (1 , 1 ) 適合
…
1
(2 , 2 )
1 2
(2 , 2 )
2
(2 , 2 )
非適合
…
(1 , 1 )
…
1 1 …
( , )
(2 , 2
2 2
)
39
[Nallapati 04] R. Nallapati. Discriminative Models for Information Retrieval. SIGIR ‘04, (2004).](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-39-2048.jpg)



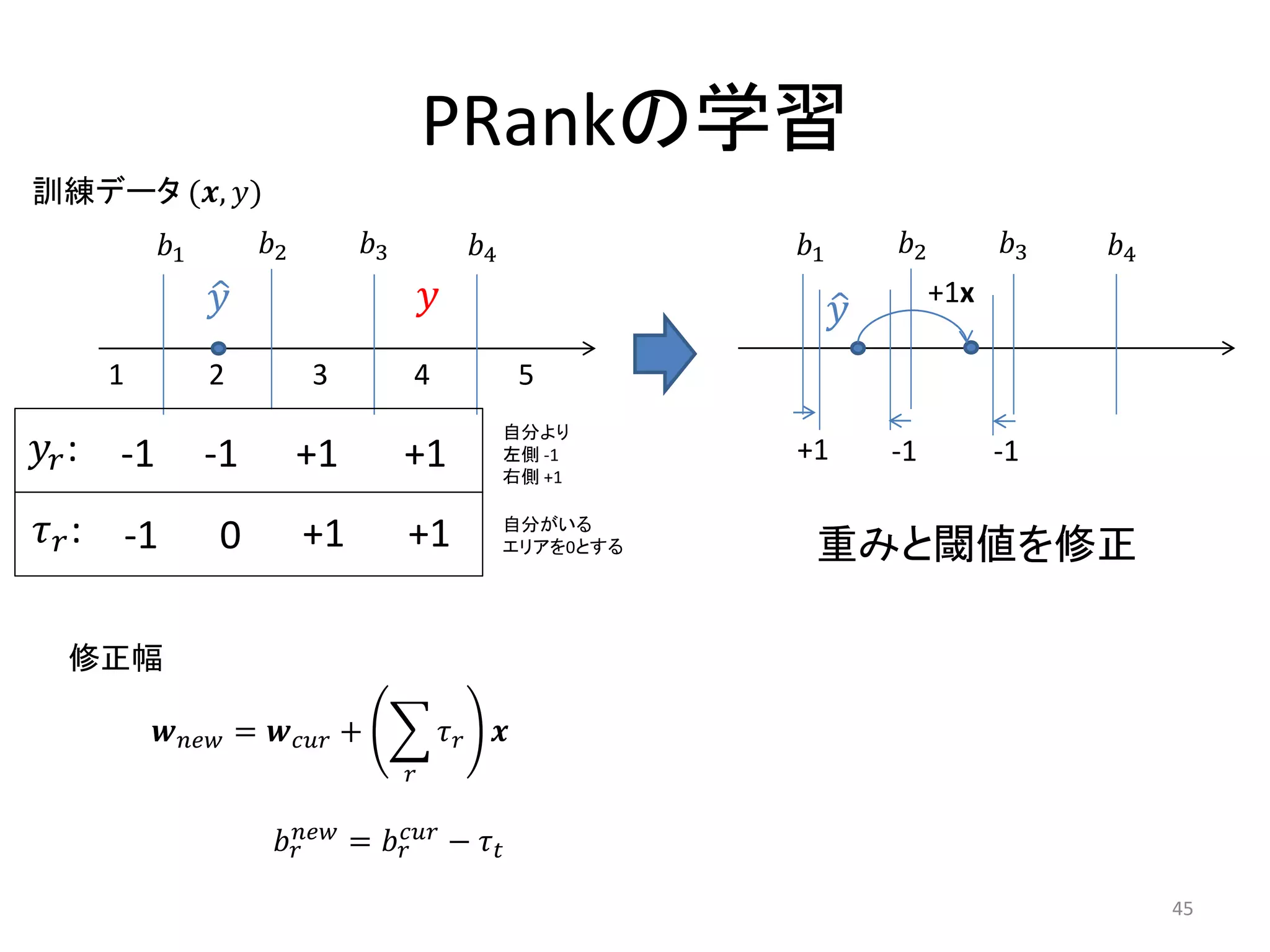
![PRank [Crammer+ 02]
• 順序を考慮した多値分類アルゴリズム
– 閾値を用いて離散値を出力
• モデル
– 線形モデル:
– 適合度レベルk個の閾値を用意
1 ≤ ⋯ ≤ −1 ≤ = ∞
– −1 < < のとき,と予測
= min *: − < 0+
∈*1,…+
• 学習方法
– Perceptronと同様に1サンプルずつ学習
– 誤った予測をした場合,重みと閾値の両方を修正
*Crammer+ 02+ K. Crammer and Y. Singer. Pranking with Ranking. NIPS ‘01, (2002) 44](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-44-2048.jpg)








![Stochastic Pairwise Descent [Sculley 09]
• ランダムランプリングした文書ペアに対して重み
更新を行う
– 更新手法はいろいろ
• SVM
• Passive-Aggressive
• Margin-Perceptron
• など
• 实装: sofia-ml
– http://code.google.com/p/sofia-ml/
54](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-54-2048.jpg)



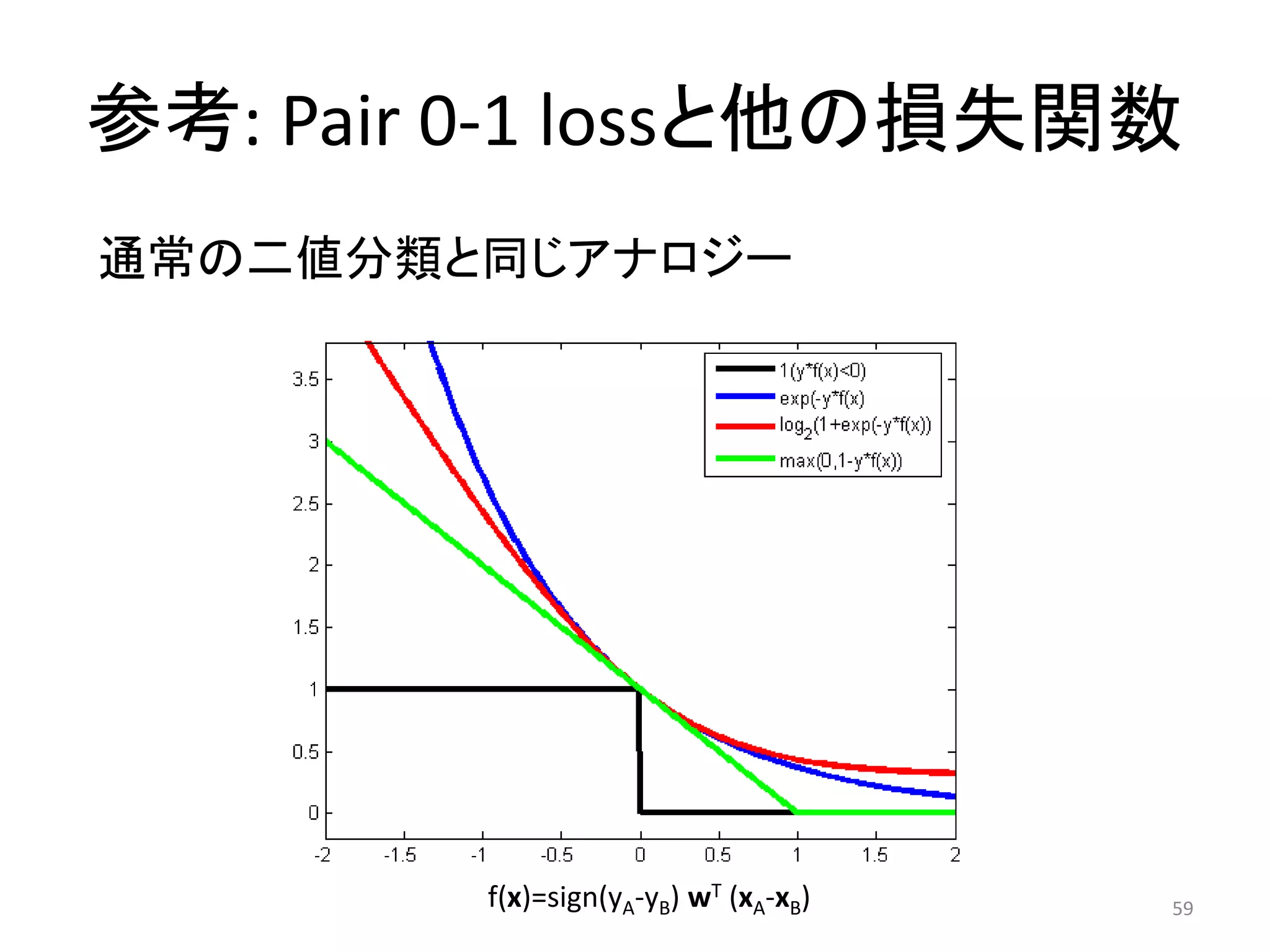
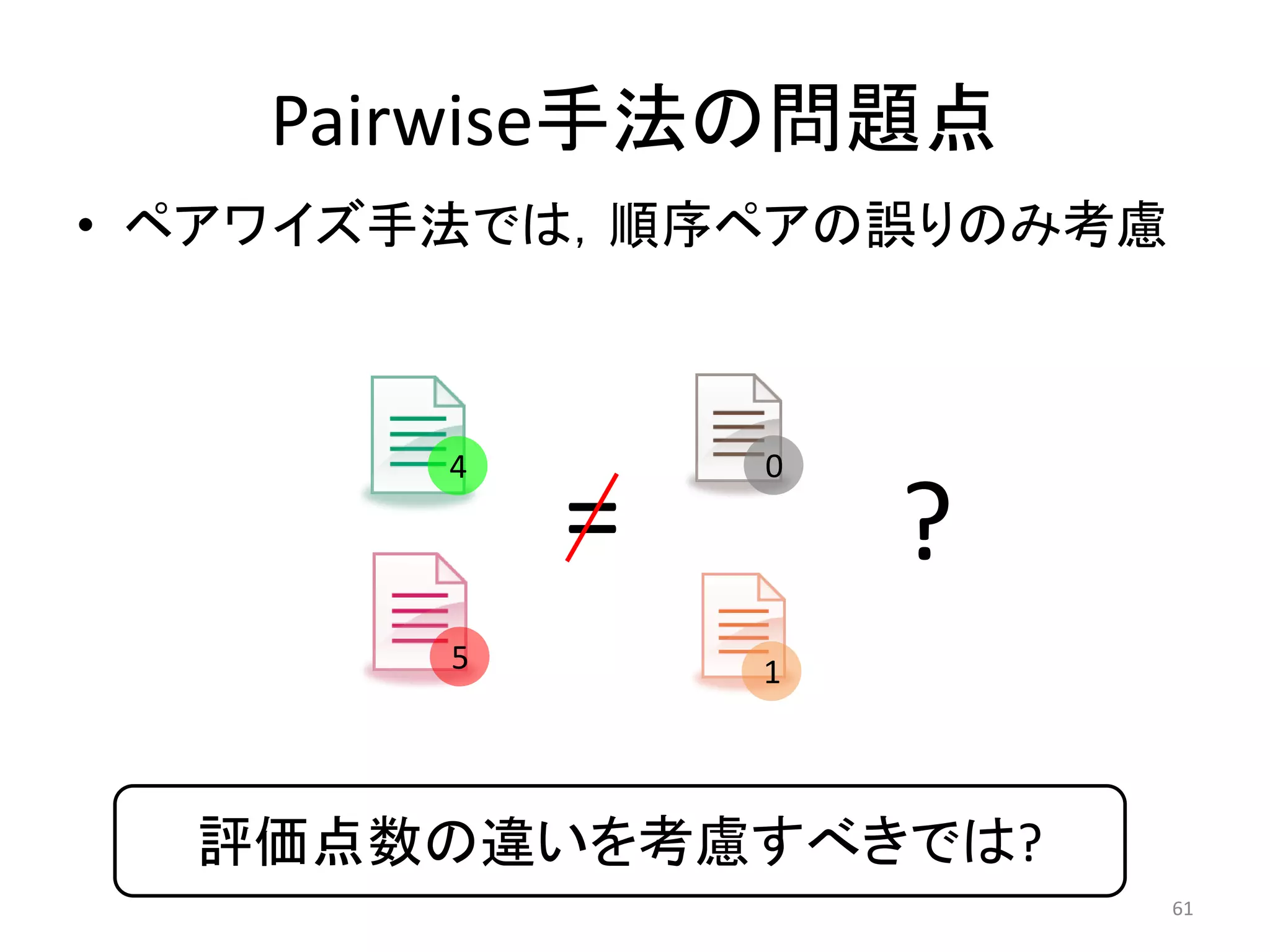
![Pairwise手法がやっていること
• ペア誤りの最小化 = Kendallの順位相関の最適化
(≠ 検索評価指標の最適化)
• Kendallの順位相関
– P: 順序が一致しているペアの数
2 2
Kendall = −1= −1
2
1/2 − 1
Pairwise損失は検索評価指標損失の
上界になってるで
[Chen+ 09] W. Chen, T.-Y. Liu, Y. Lan, Z. Ma, H. Li. Ranking Measures and Loss Functions in
58
Learning to Rank. NIPS ’09 (2009).](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-58-2048.jpg)
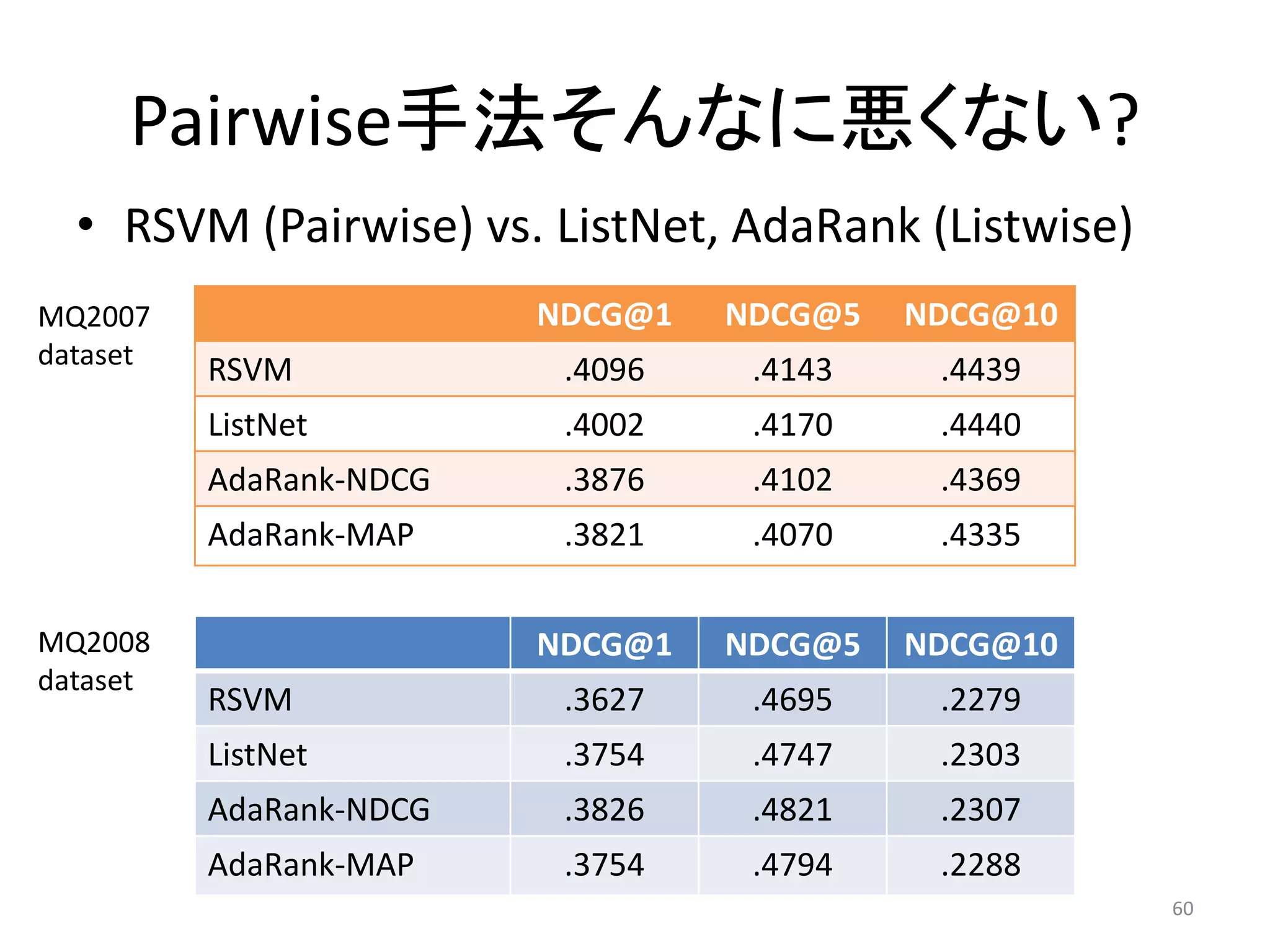
![IR-SVM [Cao+ 06]
• (1) ペア毎に異なる損失重みを利用
– 評価指標に影響を与えるペアの誤りに対して大きな
損失を与える (ヒンジロスの傾き)
• (2) クエリ毎のペアの偏りを排除
– 多くのペアを持つクエリに対して損失を小さくする
loss
62](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-62-2048.jpg)
![PARank (手前味噌) [数原+ 11]
• 重要度をマージンに反映
• PAで更新
2 (, )
○
重要度 ○ r=4
△
小 △ r=3
○
△ ○ □ r=2
□ ○ × r=1
△
重要度
□ △ 大
□
× Φ(q, d)
×
×
1 (, )
63
[数原+ 11] 数原, 鈴木, 安田, 小池, 片岡. 評価指標をマージンに反映したオンラインランキング学習. NLP2011.](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-63-2048.jpg)




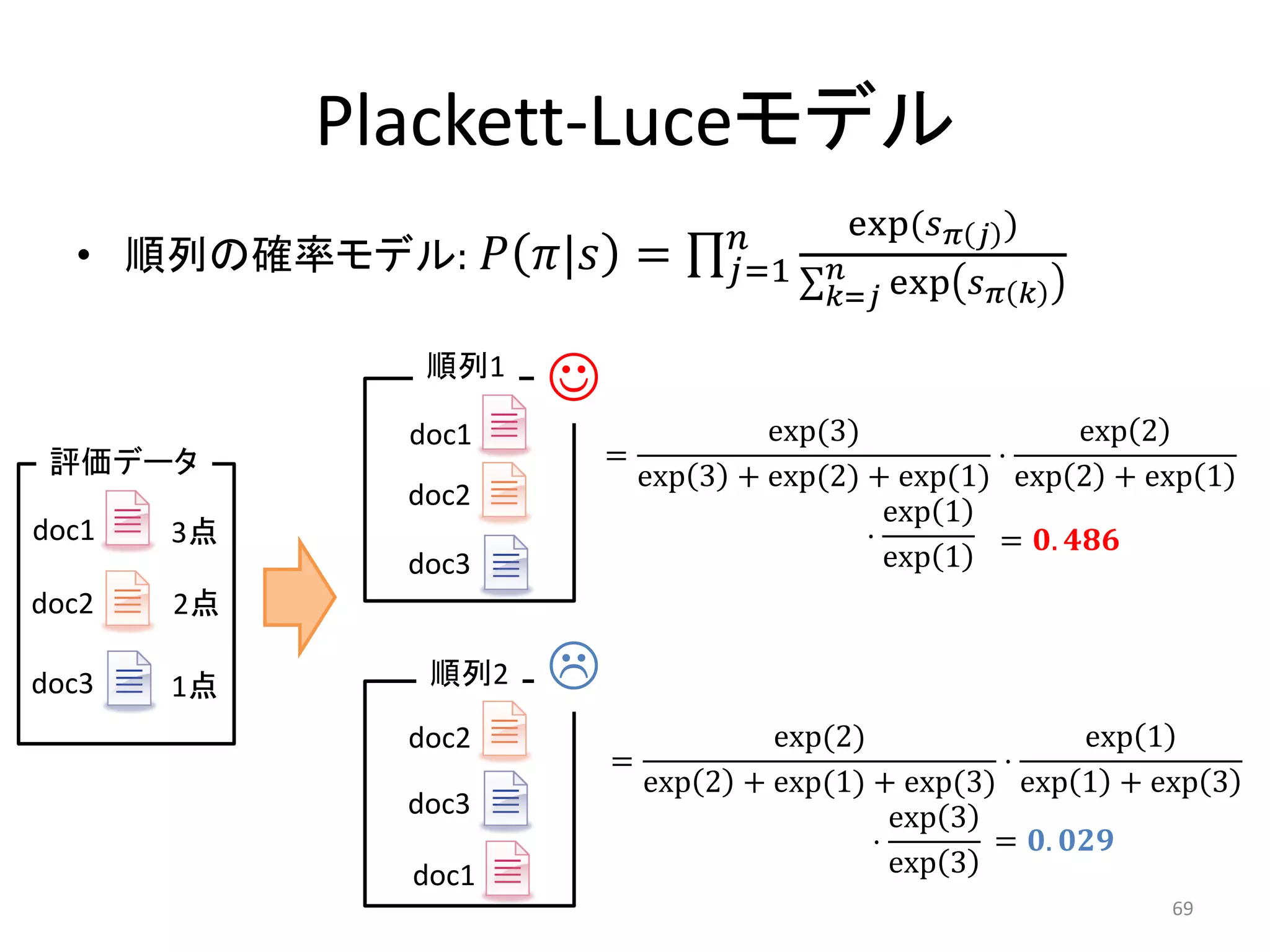
![ListNet [Cao+ 07]
• 今までペアを考慮
– Kendallの順位相関 ≠ 検索評価指標
• “順列 (リスト)”の観点で最適化をしたい
– 訓練データとモデルを順列の確率分布で表現し,
分布間の距離を最小化する
• 順列の確率分布にPlackett-Luceモデルを利用
• 分布間の距離はみんな大好きKL-divergenceを利用
[Cao+ 07] Z. Cao, T. Qin, T.-Y. Liu, M.-F. Tsai, H. Li. Learning to rank: from
pairwise approach to listwise approach. ICML ’07, (2007). 68](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-68-2048.jpg)
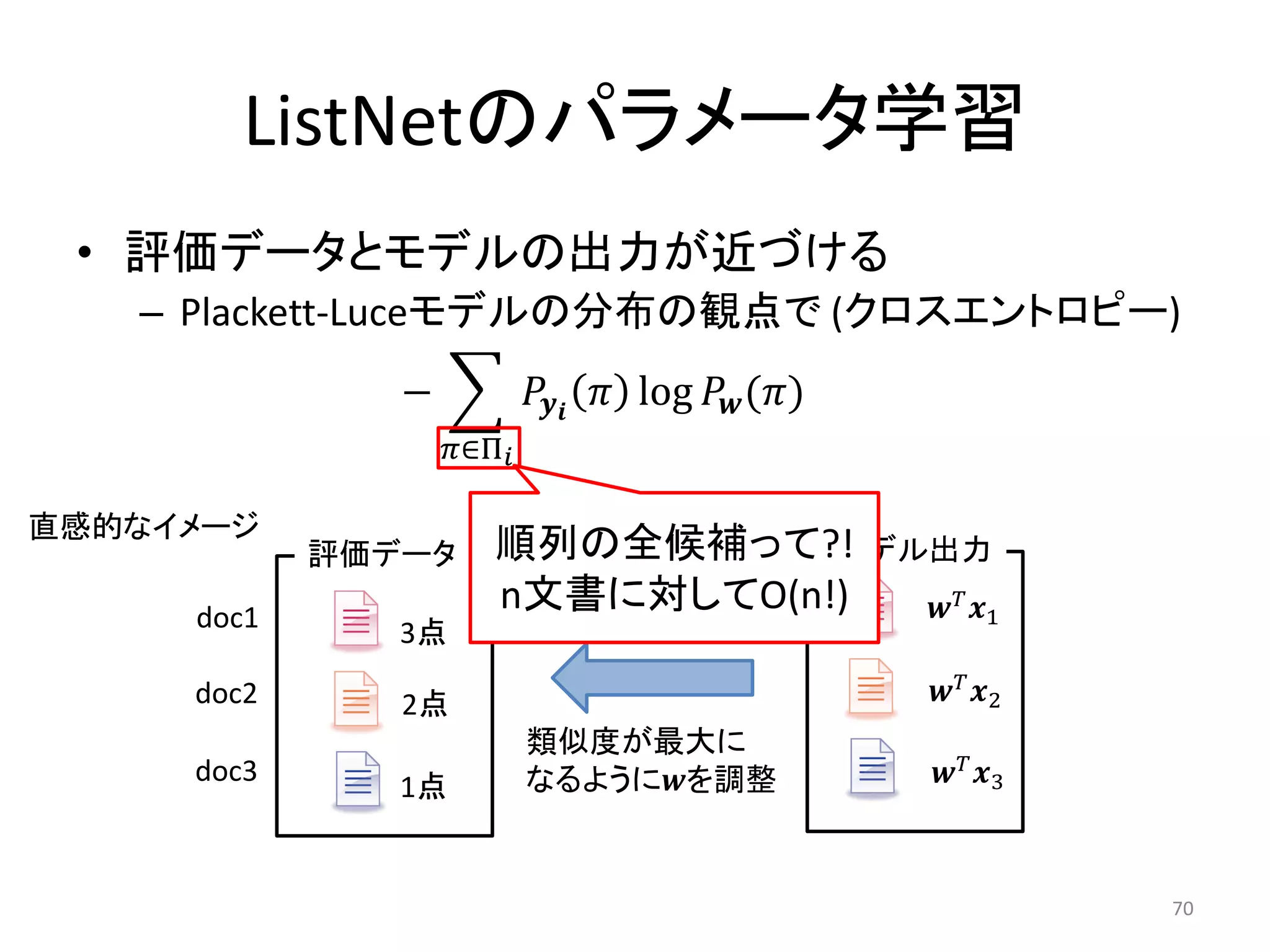
![計算の効率化
• 上位k件 (k=1) に対するPlackett-Luceモデル
の分布を計算 [Cao+ 08]
– k=1の際,クエリiのクロスエントロピーのに関す
る微分は以下のように求まる
,
1
=− +
exp( )
=1 =1 exp =1
71](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-71-2048.jpg)






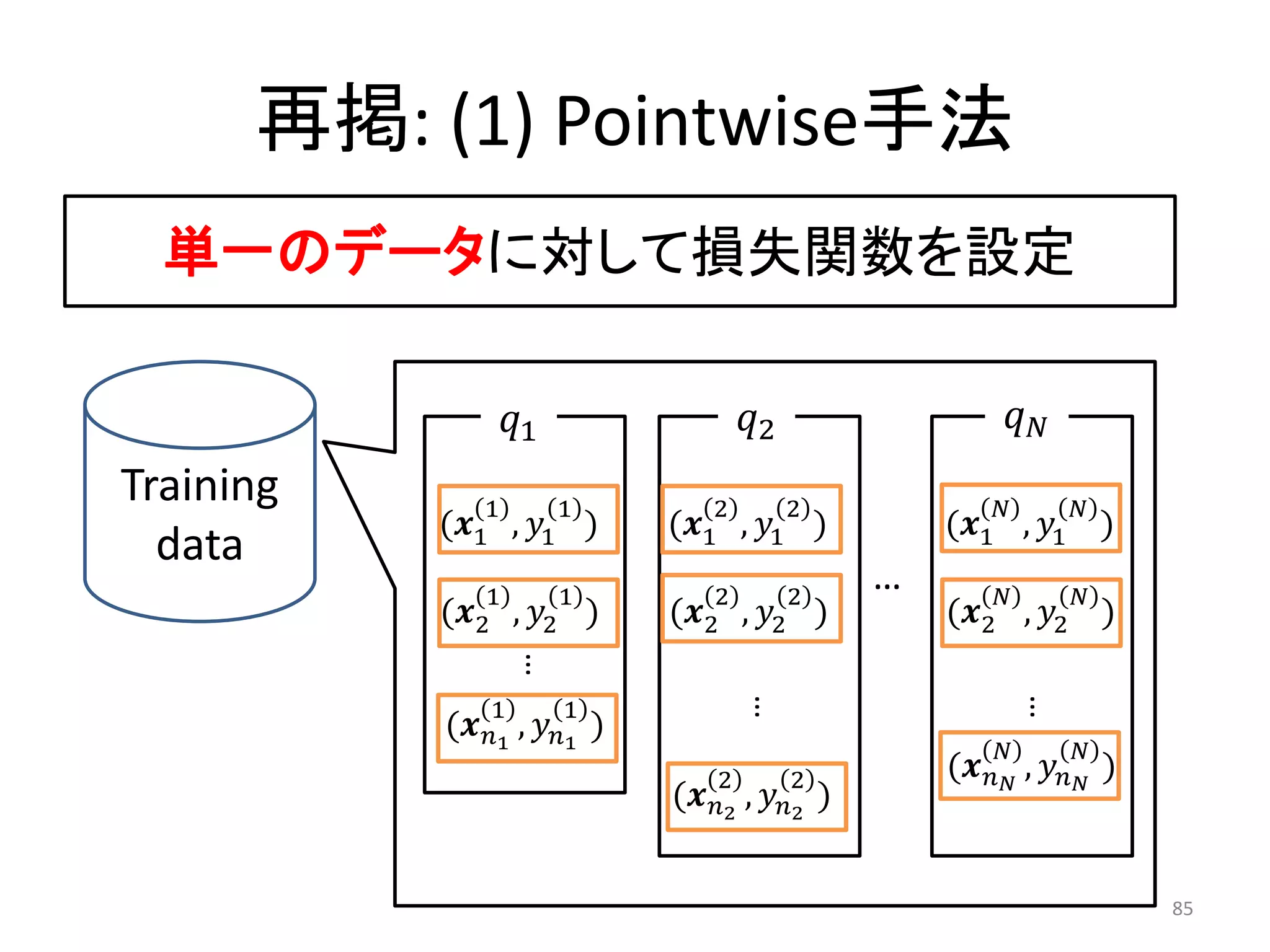
![再掲: 検索ランキングの評価方法
• 正解データとランキングを比較
• 検索結果上位を重視する評価指標
– (1) 順位kに高い点数>順位kに低い点数 分子
– (2) ランキング上位をより重視 分母
• NDCG (Normalized Discouted Cumulative Gain)
– 上記の2つを取り入れた多段階評価指標
– , : クエリqにおける順位iの評価点数
2, − 1
@ ≡
log 1 +
=1
@
@ ≡ (0,1]に正規化
@
80](https://image.slidesharecdn.com/20110723dsirnlpsuharapublish-110723035312-phpapp01/75/DSIRNLP-1-80-2048.jpg)
























![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)












































































